聚类(Clustering)
1 无监督学习:简介
这将是一个激动人心的时刻,因为这是我们学习的第一个非监督学习算法。我们将要让计算机学习无标签数据,而不是此前的标签数据。
那么,什么是非监督学习呢?在课程的一开始,我曾简单的介绍过非监督学习,然而,我们还是有必要将其与监督学习做一下比较。
在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签,我们需要据此拟合一个假设函数。与此不同的是,在非监督学习中,我们的数据没有附带任何标签,我们拿到的数据就是这样的:
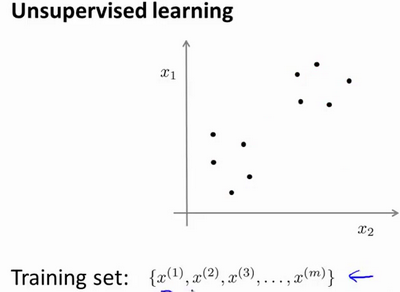
在这里我们有一系列点,却没有标签。因此,我们的训练集可以写成只有 x ( 1 ) x^{(1)}