机器学习HW10对抗性攻击
一、任务描述
我们使用pytorchcv来获得CIFAR-10预训练模型,所以我们需要首先设置环境。我们还需要下载我们想要攻击的数据(200张图片)。我们将首先通过ToTensor对原始像素值(0-255标度)应用变换(到0-1标度),然后归一化(减去均值除以标准差)。

# the mean and std are the calculated statistics from cifar_10 dataset
cifar_10_mean = (0.491, 0.482, 0.447) # mean for the three channels of cifar_10 images
cifar_10_std = (0.202, 0.199, 0.201) # std for the three channels of cifar_10 images
# convert mean and std to 3-dimensional tensors for future operations
mean = torch.tensor(cifar_10_mean).to(device).view(3, 1, 1)
std = torch.tensor(cifar_10_std).to(device).view(3, 1, 1)
epsilon = 8/255/std
ToTensor()还会将图像从形状(高度、宽度、通道)转换为形状(通道、高度、宽度),所以我们还需要将形状转置回原始形状。
由于我们的数据加载器对一批数据进行采样,所以我们这里需要使用np.transpose将(batch_size,channel,height,width)转置回(batch_size,height,width,channel)。
# perform adversarial attack and generate adversarial examples
def gen_adv_examples(model, loader, attack, loss_fn):
model.eval()
adv_names = []
train_acc, train_loss = 0.0, 0.0
for i, (x, y) in enumerate(loader):
x, y = x.to(device), y.to(device)
x_adv = attack(model, x, y, loss_fn) # obtain adversarial examples
yp = model(x_adv)
loss = loss_fn(yp, y)
train_acc += (yp.argmax(dim=1) == y).sum().item()
train_loss += loss.item() * x.shape[0]
# store adversarial examples
adv_ex = ((x_adv) * std + mean).clamp(0, 1) # to 0-1 scale
adv_ex = (adv_ex * 255).clamp(0, 255) # 0-255 scale
adv_ex = adv_ex.detach().cpu().data.numpy().round() # 四舍五入以去除小数部分
adv_ex = adv_ex.transpose((0, 2, 3, 1)) # transpose (bs, C, H, W) back to (bs, H, W, C)
adv_examples = adv_ex if i == 0 else np.r_[adv_examples, adv_ex]
return adv_examples, train_acc / len(loader.dataset), train_loss / len(loader.dataset)
集成多个模型作为您的代理模型,以增加黑盒可移植性
class ensembleNet(nn.Module):
def __init__(self, model_names):
super().__init__()
self.models = nn.ModuleList([ptcv_get_model(name, pretrained=True) for name in model_names])
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, m in enumerate(self.models):
# TODO: sum up logits from multiple models
# return ensemble_logits
emsemble_logits = m(x) if i == 0 else emsemble_logits + m(x)
return emsemble_logits/len(self.models)
先决条件
○攻击目标:非目标攻击
○攻击约束:L-infinity和参数ε
○攻击算法: FGSM/I-FGSM
○攻击模式:黑盒攻击(对代理网络执行攻击)

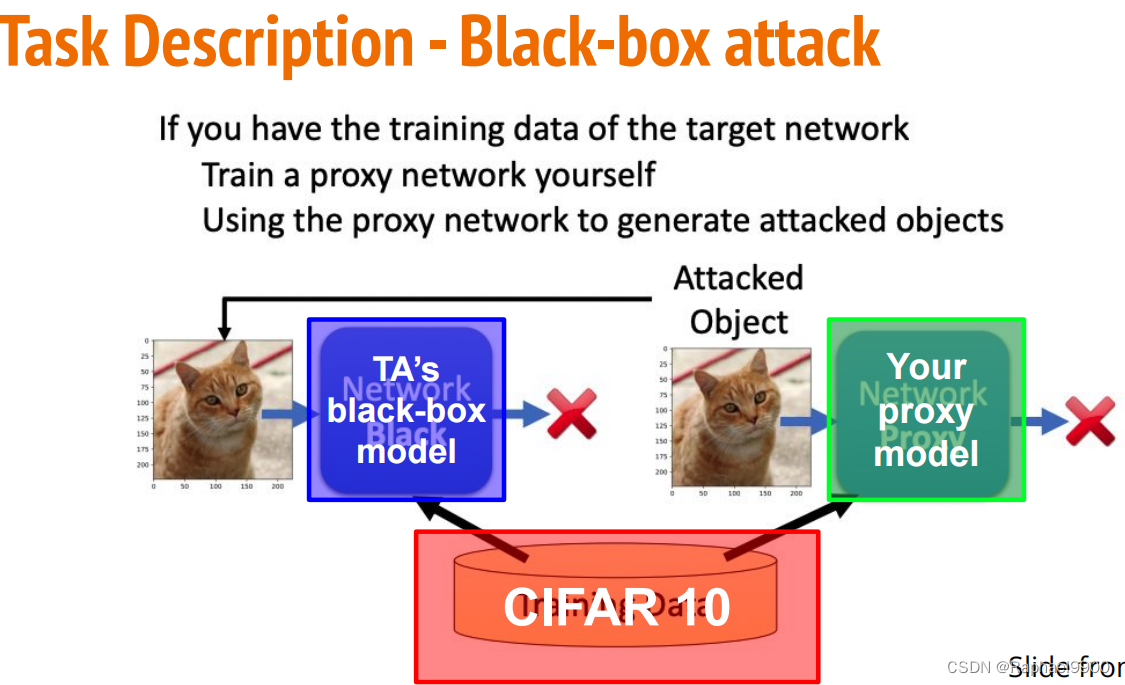
1.选择任意一个代理网络来攻击TA 中的黑盒模型。
2.实现非目标对抗性攻击方法
a.FGSM
b.I- FGSM
c.MI-FGSM
3.通过不同的输入(DIM)来增加攻击的可转移性
4.攻击多个代理模型-集成攻击(Ensemble attack)
二、算法
1、FGSM
●快速梯度符号法Fast Gradient Sign Method(FGSM)
FGSM是一种基于梯度生成对抗样本的算法,属于对抗攻击中的无目标攻击(即不要求对抗样本经过model预测指定的类别,只要与原样本预测的不一样即可)。我们在理解简单的dp网络结构的时候,在求损失函数最小值,我们会沿着梯度的反方向移动,使用减号,也就是所谓的梯度下降算法;而FGSM可以理解为梯度上升算法,也就是使用加号,使得损失函数最大化。SIGN 函数用于返回数字的符号。当数字大于 0 时返回 1,等于 0 时返回 0,小于0 时返回 -1。 x 是原始样本,θ 是模型的权重参数(即w),y是x的真实类别。输入原始样本,权重参数以及真实类别,通过 J 损失函数求得神经网络的损失值,∇x 表示对 x 求偏导,即损失函数 J 对 x 样本求偏导。ϵ(epsilon)的值通常是人为设定 ,可以理解为学习率,一旦扰动值超出阈值,该对抗样本会被人眼识别。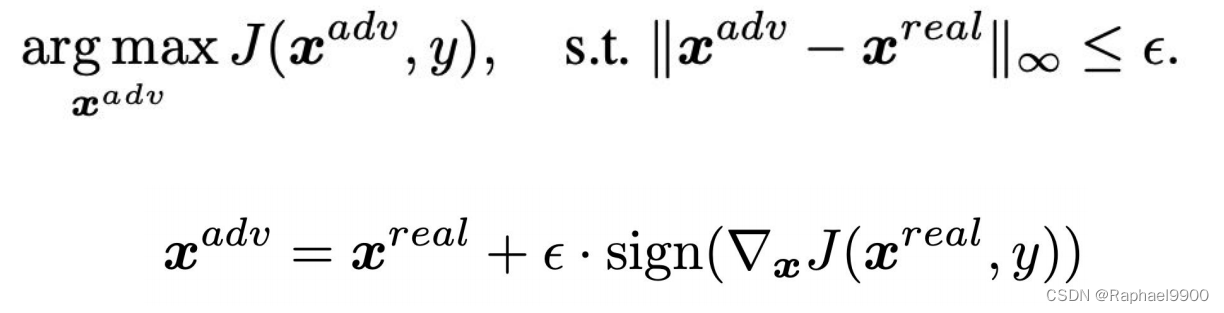
# perform fgsm attack
def fgsm(model, x, y, loss_fn, epsilon=epsilon):
x_adv = x.detach().clone() # initialize x_adv as original benign image x
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# fgsm: use gradient ascent on x_adv to maximize loss
grad = x_adv.grad.detach()
x_adv = x_adv + epsilon * grad.sign()
return x_adv
2、I-FGSM
● Iterative Fast Gradient Sign Method (I-FGSM)


# alpha and num_iter can be decided by yourself
alpha = 0.8/255/std
def ifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=20):
x_adv = x
# write a loop of num_iter to represent the iterative times
for i in range(num_iter):
# x_adv = fgsm(model, x_adv, y, loss_fn, alpha) # call fgsm with (epsilon = alpha) to obtain new x_adv
x_adv = x_adv.detach().clone()
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# fgsm: use gradient ascent on x_adv to maximize loss
grad = x_adv.grad.detach()
x_adv = x_adv + alpha * grad.sign()
x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv
3、MI-FGSM
用动量增强对抗性攻击,使用动量来稳定更新方向和逃避糟糕的局部最大值
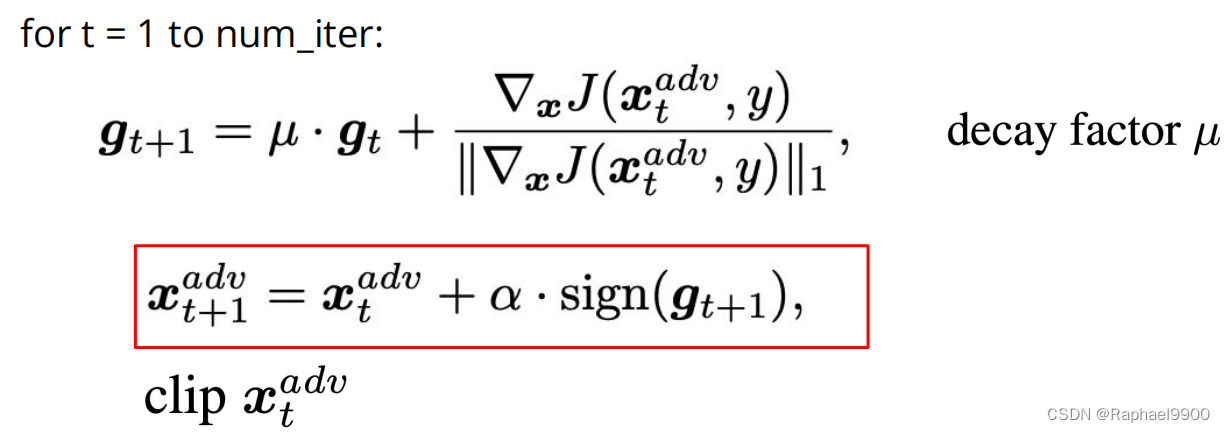
def mifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=20, decay=1.0):
x_adv = x
# initialze momentum tensor
momentum = torch.zeros_like(x).detach().to(device)
# write a loop of num_iter to represent the iterative times
for i in range(num_iter):
x_adv = x_adv.detach().clone()
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# TODO: Momentum calculation
# grad = .....
# TODO: Momentum calculation
grad = x_adv.grad.detach()
grad = decay * momentum + grad/(grad.abs().sum() + 1e-8)
momentum = grad
x_adv = x_adv + alpha * grad.sign()
x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv
过拟合也发生在对抗性攻击中……
●IFGSM贪婪地干扰图像的方向符号,损失梯度容易落入贫穷的局部极大值和过拟合特定的网络参数。
●这些过拟合对抗的例子很少转移到黑盒模型。
如何防止过拟合代理模型,增加黑盒攻击的可转移性?数据增强
4、多种输入(DIM)
1.随机调整大小(将输入图像的大小调整为随机大小)
2.随机填充(以随机的方式在输入图像周围填充零)
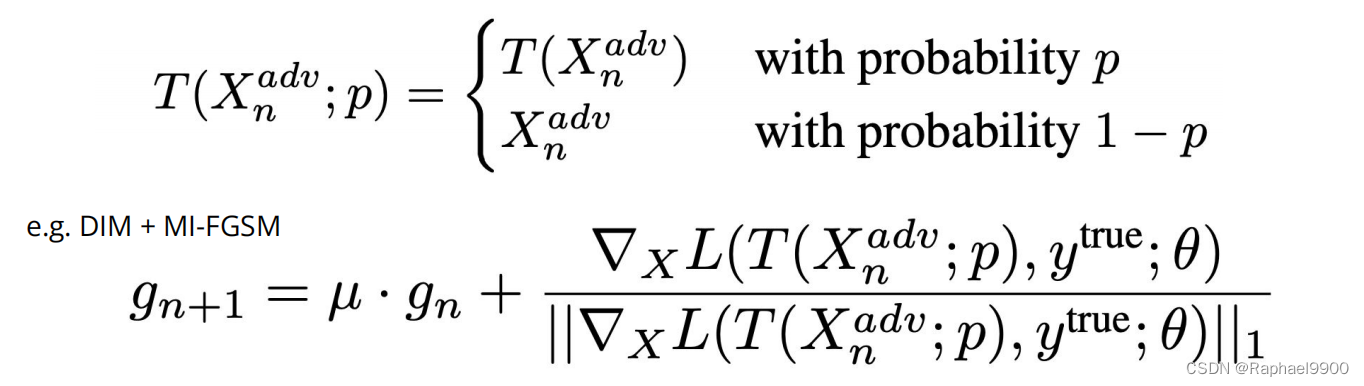
def dmi_mifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=50, decay=1.0, p=0.5):
x_adv = x
# initialze momentum tensor
momentum = torch.zeros_like(x).detach().to(device)
# write a loop of num_iter to represent the iterative times
for i in range(num_iter):
x_adv = x_adv.detach().clone()
x_adv_raw = x_adv.clone()
if torch.rand(1).item() >= p:
#resize img to rnd X rnd
rnd = torch.randint(29, 33, (1,)).item()
x_adv = transforms.Resize((rnd, rnd))(x_adv)
#padding img to 32 X 32 with 0
left = torch.randint(0, 32 - rnd + 1, (1,)).item()
top = torch.randint(0, 32 - rnd + 1, (1,)).item()
right = 32 - rnd - left
bottom = 32 - rnd - top
x_adv = transforms.Pad([left, top, right, bottom])(x_adv)
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# TODO: Momentum calculation
# grad = .....
grad = x_adv.grad.detach()
grad = decay * momentum + grad/(grad.abs().sum() + 1e-8)
momentum = grad
x_adv = x_adv_raw + alpha * grad.sign()
x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv
集成攻击
●选择代理模型的列表
●选择一个攻击算法(FGSM I-FGSM等等)
●攻击多个代理模型同时
●集成对抗攻击:研究可转移对抗的例子和黑盒攻击
●如何选择合适的代理模型黑盒攻击:
评估指标
●参数ε固定为8
●距离测量: L-inf. norm
●模型精度是唯一的评价指标

三、实验
1、Simple Baseline
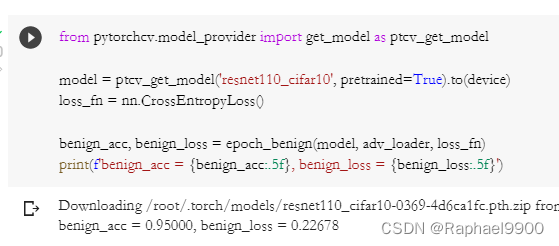
直接运行助教程式中的FGSM方法。FGSM只对图片进行一次攻击,代理模型(proxy models)是resnet110_cifar10,在被攻击图片中的精度benign_acc=0.95, benign_loss=0.22678。在攻击中,使用gen_adv_examples函数调用fgsm函数,精度降低:fgsm_acc=0.59, fgsm_loss=2.49186。

2、Medium Baseline
方法:I-FGSM方法 + Ensembel Attack。ifgsm方法相比与fgsm相比,使用了多次的fgsm循环攻击。另外使用了Ensemble attack,该方法使用多个代理模型攻击,需要改动ensembelNet这个类中的forward函数。在攻击中,使用gen_adv_examples函数调用emsebel_model和ifgsm,精度降低明显:ifgsm_acc = 0.01, ifgsm_loss=17.29498。
def forward(self, x):
emsemble_logits = None
for i, m in enumerate(self.models):
emsemble_logits = m(x) if i == 0 else emsemble_logits + m(x)
return emsemble_logits/len(self.models)


源模型是“resnet110_cifar10”,对dog2.png应用普通fgsm攻击:

通过imgaug包进行JPEG压缩,压缩率设置为70:

3、Strong Baseline
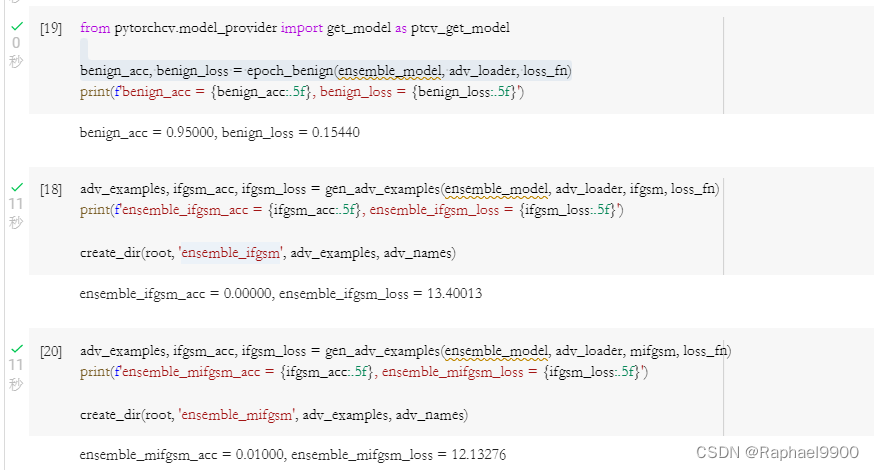
方法:MIFGSM + Ensemble Attack(pick right models)。mifgsm相比于ifgsm,加入了momentum,避免攻击陷入local maxima。在medium baseline中,我们随机挑选了一些代理模型,这样很盲目。可以选择一些训练不充分的模型,训练不充分的意思包括两方面:一是模型的训练epoch少,二是模型在验证集(val set)未达到最小loss。依据论文使用https://github.com/kuangliu/pytorch-cifar中的训练方法,选择resnet18模型,训练30个epoch(正常训练到达最好结果大约需要200个epoch),将其加入ensmbleNet中。攻击后的精度和loss:ensemble_mifgsm_acc = 0.01, emsemble_mifgsm_loss = 12.13276。
# TODO: Momentum calculation
grad = x_adv.grad.detach()
grad = decay * momentum + grad/(grad.abs().sum() + 1e-8)
momentum = grad
x_adv = x_adv + alpha * grad.sign()
4、Boss Baseline
方法:DIM-MIFGSM + Ensemble Attack(pick right models)。相对于strong baseline,将mifgsm替换为dim-mifgsm,对被攻击图片加入了transform来避免过拟合。transform是先随机的resize图片,然后随机padding图片到原大小。在mifgsm函数的基础上写dim_mifgsm函数,在攻击中,使用gen_adv_examples函数调用模型,攻击后的精度和loss:ensemble_dmi_mifgsm_acc = 0.00, emsemble_dim_mifgsm_loss = 13.64031。

def dmi_mifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=50, decay=1.0, p=0.5):
x_adv = x
# initialze momentum tensor
momentum = torch.zeros_like(x).detach().to(device)
# write a loop of num_iter to represent the iterative times
for i in range(num_iter):
x_adv = x_adv.detach().clone()
x_adv_raw = x_adv.clone()
if torch.rand(1).item() >= p:
#resize img to rnd X rnd
rnd = torch.randint(29, 33, (1,)).item()
x_adv = transforms.Resize((rnd, rnd))(x_adv)
#padding img to 32 X 32 with 0
left = torch.randint(0, 32 - rnd + 1, (1,)).item()
top = torch.randint(0, 32 - rnd + 1, (1,)).item()
right = 32 - rnd - left
bottom = 32 - rnd - top
x_adv = transforms.Pad([left, top, right, bottom])(x_adv)
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# TODO: Momentum calculation
# grad = .....
grad = x_adv.grad.detach()
grad = decay * momentum + grad/(grad.abs().sum() + 1e-8)
momentum = grad
x_adv = x_adv_raw + alpha * grad.sign()
x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv