修改json数据然后写入json文件中
f = open('1234.json','r',encoding='utf-8') data = f.read() data1 = json.loads(data) data1['status'] = 1 f1 = open('1234.json','w',encoding='utf-8') json.dump(data1,f1)
hashlib md5值的用法
#加入下面这个就可以 password = input('请输入密码:') m = hashlib.md5() m.update(password.encode()) if m.hexdigest() == data1['password']: print('登录成功')
configparser模块
增删该查
#修改时区 default-time-zone = '+8:00' 为 校准的全球时间 +00:00 import configparser config = configparser.ConfigParser() config.read('my.cnf') print(config['mysqld']['default-time-zone'] ) #08:00 config.set('mysqld','default-time-zone','+00:00') config.write(open('my.cnf', "w")) print(config['mysqld']['default-time-zone'] ) #+00:00
删除
##删除 explicit_defaults_for_timestamp import configparser config = configparser.ConfigParser() config.read('my.cnf') config.remove_option('mysqld','explicit_defaults_for_timestamp') config.write(open('my.cnf', "w"))
##为DEFAULT增加一条 character-set-server = utf8 import configparser config = configparser.ConfigParser() config.read('my.cnf') config.set('DEFAULT','character-set-server','utf8') config.write(open('my.cnf', "w"))
13、logging模块
日志级别:DEBUG、INFO、WARNING、ERROR、CRITICAL。 debug是最低的内置级别,critical为最高
level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里。
import logging # logging.basicConfig(filename='example.log',level=logging.INFO) #换成INFO,则不会记录debug logging.basicConfig(filename='example.log',level=logging.DEBUG)#它会追加,不是覆盖 logging.debug('This message should go to the log file') logging.info('So should this') logging.warning('And this, too') example.log INFO:root:So should this WARNING:root:And this, too DEBUG:root:This message should go to the log file INFO:root:So should this WARNING:root:And this, too
自定义日志格式
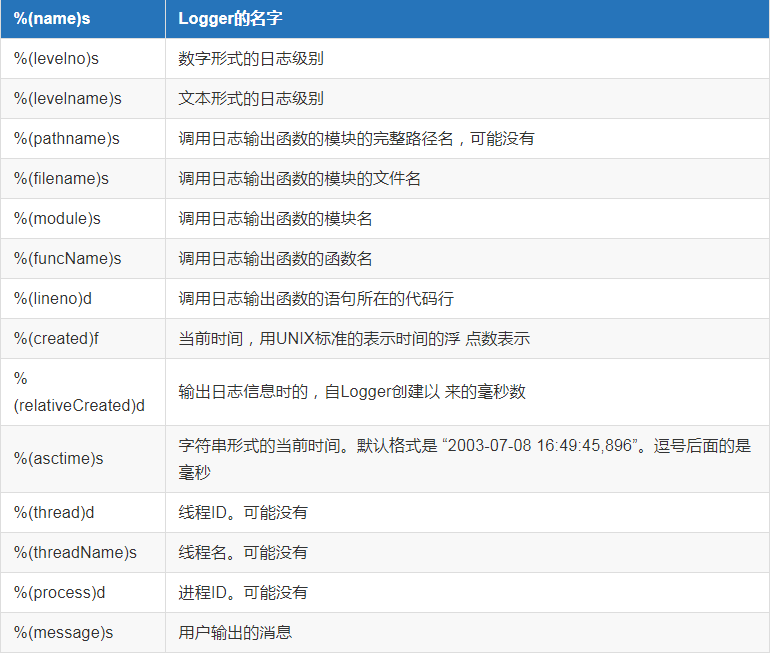
import logging logging.basicConfig(filename='example.log', level=logging.DEBUG, format='%(asctime)s:%(levelname)s:%(filename)s:%(funcName)s %(message)s', # %(asctime)s:是字符串形式的当前时间默认格式是 “2003-07-08 16:49:45,896”,逗号后面的是毫秒;%(levelname)s:文本形式的日志级别;%(funcName)s是函数的函数名; datefmt='%Y-%m-%d %I:%M:%S %p') def sayhi(): logging.error("from sayhi....") sayhi() logging.debug('This message should go to the log file') logging.info('So should this') logging.warning('And this, too')
INFO:root:So should this WARNING:root:And this, too DEBUG:root:This message should go to the log file INFO:root:So should this WARNING:root:And this, too 03/22/2018 11:54:58 PM This message should go to the log file 03/22/2018 11:54:58 PM So should this 03/22/2018 11:54:58 PM And this, too 2018-03-22 11:56:37 PM This message should go to the log file 2018-03-22 11:56:37 PM So should this 2018-03-22 11:56:37 PM And this, too 2018-03-22 11:58:08 PM-10- This message should go to the log file 2018-03-22 11:58:08 PM-20- So should this 2018-03-22 11:58:08 PM-30- And this, too 2018-03-23 12:02:08 AM:DEBUG:C:/Users/Administrator/PycharmProjects/myFirstpro/chapter4ģ���ѧϰ/logging_mode.py This message should go to the log file 2018-03-23 12:02:08 AM:INFO:C:/Users/Administrator/PycharmProjects/myFirstpro/chapter4ģ���ѧϰ/logging_mode.py So should this 2018-03-23 12:02:08 AM:WARNING:C:/Users/Administrator/PycharmProjects/myFirstpro/chapter4ģ���ѧϰ/logging_mode.py And this, too 2018-03-23 12:05:42 AM:DEBUG:logging_mode.py:logging_mode This message should go to the log file 2018-03-23 12:05:42 AM:INFO:logging_mode.py:logging_mode So should this 2018-03-23 12:05:42 AM:WARNING:logging_mode.py:logging_mode And this, too 2018-03-23 12:06:04 AM:ERROR:logging_mode.py:logging_mode from sayhi.... 2018-03-23 12:06:04 AM:DEBUG:logging_mode.py:logging_mode This message should go to the log file 2018-03-23 12:06:04 AM:INFO:logging_mode.py:logging_mode So should this 2018-03-23 12:06:04 AM:WARNING:logging_mode.py:logging_mode And this, too 2018-03-23 12:07:12 AM:ERROR:logging_mode.py:sayhi from sayhi.... 2018-03-23 12:07:12 AM:DEBUG:logging_mode.py:<module> This message should go to the log file 2018-03-23 12:07:12 AM:INFO:logging_mode.py:<module> So should this 2018-03-23 12:07:12 AM:WARNING:logging_mode.py:<module> And this, too
日志同时输出到屏幕和文件
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
- logger提供了应用程序可以直接使用的接口;
- handler将(logger创建的)日志记录发送到合适的目的输出;
- filter提供了细度设备来决定输出哪条日志记录;
- formatter决定日志记录的最终输出格式。

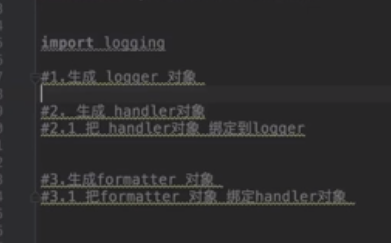
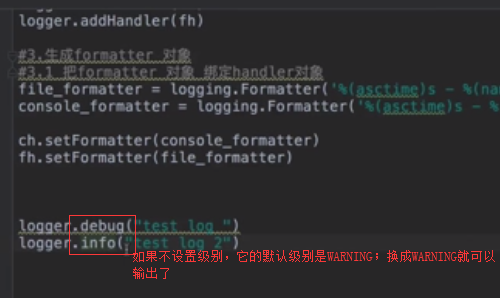
import logging #1.生成logger对象 logger =logging.getLogger("web") #web日志 logger.setLevel(logging.DEBUG) #####设置日志级别 ,这个是全局的;如果不设置默认的是WARNING #2.生成handler对象 ch = logging.StreamHandler() ch.setLevel(logging.INFO) ##设置输出屏幕级别 fh = logging.FileHandler("web.log") #生成文件 fh.setLevel(logging.WARNING) ##设置输出文件级别 #2.1把handler对象绑定到logger logger.addHandler(ch) logger.addHandler(fh) #3.生成formatter对象 #3.1把formatter对象绑定handler对象 file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s- %(lineno)d- %(message)s') ch.setFormatter(console_formatter) fh.setFormatter(file_formatter) logger.warning("test log") logger.info("test log 2") logger.debug("test log 3") #console(屏幕):INFO ##屏幕的 #global(全局):DEBUG default level :warning(全局的默认级别是WARNING) #file(文件):warning #全局设置为DEBUG后,console handler设置为INFO,如果输出的日志级别是debug,那就不会在屏幕上打印; 级别bebug < info < warning < error < critical #相当于全局是个漏斗,先把日志交给全局,然后再给下面的子handler
console输出:##全局是DEBUG,console是INFO 2018-06-11 15:54:50,413 - web - WARNING - 57 - test log 2018-06-11 15:54:50,413 - web - INFO - 58 - test log 2 日志输出: #日志是WARNING 2018-06-11 15:54:50,413 - web - WARNING - test log
过滤 filter组件
如果你想对日志内容进行过滤,就可自定义一个filter;
注意filter函数会返加True or False,logger根据此值决定是否输出此日志
然后把这个filter添加到logger中; logger.addFilter(IgnoreBackupLogFilter())
import logging class IgnoreBackupLogFilter(logging.Filter): """忽略带db backup 的日志""" def filter(self, record): #固定写法; 把日志对象传进来。 return "db backup" not in record.getMessage() #它不在就会返回; "db backup" not in "test log" 就返回true; "db backup" not in "test log db backup"就返回false #1.生成logger对象 logger =logging.getLogger("web") logger.setLevel(logging.DEBUG) #设置下级别 #这个是全局的 #1.1把filter对象添加到logger中 logger.addFilter(IgnoreBackupLogFilter()) #这样就支持过滤了 # #2.生成handler对象 ch = logging.StreamHandler() fh = logging.FileHandler("web.log") # #2.1把handler对象绑定到logger logger.addHandler(ch) logger.addHandler(fh) # #3.生成formatter对象 # #3.1把formatter对象绑定handler对象 file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s- %(lineno)d- %(message)s') ch.setFormatter(console_formatter) fh.setFormatter(file_formatter) logger.warning("test log") logger.info("test log 2") logger.debug("test log 3") logger.debug("test log db backup 3")
#屏幕上输出 db backup 3不在里边就返回true 然后就把它过滤掉 2018-06-11 16:22:04,120 - web - WARNING- 89- test log 2018-06-11 16:22:04,120 - web - INFO- 90- test log 2 2018-06-11 16:22:04,120 - web - DEBUG- 91- test log 3 文件里边输出: 2018-06-11 16:22:04,120 - web - WARNING - test log 2018-06-11 16:22:04,120 - web - INFO - test log 2 2018-06-11 16:22:04,120 - web - DEBUG - test log 3
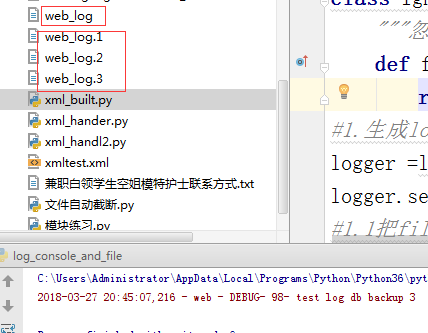
文件自动截断
按大小 制定了3个,再多了就会把最后边的给删了
import logging from logging import handlers class IgnoreBackupLogFilter(logging.Filter): """忽略带db backup 的日志""" def filter(self, record): #固定写法 return "db backup" in record.getMessage() # #1.生成logger对象 logger =logging.getLogger("web") logger.setLevel(logging.DEBUG) #设置下级别 #这个是全局的 #1.1把filter对象添加到logger中 logger.addFilter(IgnoreBackupLogFilter()) #这样就支持过滤了 # #2.生成handler对象 ch = logging.StreamHandler() fh = handlers.RotatingFileHandler("web_log",maxBytes=10,backupCount=3)#按照大小 #fh = handlers.TimedRotatingFileHandler("web_log",when="S",interval=5,backupCount=3) ##按照时间 # #2.1把handler对象绑定到logger logger.addHandler(ch) logger.addHandler(fh) # #3.生成formatter对象 # #3.1把formatter对象绑定handler对象 file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s- %(lineno)d- %(message)s') ch.setFormatter(console_formatter) fh.setFormatter(file_formatter) logger.warning("test log") logger.info("test log 2") logger.debug("test log 3") logger.debug("test log db backup 3")
14、re正则表达式
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是re
####文件 姓名 地区 身高 体重 电话 况咏蜜 北京 171 48 13651054608 王心颜 上海 169 46 13813234424 马纤羽 深圳 173 50 13744234523 乔亦菲 广州 172 52 15823423525 罗梦竹 北京 175 49 18623423421 刘诺涵 北京 170 48 18623423765 岳妮妮 深圳 177 54 18835324553 贺婉萱 深圳 174 52 18933434452 叶梓萱 上海 171 49 18042432324 杜姗姗 北京 167 49 13324523342 ############ f = open("兼职白领学生空姐模特护士联系方式.txt",'r',encoding="utf-8") phones = [] for line in f: name,city,height,weight,phone = line.split() if phone.startswith('1') and len(phone) == 11: phones.append(phone) print(phones)
import re f = open("兼职白领学生空姐模特护士联系方式.txt",'r',encoding="utf-8") data = f.read() phones = re.findall("1[0-9]{10}",data) print(phones)
re.match(从头开始匹配);re.search(全局匹配); re.findall()没有索引,有几个找几个;
>>> import re >>> s = 'abc1d3e' >>> re.match('[0-9]',s) >>> print(re.match('[0-9]',s)) None >>> re.match('[0-9]','1bdfd') #只匹配一个,开头的; <_sre.SRE_Match object; span=(0, 1), match='1'>
>>> s 'abc1d3e' >>> re.search('[0-9]',s) #只匹配一个,全局查找; <_sre.SRE_Match object; span=(3, 4), match='1'>
import re s = 'abc1d3e' match_res = re.search('[0-9]',s) if match_res: #先要判断是否为None print(match_res.group()) #拿到匹配结果
>>> s 'abc1d3e' >>> re.findall('[0-9]',s) #没有索引 ['1', '3']
compile()
re.compile()编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。)
格式:re.compile(pattern,flags=0) pattern: 编译时用的表达式字符串。flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。
import re tt = "Tina is a good girl, she is cool, clever, and so on..." rr = re.compile(r'\w*oo\w*') print(rr.findall(tt)) #查找所有包含'oo'的单词 执行结果如下: ['good', 'cool']
常用的表达式规则
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) '$' 匹配字符结尾, 若指定flags MULTILINE ,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到foo1 '*' 匹配*号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa' '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] '?' 匹配前一个字符1次或0次 ,re.search('b?','alex').group() 匹配b 0次 '{m}' 匹配前一个字符m次 ,re.search('b{3}','alexbbbs').group() 匹配到'bbb' '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' '(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45' '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,相当于re.match('abc',"alexabc") 或^ '\Z' 匹配字符结尾,同$ '\d' 匹配数字0-9 '\D' 匹配非数字 '\w' 匹配[A-Za-z0-9] '\W' 匹配非[A-Za-z0-9] 's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city")
结果{'province': '3714', 'city': '81', 'birthday': '1993'}
'.'匹配除\n以外的任意一个字符(第一个) ' ^ ' (以.....开头)
>>> s 'abc1d3e' >>> re.search('.',s) <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('.','*abd2') <_sre.SRE_Match object; span=(0, 1), match='*'> >>> re.search('..','*abd2') <_sre.SRE_Match object; span=(0, 2), match='*a'>
>>> re.search('^a','abc') <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('^ab','abc') <_sre.SRE_Match object; span=(0, 2), match='ab'> >>> re.match('ab','abc') <_sre.SRE_Match object; span=(0, 2), match='ab'> #它俩相等一样
'$' 以...结尾; ‘*’ 匹配*前的字符0次或多次
>>> re.search('b$','acb') #以b结尾 <_sre.SRE_Match object; span=(2, 3), match='b'>
>>> re.search('a*','alex').group() #*前边字符0次或多次 'a' >>> re.search('a*','aaaalex').group() 'aaaa' >>> re.search('ab*','abbaaalex') <_sre.SRE_Match object; span=(0, 3), match='abb'> >>> re.search('ab*','aabbaaalex') <_sre.SRE_Match object; span=(0, 1), match='a'>
'a+'匹配+前一个字符1次或多次;
>>> re.search('a','abbaaalex') <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('a+','abbaaalex') <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('a+','aaab') <_sre.SRE_Match object; span=(0, 3), match='aaa'> >>> re.search('.+','aaabb') <_sre.SRE_Match object; span=(0, 5), match='aaabb'> >>> >>> re.search('ab+','aaabbbb') <_sre.SRE_Match object; span=(2, 7), match='abbbb'>
'?' 匹配前一个字符1次或0次;
>>> re.search('a?','aaabbb') #注意跟*的区别 <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('a?','ddd') <_sre.SRE_Match object; span=(0, 0), match=''>
{m} 匹配前一个字符m次; {n,m} 匹配前一个字符n到m次;
>>> re.search('a{2}','addad') >>> re.search('a{2}','addaaadt') <_sre.SRE_Match object; span=(3, 5), match='aa'> >>> re.search('.{2}','addaaad') <_sre.SRE_Match object; span=(0, 2), match='ad'> >>> re.search('[0-9]{2}','addaaad234')##必须是连着的两个数字,隔开的就不行 <_sre.SRE_Match object; span=(7, 9), match='23'> >>> re.search('[a-z]','alex') <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('[a-z]{2}','alex') <_sre.SRE_Match object; span=(0, 2), match='al'> >>> re.search('[a-z]{1,2}','alex') <_sre.SRE_Match object; span=(0, 2), match='al'> >>> re.search('[a-z]{1,2}','a2lex') <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('[a-z]{1,2}','2lex') #{1,2}表示1或者2 <_sre.SRE_Match object; span=(1, 3), match='le'> >>> re.search('[a-z]{1,10}','2lex') <_sre.SRE_Match object; span=(1, 4), match='lex'>
‘|’ 匹配|左或|右的字符
>>> re.search('alex|Alex','Alex') <_sre.SRE_Match object; span=(0, 4), match='Alex'> >>> re.search('a|Alex','alex') <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('[a|A]lex','alex') <_sre.SRE_Match object; span=(0, 4), match='alex'>
分组匹配
>>> re.search('[a-z]+[0-9]+' ,'alex123') #alex123,前面必须是以字母开头,不然就不行了,123alex就不会匹配了 <_sre.SRE_Match object; span=(0, 7), match='alex123'> >>> re.search('[a-z]+[0-9]+' ,'alex123').group() 'alex123' >>> >>> re.search('([a-z]+)([0-9]+)','alex123').groups()#必须是依次对应的,前面要先是字符才能是数字;换成123alex就不匹配了; ('alex', '123') #加s给分开了
re.search('^ab','abd') == re.match('ab','abd') == re.search('\Aab','alex')
>>> re.search('\Aalex','alex') <_sre.SRE_Match object; span=(0, 4), match='alex'>
'\A' 只从字符开头匹配;‘\d’ 匹配数字0-9; '\D' 匹配非数字;
>>> re.search('[0-9]','alex2') <_sre.SRE_Match object; span=(4, 5), match='2'> >>> re.search('\d','alex2') <_sre.SRE_Match object; span=(4, 5), match='2'> >>> re.search('\d+','alexa23456344') <_sre.SRE_Match object; span=(5, 13), match='23456344'> >>> re.search('\d+','alexa23456344f222') <_sre.SRE_Match object; span=(5, 13), match='23456344'>
'\w' 匹配[A-Za-z0-9] ;‘\W’ 匹配非[A-Za-z0-9]
>>> re.search('\D+','al^&$exa23456344f222') <_sre.SRE_Match object; span=(0, 8), match='al^&$exa'> >>> >>> >>> re.search('\w+','al^&$exa23456344f222') <_sre.SRE_Match object; span=(0, 2), match='al'> >>> re.search('\w+','alexa23456344f222') <_sre.SRE_Match object; span=(0, 17), match='alexa23456344f222'> >>> re.search('\W+','al^&$exa23456344f222') <_sre.SRE_Match object; span=(2, 5), match='^&$'>
'\s' 匹配空白字符、\t、\n、\r
>>> s = 'alex\njack' >>> s 'alex\njack' >>> print(s) alex jack >>> re.search('\s',s) <_sre.SRE_Match object; span=(4, 5), match='\n'> >>> re.search('\s','slex\njack\tdd\rmack') <_sre.SRE_Match object; span=(4, 5), match='\n'> >>> re.findall('\s','slex\njack\tdd\rmack') ['\n', '\t', '\r']
'(?P<name>...)' 分组匹配 >>> s '130704200005250613' >>> re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_city>\d{4})',s).groups () ('130', '704', '2000') >>> res.groupdict() {'province': '130', 'city': '704', 'born_city': '2000'}
split
>>> re.split <function split at 0x000000000297C730> >>> s = 'alex22jack23rain31jinxin50' >>> s.split() ['alex22jack23rain31jinxin50'] >>> re.split('\d',s) ['alex', '', 'jack', '', 'rain', '', 'jinxin', '', ''] >>> re.split('\d+',s) ['alex', 'jack', 'rain', 'jinxin', ''] >>> re.findall('\d+',s) ['22', '23', '31', '50']
>>> s = 'alex22jack23rain31jinxin50#mack-oldboy' >>> re.split('\d+|#|-',s) ['alex', 'jack', 'rain', 'jinxin', '', 'mack', 'oldboy'] >>> s = 'alex22jack23rain31jinxin50|mack-oldboy' >>> re.split('\|',s) #加一个\就不把它当做一个语法了,当做一个字符 ['alex22jack23rain31jinxin50', 'mack-oldboy'] >>> s = 'alex22jack23rain31\jinxin50|mack-oldboy' >>> s 'alex22jack23rain31\\jinxin50|mack-oldboy'>>> re.split('\\\\',s) #\特殊的转义字符,特殊匹配 ['alex22jack23rain31', 'jinxin50|mack-oldboy']
re.sub()用于替换匹配到的字符串; re.split() '\d'匹配数字0-9 '+' 匹配字符一次或多次
>>> s 'alex22jack23rain31\\jinxin50|mack-oldboy' >>> re.sub('\d+','_',s) 'alex_jack_rain_\\jinxin_|mack-oldboy' >>> re.sub('\d+','_',s,count=2) #加上count=2是匹配前边两个 'alex_jack_rain31\\jinxin50|mack-oldboy'
>>> s = '9-2*5/3+7/3*99/4*2998+10*568/14' >>> re.split('[-\*/+]',s) ['9', '2', '5', '3', '7', '3', '99', '4', '2998', '10', '568', '14'] >>> re.split('[-\*/+]',s,maxsplit=2) ['9', '2', '5/3+7/3*99/4*2998+10*568/14']
re.fullmatch() 整个字符串匹配成功就返回re object, 否则返回None
>>> re.fullmatch('alex123','alex123') <_sre.SRE_Match object; span=(0, 7), match='alex123'> >>> re.fullmatch('\w+@\w+\.(com|cn|edu)',"[email protected]") <_sre.SRE_Match object; span=(0, 17), match='[email protected]'>

标注符Flag
re.I忽略大小写;
>>> re.search('a','alex') <_sre.SRE_Match object; span=(0, 1), match='a'> >>> re.search('a','Alex',re.I) <_sre.SRE_Match object; span=(0, 1), match='A'>
re.M多行模式,改变'^' '$'的行为
>>> re.search('foo.$','foo1\nfoo2\n') #foo.$ 是以foo结尾后边任意再匹配一个字符; <_sre.SRE_Match object; span=(5, 9), match='foo2'> >>> re.search('foo.$','foo1\nfoo2\n',re.M) <_sre.SRE_Match object; span=(0, 4), match='foo1'>
re.S 改变‘.’匹配不到\n的行为。
>>> re.search('.','\n',re.S) #.匹配任意的一个字符,可以匹配到\n了 <_sre.SRE_Match object; span=(0, 1), match='\n'>
re.X是可以写注释:#注释
>>> re.search('. #test','alex',re.X) <_sre.SRE_Match object; span=(0, 1), match='a'>