使用python编写网络爬虫
前言
此篇文章是本人编写爬虫获取数据的心得体会,涉及到数据收集、数据预处理。对于数据存储、数据处理与分析、数据展示/数据可视化、数据应用部分请关注我的新文章。仅适用于新手python、爬虫入门。
特别说明:
**1、本篇内容仅供个人学习交流用,禁止作为商业用途。【转载请注明出处】 https://blog.csdn.net/qq_44092306/
2、本篇文章只是介绍爬虫的思路,对于引用的模块不做详细解释,模块详细解释请大家查阅其他资料。谢谢!
1、为何使用爬虫
简单的说,使用爬虫的目的就是为了降低工作量。举个例子,当我们需要获取一些信息的时候,这些信息存在于不同的网页上面,而且数据量巨大,单纯的靠人工去记录则会浪费很多时间和精力。这时,我们就可以使用爬虫作为工具去获取这些数据集,大大减少了机械性工作的时间。在大数据中,数据的获取往往离不开爬虫。
2、编写爬虫的知识要求
- python基础知识:语法规则、控制语句、数据结构(字典、元组、列表)、函数 、模块
- HTML基础、CSS基础、http、https协议
- 会灵活的字符串处理、数据结构的处理
3、确定爬虫使用的工具库
本人使用的python版本为3
from bs4 import BeautifulSoup
import requests
import lxml
4、确定要获取的数据集
资源定位:获取贝壳网中的二手房房源信息
说明: 我们在选择目标网址的时候,尽量选择正规,用户使用量多的网站,虽然会遇到一些反爬措施。小网站尽量不要爬,因为小网站的网页格式有些并不是固定的,当我们写了爬虫代码后,运行起来会发现不能够通用,从而使爬取复杂化。
要获取的数据集: 房源标题、楼盘名称、简介、价格 (其他数据项也可获取,这几项只是作为例子)
4.1 分析Url地址变化

通过浏览网页发现,底部有分页导航栏,点击下一页时,url变化为
https://jn.ke.com/ershoufang/pg2/
因此,首页为https://jn.ke.com/ershoufang/pg1/。至此url变化分析完毕。
分析URL地址变化的目的是: 通过request.get()方法循环这些url,获取到HTML页面元素
4.2 获取目标数据集所在的HTML区域
在目标网页上面点击F12进入开发者模式,我们只想取得房源信息,因此其他HTML均为无用数据,无需获取。我们所做的是尽量将目标区域缩小到最小范围。
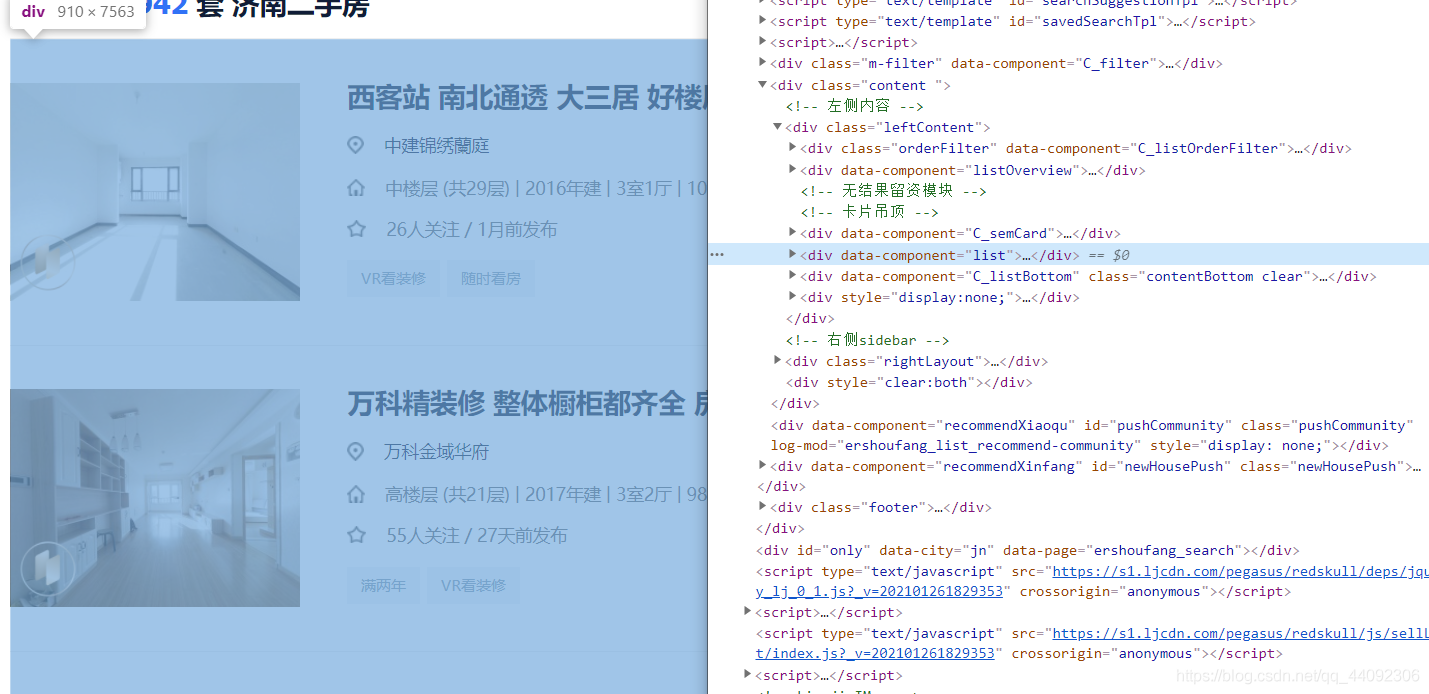
通过分析,房源列表项所在区域均在<div data-componet=‘‘list’’>标签中,通过浏览发现,还可以继续缩小区域 。最终,目标区域缩小到
5、开始爬取页面
5.1 模拟浏览器
因为大部分的网站都有反爬取机制,所以我们需要让程序去模拟浏览器,通过设置代理和请求头,以及时间间隔,这几种方法可以避免大多数的网站把我们的请求挂掉。
# 请求头
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0Win64x64) AppleWebKit / 537.36(XHTML, likeGecko) Chrome '
'/ 11.1.1111.111Safari / 111.11'
}
# 设置代理 http-协议类型 101.4.136.34-代理ip 82-代理端口
proxy = {
'http': 'http://101.4.136.34:82'}
r = requests.get(url, headers=headers, proxies=proxy)
r.encoding = 'gbk' #设置编码格式
context = r.text
# 第一个参数表示被解析的html内容,第二个参数表示使用的解析器
soup = BeautifulSoup(context, 'lxml')
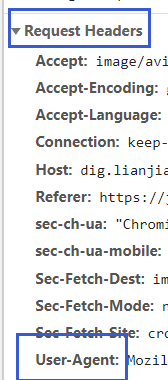
请求头通过需要F12查看

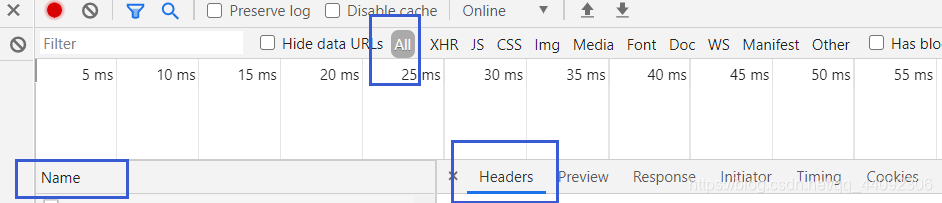
选择Name中的一项,查看Headers,找到如下内容复制到代码里面即可
soup即为我们解析后的HTML网页,大家可以试着print(soup)看看是什么。
就是一个对应URL的HTML文档
5.2 获取目标HTML区域中的数据
通过前面的步骤,我们将数据集范围区域缩小到了<div class=‘‘info clear’’>标签中。现在我们可以获取到里面的内容了。
- 获取一页中所有的<div class=‘‘info clear’’>项
info_clear_all = soup.find_all('div', _class='info clear')
- 遍历info_clear_all
- 在迭代器的遍历范围内找到目标数据所在区域
- 获取目标数据区域的具体内容
具体代码如下:
from webbrowser import Mozilla
from bs4 import BeautifulSoup
import requests
import lxml
import random
import time
url = 'https://jn.ke.com/ershoufang/'
def getSoup(Url):
# 设置请求头
headers = {
# headers中的内容为您浏览器的具体信息,请参考上述补充
}
# 设置代理 http-协议类型 101.4.136.34-代理ip 82-代理端口
proxy = {
'http': 'http://101.4.136.34:82'}
r = requests.get(Url, headers=headers, proxies=proxy)
# 获取网页的编码格式
encode = r.encoding
# 获取HTML网页
context = r.text
# 解析网页
soup = BeautifulSoup(context, 'lxml')
return soup
def getContext():
soup = getSoup(url)
# 获取<div class='info clear'></div>所有标签项
info_clear_all = soup.find_all('div', class_='info clear')
for a in info_clear_all:
# 获取标题
label_a_title = a.find('a', class_='VIEWDATA CLICKDATA maidian-detail') # 获取标题所在的a标签
title = label_a_title.attrs['title'] # 获取标题
print('标题:'+title)
# 获取楼盘名称
positionInfo = a.find('div', class_='positionInfo') # 缩小楼盘名称所在范围
label_a = positionInfo.find('a') # 获取<a>标签
building_name = label_a.text # 获取楼盘名称
print('楼盘名称:' + building_name)
# 获取楼盘简介
houseInfo = a.find('div', class_='houseInfo') # 获取简介所在的div范围
introduce = houseInfo.text.replace(' ', '').strip().replace('\n', '') # 获取简介
print('楼盘简介:'+introduce)
# 获取楼盘价格
totalPrice = a.find('div', class_='totalPrice') # 获取楼盘价格所在div范围
price = totalPrice.text # 获取楼盘价格
print('楼盘价格:'+price+'\n')
if __name__ == "__main__":
getContext()
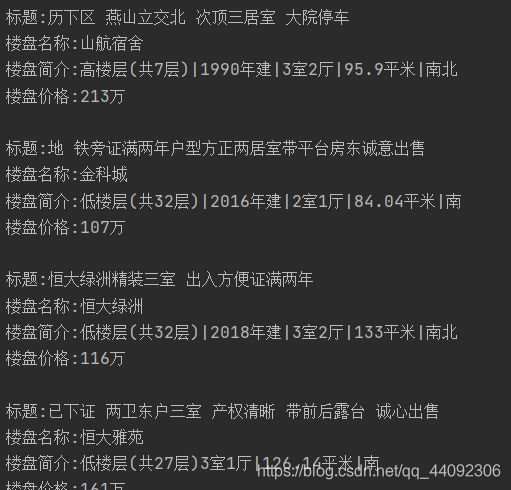
运行结果