文章目录
前言
本文是对数据清洗的简单学习。
本文使用的数据来源为:博雅读书社所提供的数据
一、数据清洗是什么?
数据清洗是指在数据分析或挖掘之前进行的,对原始数据进行预处理以确保数据质量高、准确性好的一系列操作。其目的是识别、修改或删除数据集中不准确、不完整、重复、有误或非法的记录,以提高后续分析和建模过程的效率和准确性。
数据清洗中可能包括以下几种情况:
1、缺失值处理:对缺失数据进行填充或删除操作,使得数据集中不存在缺失值。
2、异常值处理:对数据集中异常值进行判断和处理,以避免对后续分析产生影响。
3、重复值处理:删除数据集中的重复记录,避免造成冗余和浪费。
4、数据类型转换:将数据中的字符串等类型转换为数值类型,以便能够进行更多的统计分析。
5、数据归一化:将不同维度的数据进行标准化,以避免由于数据单位等差异导致的分析误差。
通过数据清洗,我们可以把原始数据中的噪声和冗余信息清除,提升数据质量,更好地完成后续的数据分析和建模任务。
二、重复值处理
import pandas as pd
raw = pd.read_excel("shops_nm.xlsx")
#判断有没有重复的数据行
duplicate_raw = raw[raw.duplicated() == True]
if len(duplicate_raw) == 0:
print("没有重复的数据行。")
else:
print(duplicate_raw)
#制造一个重复的行 iloc[] 方法按照行、列的顺序提取
#print(raw.iloc[0,:])
raw.iloc[1,:] = raw.iloc[0,:] #把第一行赋给第二行
duplicate_raw = raw[raw.duplicated() == True]
if len(duplicate_raw) == 0:
print("没有重复的数据行。")
else:
print(duplicate_raw)
#判断店名
duplicte_shop = raw['店名'][raw['店名'].duplicated()==True]
if len(duplicte_shop) == 0:
print("没有重复的数据行。")
else:
print(duplicte_shop)
#去除重复的 drop_duplicates()
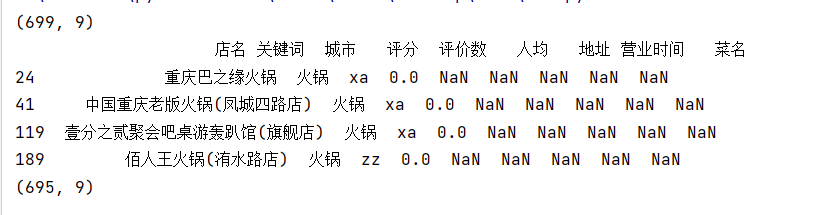
drop_duplicates_shops = raw.drop_duplicates(subset=['店名'])
print(drop_duplicates_shops.head())
程序的结果如图所示:

可以看到一开始是没有重复的数据行的,然后我就把第一行赋给了第二行,人为制造一个重复的数据行,然后找到这个重复的数据行,又找店名里面有没有重复的。最后是剔除重复的数据行。
三 缺失值处理
缺失值不一定指这个位置没有相应的数据,而是指这个位置填写的数据不能用,比如说一些不规范的填写也会造成缺失值。
import pandas as pd
raw = pd.read_excel("shops_nm.xlsx")
print(raw.shape)
#查找缺失值
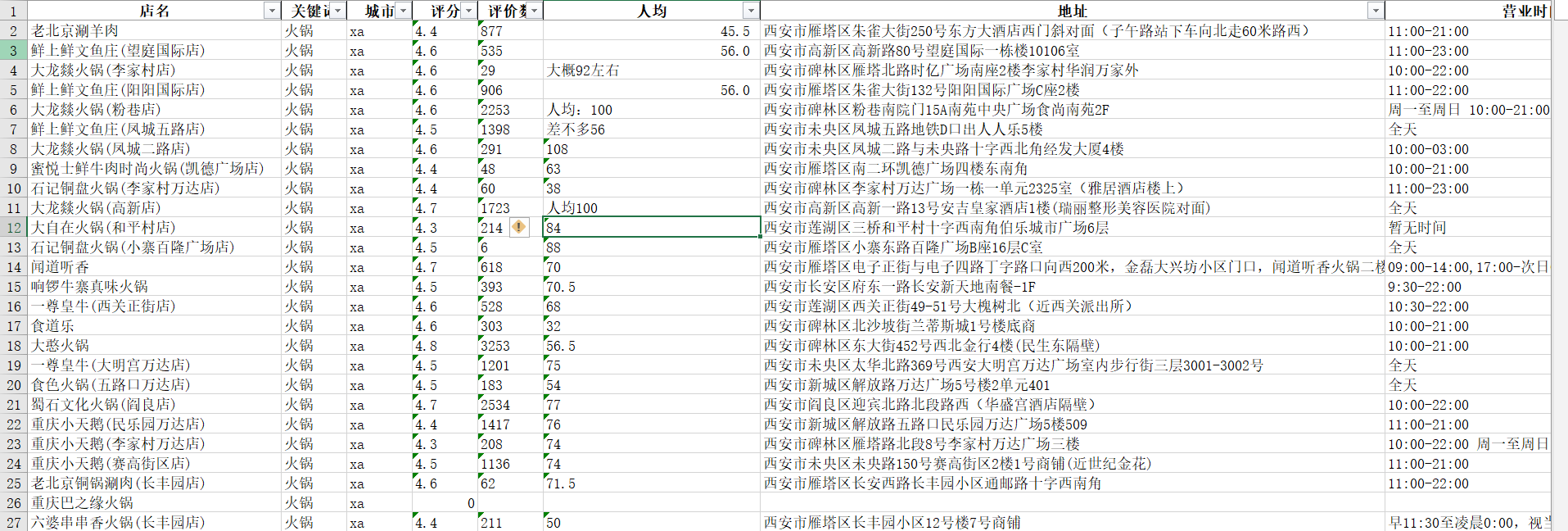
null_raw = raw[raw['评价数'].isnull() == True]
print(null_raw)
#剔除
raw1 = raw[raw['评价数'].isnull() == False]
print(raw1.shape)
效果图如下,可以看到剔除完的数据行数减少了4行
四、数据类型转换
数据类型转换是什么意思呢?为什么要进行数据类型转换?举个简单的例子:
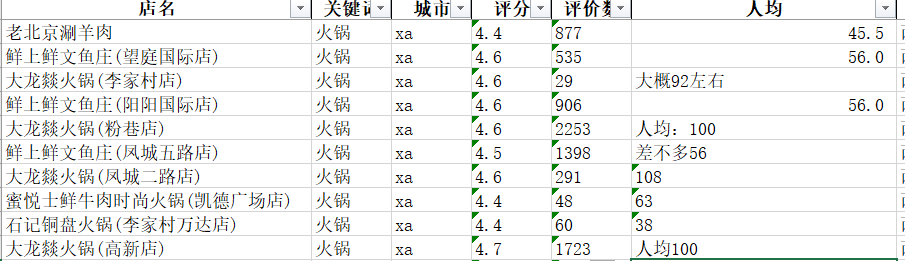
在图中人均的Series里面,可以看到,有些商家数据填写的不规范,本应该都是float类型,但是他里面会有汉字,这就涉及到数据类型的转换了,否则后面对数据进行处理的时候会出现很大的问题。
import pandas as pd
raw = pd.read_excel("shops_nm.xlsx")
print(len(raw))
#方法1:切片函数+for循环+if条件
filter_word = ["人均:","人均","大概","左右","差不多"]
for i in range(len(raw)):
value = raw.loc[i,'人均']
if type(value)== float or type(value)==int:
continue
for j in filter_word:
if j in value:
raw.loc[i,'人均']= raw.loc[i,'人均'].replace(j,'')
print(raw.head()['人均'])
结果如图所示:

可以看到,字符被清洗掉了,不过上面的方法还是不推荐使用的,有更高级的方法可以实现上面的功能:”apply()函数封装for循环+if条件判断“的方法。
#方法2:apply()+for+if
def clean_price(x):
filter_word = ["人均:", "人均", "大概", "左右", "差不多"]
if type(x) == float or type(x) == int:
return x
for j in filter_word:
if j in x:
x.replace(j,'')
return x
raw['人均']= raw['人均'].apply(clean_price)
print(raw.head()['人均'])
看上去一样,但是apply()的效率是for+if的5倍,如果数据量很大的话,差距就很明显了。