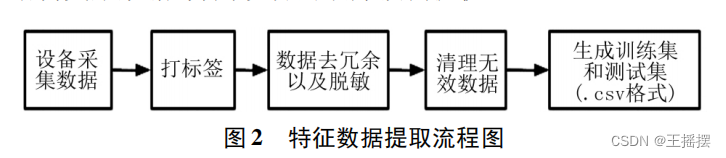
数据降维和特征提取都是在数据预处理过程中常用的技术,它们旨在减少数据的维度以提升模型性能或减少计算复杂度。然而,它们的目标和方法略有不同:
-
数据降维(Dimensionality Reduction):
-
目标:数据降维的目的是减少数据的特征维度,同时保留尽可能多的原始信息,以便更高效地处理和分析数据。
-
方法:常用的数据降维方法包括主成分分析(PCA)、线性判别分析(LDA)等。PCA试图找到数据中最主要的方向(主成分)来表示数据,从而将数据投影到一个低维空间。LDA则是一种监督学习的降维方法,它考虑了类别信息,将数据映射到一个能够最好区分不同类别的低维空间。
-
适用场景:数据降维适用于当数据具有高维度但存在冗余信息时,可以帮助减少计算资源的开销、提升模型的训练效率,同时降低模型的过拟合风险。
-
-
特征提取(Feature Extraction):
-
目标:特征提取是通过将原始数据转化为一个新的特征空间,从而寻找到更具有区分性的特征,以便用于建模和预测。
-
方法:常用的特征提取方法包括基于统计学的方法(如均值、方差、相关系数等)、基于频域的方法(如傅里叶变换等)、基于信息论的方法(如互信息、信息增益等)等。
-
适用场景:特征提取通常用于当原始特征中包含大量噪声或冗余信息时,希望从中筛选出对目标任务更加有用的特征。
-
区别总结:
- 数据降维的目的是减少数据的维度,以降低计算复杂度或便于可视化,同时保留尽可能多的信息。
- 特征提取的目的是从原始特征中提取出对任务更有意义或更具区分性的特征,以改善模型的性能。
这两个技术通常在实际任务中同时使用,以便更好地准备数据用于建模和分析。
经典的数据预处理过程