注意:文中彩色代码均在Visual Studio 2022编译器中编写,本文为C语言数据结构手抄版,文中有部分改动,非原创。
目录
注意:文中彩色代码均在Visual Studio 2022编译器中编写,本文为C语言数据结构手抄版,文中有部分改动,非原创。
小结
5.4.线索二叉树
为什么要研究线索二叉树?
遍历二叉树是以一定的规则将二叉树中的结点排列成一个线性序列,得到二叉树中结点的前序序列或中序序列或后序序列。这实质上是对一个非线性结构的线性化操作,使每个结点(除第一个结点和最后一个结点外)在这个线性序列中有且仅有一个直接前趋和一个直接后继。
当用二叉链表作为二叉树的存储结构时,可以很方便的找到某个结点的左右孩子。
当用二叉链表作为二叉树的存储结构时,因为每个结点中只有指向其左、右孩子结点的指针域,所以从任一结点出发只能直接找到该结点左、右孩子,而一般情况下无法直接找到该结点在某种遍历序列中的前趋和后继结点。
若在每个结点中增加两个指针域来存放遍历时得到的前趋和后继信息,就可以通过该指针直接或间接访问其前趋和后继结点,但是这将大大降低存储空间的利用率。
二叉树链表中空指针域的数量:具有n个结点的二叉链表中,一共有2n个指针域;因为n个结点中有n-1个孩子,即2n个指针域中,有n-1个用来指示结点的左右孩子,其余n+1个指针域为空;因此可以利用这些空指针域存放指向结点在某种遍历次序下的前趋和后继结点的指针,这种指向前趋和后继结点的指针称为“线索”,加上线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树(Threaded Binary Tree)。
利用二叉链表中的空指针域:如果某个结点的左孩子为空,则将空的左孩子指针域指向其前驱结点;如果某结点的右孩子为空,则将空的右孩子指针域指向其后继结点。
在一个线索二叉树中,为了区分一个结点的左、右孩子指针域是指向其孩子的指针还是指向其前趋或后继的线索,可在结点结构中增加两个线索标志域,一个是左线索标志域,用leftTag表示,另一个是右线索标志域,用rightTag表示。leftTag和rightTag只能取值0和1增加线索标志域后的结点结构如下:

5.4.1.二叉树的线索化
我们把对一棵二叉线索链表结构中所有结点的空指针域按照某种遍历次序加线索的过程称为线索化。那么,如何对二叉树进行线索化呢?,只要按某种次序遍历二叉树,在遍历过程中用线索取代空指针即可。
设prior指向前趋结点的指针,它始终指向刚刚访问过的结点,初值置空NULL;设current为指向当前正在访问结点的指针。显然, *prior是结点*current的前趋结点, *current则是*prior的后继结点。current初始指向二叉树的根结点,下面给出二叉树按中序线索化的算法:
(1)如果根结点的左孩子指针域为空,则将左线索标志域leftTag置为1,同时把前趋结点的指针赋给根结点的左指针域,即给根结点加左线索。
(2)如果根结点的右孩子指针域为空,则将右线索标志域rightTag置为1,同时把后继结点的指针赋给根结点的右指针域,即给根结点加右线索。
(3)将根结点指针赋给存放前趋结点指针的变量prior,以便当访问下一个结点时,此根结点作为前趋结点。
先定义线索链表的结点类型如下:
| struct BinaryNode { char* data; int leftTag; struct BinaryNode* left; int rightTag; struct BinaryNode* right; }; |
对以根节点指针为current的二叉链表加中序线索的算法如下;
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "binaryTree.h" struct ThreadedBinaryNode { char* data; int leftTag; struct ThreadedBinaryNode* left; int rightTag; struct ThreadedBinaryNode* right; }; struct ThreadedBinaryNode* convertThreadedBinaryNode(struct BinaryNode* node) { if (node == NULL) { return NULL; } struct ThreadedBinaryNode* left = convertThreadedBinaryNode(node->left); struct ThreadedBinaryNode* right = convertThreadedBinaryNode(node->right); struct ThreadedBinaryNode* treeNode = malloc(sizeof(struct ThreadedBinaryNode)); if (treeNode == NULL) { return NULL; } treeNode->data = node->data; treeNode->leftTag = 0; treeNode->left = left; treeNode->rightTag = 0; treeNode->right = right; return treeNode; } void inorderThreadedBinaryNode(struct ThreadedBinaryNode* current) { static struct ThreadedBinaryNode* prior = NULL; if (current != NULL) { inorderThreadedBinaryNode(current->left); if (current->left == NULL) { current->leftTag = 1; } if (current->rightTag == NULL) { current->rightTag = 1; } if (prior) { if (prior->rightTag == 1) prior->right = current; if (current->leftTag == 1) current->left = prior; } prior = current; inorderThreadedBinaryNode(current->right); } } int main() { char preorder[19] = "A B D E G H C F I"; char inorder[19] = "D B G E H A C I F"; struct BinaryTree* binaryTree = initTreeBySequenceAndInorder(preorder, inorder, 0); inorderThreadedBinaryNode(convertThreadedBinaryNode(binaryTree->root)); return 0; } |
该算法与中序遍历算法类似,只是将遍历算法中访问结点*current的操作改为在*current和中序前趋*prior之间建立线索。在递归过程中对每个结点做且仅做一次访问,所以对于n个结点的二叉树,线索化的算法时间复杂度为O(n)。例如,如图5.16 (a)所示的二叉树所对应的中序线索二叉树如图5.16 (b)所示,图5.16(c)所示为二叉线索链表树。
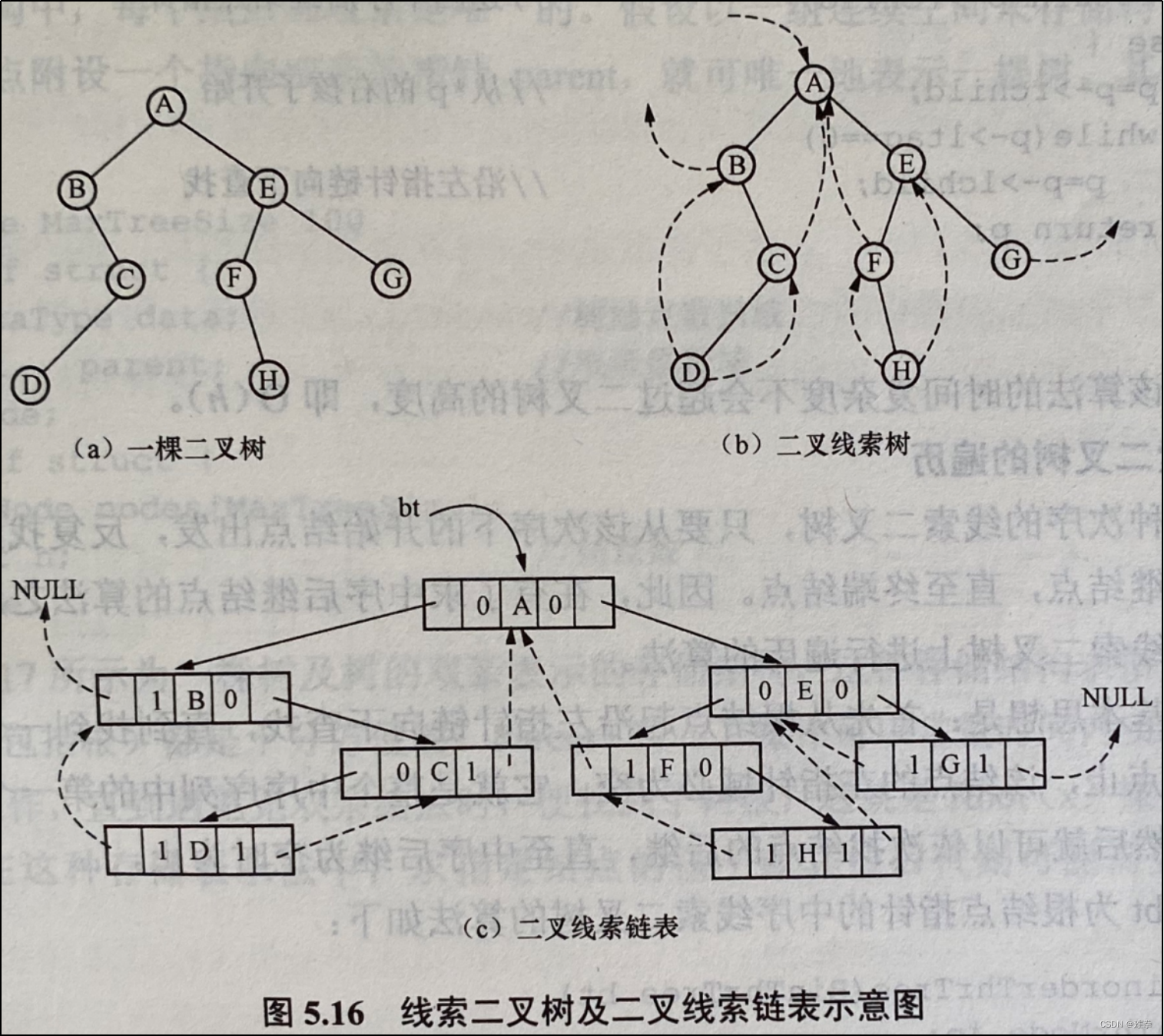
类似地,可以得到前序线索化和后序线索化的算法。
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "binaryTree.h" struct ThreadedBinaryNode { char* data; int leftTag; struct ThreadedBinaryNode* left; int rightTag; struct ThreadedBinaryNode* right; }; struct ThreadedBinaryNode* convertThreadedBinaryNode(struct BinaryNode* node) { if (node == NULL) { return NULL; } struct ThreadedBinaryNode* left = convertThreadedBinaryNode(node->left); struct ThreadedBinaryNode* right = convertThreadedBinaryNode(node->right); struct ThreadedBinaryNode* treeNode = malloc(sizeof(struct ThreadedBinaryNode)); if (treeNode == NULL) { return NULL; } treeNode->data = node->data; treeNode->leftTag = 0; treeNode->left = left; treeNode->rightTag = 0; treeNode->right = right; return treeNode; } void preorderThreadedBinaryNode(struct ThreadedBinaryNode* current) { static struct ThreadedBinaryNode* prior = NULL; if (current != NULL) { if (current->left == NULL) { current->leftTag = 1; } if (current->right == NULL) { current->rightTag = 1; } if (prior) { if (prior->rightTag == 1) prior->right = current; if (current->leftTag == 1) current->left = prior; } prior = current; if (current->leftTag != 1) { preorderThreadedBinaryNode(current->left); } if (current->rightTag != 1) { preorderThreadedBinaryNode(current->right); } } } void subsequentThreadedBinaryNode(struct ThreadedBinaryNode* current) { static struct ThreadedBinaryNode* prior = NULL; if (current != NULL) { subsequentThreadedBinaryNode(current->left); subsequentThreadedBinaryNode(current->right); if (current->left == NULL) { current->leftTag = 1; } if (current->right == NULL) { current->rightTag = 1; } if (prior) { if (prior->rightTag == 1) prior->right = current; if (current->leftTag == 1) current->left = prior; } prior = current; } } int main() { char preorder[19] = "A B D E G H C F I"; char inorder[19] = "D B G E H A C I F"; struct BinaryTree* binaryTree = initTreeBySequenceAndInorder(preorder, inorder, 0); binaryTree->draw(binaryTree); struct ThreadedBinaryNode* threadedBinaryNode = convertThreadedBinaryNode(binaryTree->root); // preorderThreadedBinaryNode(threadedBinaryNode); subsequentThreadedBinaryNode(threadedBinaryNode); return 0; } |
5.4.2.二叉线索链表上的运算
下面介绍二叉线索链表上的运算方法。
1.查找结点*pointer后继结点
设*pointer为指向线索链表中结点的指针。若要在中序线索二叉树上查找结点*pointer的中序后继结点,要分两种情况:
(1)若结点*pointer的rightTag域值为1,则表明pointer->rightChild为右线索,它直接指向结点*pointer的中序后继结点。比如在图5.16 (c)中,若pointer指向数据域值为"C"的结点,该结点的rightTag域值为1,那么它的中序后继结点就是pointer>rightChild指向的结点,即数据域值为"A"吉 。
(2)若结点*pointer的rightTag域值为0,则表明pointer>rightChild指向右孩子结点,结点*pointer的中序后继结点必是其右子树第一个中序遍历到的结点,因此从结点*pointer的右孩子开始,沿左指针链向下查找,直到找到一个没有左孩子(即leftTag为1)的结点为止,该结点是结点*pointer,的右子树中“最左下”的结点,它就是结点的中序后继结点。如在图5.16 (c)中,若*pointer指向数据域值为"B"的结点,该结点的rightTag域值为0,那么它的中序后继结点就是pointer>rightChild指向结点的左孩子结点,即数据域值为"D"的结点。
根据以上分析,不难给出在中序线索二叉树上求结点*pointer的中序后继结点的算法:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "binaryTree.h" struct ThreadedBinaryNode { char* data; int leftTag; struct ThreadedBinaryNode* left; int rightTag; struct ThreadedBinaryNode* right; }; struct ThreadedBinaryNode* convertThreadedBinaryNode(struct BinaryNode* node) { if (node == NULL) { return NULL; } struct ThreadedBinaryNode* left = convertThreadedBinaryNode(node->left); struct ThreadedBinaryNode* right = convertThreadedBinaryNode(node->right); struct ThreadedBinaryNode* treeNode = malloc(sizeof(struct ThreadedBinaryNode)); if (treeNode == NULL) { return NULL; } treeNode->data = node->data; treeNode->leftTag = 0; treeNode->left = left; treeNode->rightTag = 0; treeNode->right = right; return treeNode; } void inorderThreadedBinaryNode(struct ThreadedBinaryNode* current) { static struct ThreadedBinaryNode* prior = NULL; if (current != NULL) { inorderThreadedBinaryNode(current->left); if (current->left == NULL) { current->leftTag = 1; } if (current->rightTag == NULL) { current->rightTag = 1; } if (prior) { if (prior->rightTag == 1) prior->right = current; if (current->leftTag == 1) current->left = prior; } prior = current; inorderThreadedBinaryNode(current->right); } } struct ThreadedBinaryNode* getSuccessorNode(struct ThreadedBinaryNode* binaryNode) { if (binaryNode->rightTag == 1) { return binaryNode->right; } else { binaryNode = binaryNode->right; while (binaryNode->leftTag == 0) { binaryNode = binaryNode->left; } return binaryNode; } } int main() { char preorder[19] = "A B D E G H C F I"; char inorder[19] = "D B G E H A C I F"; struct BinaryTree* binaryTree = initTreeBySequenceAndInorder(preorder, inorder, 0); binaryTree->draw(binaryTree); struct ThreadedBinaryNode* threadedBinaryNode = convertThreadedBinaryNode(binaryTree->root); inorderThreadedBinaryNode(threadedBinaryNode); struct ThreadedBinaryNode* result = getSuccessorNode(threadedBinaryNode); return 0; } |
显然,该算法的时间复杂度不会超过二叉树的高度,即O(h)。
2.线索二叉树的遍历
遍历某种次序的线索二叉树,只要从该次序下的开始结点出发,反复找到结点在该次序下的后继结点,直至终端结点。因此,在有了求中序后继结点的算法之后,就不难写出在中序线索二叉树上进行遍历的算法。其算法基本思想是:首先从根结点起沿左指针链向下查找,直到找到一个左线索标志为1的结点止,该结点的左指针域必为空,它就是整个中序序列中的第一个结点。访问该结点,然后就可以依次找结点的后继,直至中序后继为空时为止。
遍历以pointer为根结点指针的中序线索二叉树的算法如下:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "binaryTree.h" struct ThreadedBinaryNode { char* data; int leftTag; struct ThreadedBinaryNode* left; int rightTag; struct ThreadedBinaryNode* right; }; struct ThreadedBinaryNode* convertThreadedBinaryNode(struct BinaryNode* node) { if (node == NULL) { return NULL; } struct ThreadedBinaryNode* left = convertThreadedBinaryNode(node->left); struct ThreadedBinaryNode* right = convertThreadedBinaryNode(node->right); struct ThreadedBinaryNode* treeNode = malloc(sizeof(struct ThreadedBinaryNode)); if (treeNode == NULL) { return NULL; } treeNode->data = node->data; treeNode->leftTag = 0; treeNode->left = left; treeNode->rightTag = 0; treeNode->right = right; return treeNode; } void inorderThreadedBinaryNode(struct ThreadedBinaryNode* current) { static struct ThreadedBinaryNode* prior = NULL; if (current != NULL) { inorderThreadedBinaryNode(current->left); if (current->left == NULL) { current->leftTag = 1; } if (current->rightTag == NULL) { current->rightTag = 1; } if (prior) { if (prior->rightTag == 1) prior->right = current; if (current->leftTag == 1) current->left = prior; } prior = current; inorderThreadedBinaryNode(current->right); } } struct ThreadedBinaryNode* getSuccessorNode(struct ThreadedBinaryNode* binaryNode) { if (binaryNode->rightTag == 1) { return binaryNode->right; } else { binaryNode = binaryNode->right; while (binaryNode->leftTag == 0) { binaryNode = binaryNode->left; } return binaryNode->left; } } void foreachThreadedBinaryNode(struct ThreadedBinaryNode* binaryNode) { if (binaryNode == NULL) { return; } // find the first node. while (binaryNode->leftTag == 0) { binaryNode = binaryNode->left; } printf("中序遍历:"); do { printf("%s ", binaryNode->data); binaryNode = getSuccessorNode(binaryNode); } while (binaryNode != NULL); } int main() { char preorder[19] = "A B D E G H C F I"; char inorder[19] = "D B G E H A C I F"; struct BinaryTree* binaryTree = initTreeBySequenceAndInorder(preorder, inorder, 0); binaryTree->draw(binaryTree); struct ThreadedBinaryNode* threadedBinaryNode = convertThreadedBinaryNode(binaryTree->root); inorderThreadedBinaryNode(threadedBinaryNode); foreachThreadedBinaryNode(threadedBinaryNode); return 0; } |
运行结果:
| A / \ B C / \ / \ D E * F / \ / \ / \ / \ * * G H * * I * / / / / / / / / \ 中序遍历:D B G E H A C I F |
在上述的算法中, while循环是找遍历的第一个结点,次数是一个很小的常数,而do循环是以右线索为空为终结条件,所以该算法的时间复杂度为O(n)。
前序二叉树非叶子结点无法找到它的前驱,只能找到它的后继,是可以利用线索遍历的。前序线索二叉树从根结点开始遍历:
(1)若结点*pointer的leftTag域值为0,则pointer>leftChild指向左孩子结点必是其后继结点。
(2)若结点*pointer的leftTag域值为1,则无论rightTag值为0还是1,其后继结点均为pointer>rightChild指向的线索或结点。
| struct ThreadedBinaryNode* getPreorderSuccessorNode(struct ThreadedBinaryNode* binaryNode) { if (binaryNode == NULL) { #if PRINT printf("空线索二叉树结点!\n"); #endif return NULL; } if (binaryNode->rightTag == 1 || binaryNode->leftTag == 1) { return binaryNode->right; } else { return binaryNode->left; } } void foreachPreorderThreadedBinaryNode(struct ThreadedBinaryTree* binaryTree) { if (binaryTree == NULL || binaryTree->root == NULL) { #if PRINT printf("线索二叉树不存在!\n"); #endif return; } struct ThreadedBinaryNode* binaryNode = binaryTree->root; do { printf("%s ", binaryNode->data); binaryNode = getPreorderSuccessorNode(binaryNode); } while (binaryNode != NULL); } |
后序线索二叉树非叶子结点无法找到它的后继,需要借助于栈结构才能实现,这样就是失去了二叉树线索化的意义。
先序线索二叉树的缺点:无法找到先序序列中某结点的前驱。
后序线索二叉树的缺点:无法找到后序序列中某结点的后继。
| 中序线索二叉树 |
先序线索二叉树 |
后序线索二叉树 |
|
| 找前驱 |
√ |
× |
√ |
| 找后继 |
√ |
√ |
× |
5.4.3.封装二叉树算法
C语言数据结构【手抄版】第五章 树和二叉树【尾篇】二叉树C实现_难拳的博客-CSDN博客
5.5.树和森林
在这一节中将讨论树的存储表示、树的遍历以及森林与二叉树的对应关系。
5.5.1.树的存储结构
树的存储结构通常采用如下几种表示方式。
1.广义表表示法
运用广义表的链式存储结构可以存储森林的数据。

如上图所示,构建一个链式存储结构,tag表示当前结点是原子结点的还是有孩子结点,原子结点用atom=1表示,带有孩子结点用childLin=0表示,兄弟结点用nextLink表示。
| struct GFNode { enum { childLink, atom } tag; char* data; struct GFNode* childLink; struct GFNode* nextlink; }; |
新建generalizedForest.h头节点:
| #pragma once #ifndef GENERALIZED_FOREST_H #define GENERALIZED_FOREST_H struct GeneralizedForest { char* name; struct GFNode* headerNode; void (*foreach)(struct GeneralizedForest* gForest); void (*printfGFNode)(struct GFNode* gFNode); void (*printfGForest)(struct GFNode* gFNode); struct GFNode* (*get)(char* data, struct GeneralizedForest* gForest); struct GeneralizedForest* (*header)(struct GeneralizedForest* gForest); struct GeneralizedForest* (*tail)(struct GeneralizedForest* gForest); int (*depth)(struct GeneralizedForest* gForest); void (*ruin)(struct GeneralizedForest* gForest); }; struct GFNode { enum { childLink, atom } tag; char* data; struct GFNode* childLink; struct GFNode* nextlink; }; struct GeneralizedForest* initGeneralizedForest(); struct GeneralizedForest* createGForestByGFNode(struct GFNode* header); #endif |
头节点定义了森林广义表的创建、遍历、获取广义表表头、获取广义表表尾、计算广义表深度以及销毁广义表等功能。
实现头节点逻辑generalizedForest.c:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "dynamicArray.h" #include "generalizedForest.h" #define PRINT 1 struct GeneralizedForest* createGForest(); void foreachGForest(struct GeneralizedForest* gForest); void printfGFNode(struct GFNode* gFNode); void printfGForest(struct GFNode* gFNode); struct GFNode* getGFNodeByForest(char* data, struct GeneralizedForest* gForest); struct GeneralizedForest* headerGForest(struct GeneralizedForest* gForest); struct GeneralizedForest* tailGForest(struct GeneralizedForest* gForest); int depthGForest(struct GeneralizedForest* gForest); void ruinGForest(struct GeneralizedForest* gForest); void setGForestFunction(struct GeneralizedForest* gForest) { gForest->foreach = foreachGForest; gForest->printfGFNode = printfGFNode; gForest->printfGForest = printfGForest; gForest->get = getGFNodeByForest; gForest->header = headerGForest; gForest->tail = tailGForest; gForest->depth = depthGForest; gForest->ruin = ruinGForest; } struct GeneralizedForest* initGeneralizedForest() { struct GeneralizedForest* gForest = createGForest(); setGForestFunction(gForest); return gForest; } struct GeneralizedForest* createGForestByGFNode(struct GFNode* header) { struct GeneralizedForest* gForest = malloc(sizeof(struct GeneralizedForest)); char* name = malloc(sizeof(char) * 3); name = "LS"; if (gForest == NULL) { #ifdef PRINT printf("森林广义表创建失败,内存空间不足!\n"); #endif return NULL; } gForest->headerNode = header; gForest->name = name; setGForestFunction(gForest); return gForest; } char setGFNode(struct GFNode** gFNode, char ch) { while (ch == ' ') { scanf("%c", &ch); } struct ArrayList* list = initArrayList(5); char* chr; while (ch != '(' && ch != ',' && ch != ')') { chr = malloc(sizeof(char)); if (chr == NULL) { #ifdef PRINT printf("森林广义表结点创建失败,记录结点值的内存空间不足!\n"); #endif return; } *chr = ch; list->insert(list->size(list), chr, list); scanf("%c", &ch); } (*gFNode)->tag = atom; (*gFNode)->data = list->toString(list); (*gFNode)->childLink = NULL; (*gFNode)->nextlink = NULL; list->ruin(list); return ch; } void createGFNode(struct GFNode** gFNode, int isHeader) { char ch; scanf("%c", &ch); while (ch == ' ') { scanf("%c", &ch); } if (isHeader && ch == '(') { isHeader = 0; createGFNode(gFNode, isHeader); return; } *gFNode = malloc(sizeof(struct GFNode)); if (*gFNode == NULL) { #ifdef PRINT printf("森林广义表结点创建失败,内存空间不足!\n"); #endif return; } ch = setGFNode(gFNode, ch); if (ch == '(') { (*gFNode)->tag = childLink; createGFNode(&(*gFNode)->childLink, isHeader); scanf("%c", &ch); while (ch == ' ') { scanf("%c", &ch); } } if (ch == ',') { createGFNode(&(*gFNode)->nextlink, isHeader); } else if (ch == ')') { (*gFNode)->nextlink = NULL; } return; } struct GeneralizedForest* createGForest() { struct GeneralizedForest* gForest = malloc(sizeof(struct GeneralizedForest)); if (gForest == NULL) { #ifdef PRINT printf("森林广义表创建失败,内存空间不足!\n"); #endif return NULL; } char ch; scanf("%c", &ch); while (ch == '\n') { scanf("%c", &ch); } struct ArrayList* list = initArrayList(5); char* chr; while (ch != '=') { chr = malloc(sizeof(char)); if (chr == NULL) { #ifdef PRINT printf("森林广义表结点创建失败,记录结点值的内存空间不足!\n"); #endif return NULL; } *chr = ch; list->insert(list->size(list), chr, list); scanf("%c", &ch); } gForest->name = list->toString(list); list->ruin(list); createGFNode(&gForest->headerNode, 1); return gForest; } void foreachGFNode(struct GFNode* gFNode) { if (gFNode == NULL) { return; } if (gFNode->tag == atom) { printf("%s", gFNode->data); if (gFNode->nextlink == NULL) return; printf(","); foreachGFNode(gFNode->nextlink); } else { printf("%s", gFNode->data); printf("("); foreachGFNode(gFNode->childLink); printf(")"); if (gFNode->nextlink == NULL) return; printf(","); foreachGFNode(gFNode->nextlink); } } void foreachGForest(struct GeneralizedForest* gForest) { if (gForest == NULL) { #ifdef PRINT printf("森林广义表不存在!\n"); #endif return; } printf("%s=(", gForest->name); foreachGFNode(gForest->headerNode); printf(")\n"); } void printfGFNode(struct GFNode* gFNode) { if (gFNode == NULL) { #ifdef PRINT printf("森林广义表结点不存在!\n"); #endif return; } struct GFNode* node = malloc(sizeof(struct GFNode)); if (node == NULL) { #ifdef PRINT printf("打印结点数据,内存空间不足!\n"); #endif return NULL; } node->tag = gFNode->tag; node->data = gFNode->data; node->childLink = gFNode->childLink; node->nextlink = NULL; printf("结点:"); foreachGFNode(node); printf("\n"); free(node); node = NULL; } void printfGForest(struct GFNode* gFNode) { if (gFNode == NULL) { #ifdef PRINT printf("森林广义表结点不存在!\n"); #endif return; } printf("结点:("); foreachGFNode(gFNode); printf(")\n"); } struct GFNode* returnGFNode(struct GFNode* gFNode) { struct GFNode* node = malloc(sizeof(struct GFNode)); if (node == NULL) { #ifdef PRINT printf("获取结点数据,内存空间不足!\n"); #endif return NULL; } node->tag = gFNode->tag; node->data = gFNode->data; node->childLink = gFNode->childLink; node->nextlink = NULL; return node; } struct GFNode* getGFNode(char* data, struct GFNode* gFNode) { if (gFNode == NULL) { #ifdef PRINT printf("森林广义表头结点不存在!"); #endif return NULL; } if (data == NULL) { #ifdef PRINT printf("获取结点输入的值为空!"); #endif return NULL; } if (gFNode->tag == atom) { if (strcmp(gFNode->data, data) == 0) { return returnGFNode(gFNode); } if (gFNode->nextlink == NULL) return NULL; } else { if (strcmp(gFNode->data, data) == 0) { return returnGFNode(gFNode); } struct GFNode* node = getGFNode(data, gFNode->childLink); if (node != NULL) { return node; } if (gFNode->nextlink == NULL) return NULL; } return getGFNode(data, gFNode->nextlink); } struct GFNode* getGFNodeByForest(char* data, struct GeneralizedForest* gForest) { return getGFNode(data, gForest->headerNode); } struct GFNode* saveNewHeader(struct GeneralizedForest* gForest) { struct GFNode* header = malloc(sizeof(struct GFNode)); if (header == NULL) { #ifdef PRINT printf("获取森林广义表头,内存空间不足!\n"); #endif return NULL; } header->tag = gForest->headerNode->tag; header->data = gForest->headerNode->data; header->childLink = gForest->headerNode->childLink; header->nextlink = NULL; return header; } struct GeneralizedForest* headerGForest(struct GeneralizedForest* gForest) { if (gForest == NULL || gForest->headerNode == NULL) { #ifdef PRINT printf("森林广义表不存在!"); #endif return NULL; } if (strcmp(gForest->headerNode->data, "") == 0) { #ifdef PRINT printf("森林广义表为空,没有头节点!\n"); #endif return NULL; } return createGForestByGFNode(saveNewHeader(gForest)); } struct GFNode* saveNewTail(struct GeneralizedForest* gForest) { if (gForest->headerNode->nextlink != NULL) { return gForest->headerNode->nextlink; } char* data = malloc(sizeof(char)); struct GFNode* tail = malloc(sizeof(struct GFNode)); if (tail == NULL || data == NULL) { #ifdef PRINT printf("获取森林广义表头,内存空间不足!\n"); #endif return NULL; } tail->tag = atom; data[0] = '\0'; tail->data = data; tail->childLink = NULL; tail->nextlink = NULL; return tail; } struct GeneralizedForest* tailGForest(struct GeneralizedForest* gForest) { if (gForest == NULL || gForest->headerNode == NULL) { #ifdef PRINT printf("森林广义表不存在!"); #endif return NULL; } if (strcmp(gForest->headerNode->data, "") == 0) { #ifdef PRINT printf("森林广义表为空,没有尾节点!\n"); #endif return NULL; } return createGForestByGFNode(saveNewTail(gForest)); } void depthGFNode(struct GFNode* gFNode, int counter, int* depth) { if (gFNode == NULL) { if (*depth < counter) { *depth = counter; } return; } if (gFNode->tag == childLink && !strcmp(gFNode->childLink->data, "") == 0) { counter++; depthGFNode(gFNode->childLink, counter, depth); counter = 1; } depthGFNode(gFNode->nextlink, counter, depth); } int depthGForest(struct GeneralizedForest* gForest) { if (gForest == NULL || gForest->headerNode == NULL) { #ifdef PRINT printf("森林广义表不存在!"); #endif return -1; } int depth = 1; depthGFNode(gForest->headerNode, 1, &depth); if (strcmp(gForest->headerNode->data, "") == 0) { depth = 0; } printf("深度:%d\n", depth); return depth; } void ruinGFNode(struct GFNode* gFNode) { if (gFNode == NULL) { return; } if (gFNode->tag == atom) { if (gFNode->nextlink == NULL) { free(gFNode); gFNode = NULL; return; } ruinGFNode(gFNode->nextlink); } else { ruinGFNode(gFNode->childLink); if (gFNode->nextlink == NULL) { free(gFNode); gFNode = NULL; return; } ruinGFNode(gFNode->nextlink); } free(gFNode); gFNode = NULL; } void ruinGForest(struct GeneralizedForest* gForest) { if (gForest == NULL) { #ifdef PRINT printf("森林广义表不存在!"); #endif return; } ruinGFNode(gForest->headerNode); } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "generalizedForest.h" int main() { struct GeneralizedForest* gForest = initGeneralizedForest(); printf("遍历:"); gForest->foreach(gForest); printf("查找A"); gForest->printfGFNode(gForest->headerNode); printf("查找B"); gForest->printfGFNode(gForest->get("B", gForest)); struct GeneralizedForest* head = gForest->header(gForest); if (head != NULL) { printf("头"); gForest->printfGFNode(head->headerNode); } struct GeneralizedForest* tail = gForest->tail(gForest); if (tail != NULL) { printf("尾"); gForest->printfGForest(tail->headerNode); } int depth = gForest->depth(gForest); gForest->ruin(gForest); return 0; } |
运行结果:
| LS=A(B(E,F(G,H)),C,D(I,J)) 遍历:LS=(A(B(E,F(G,H)),C,D(I,J))) 查找A结点:A(B(E,F(G,H)),C,D(I,J)) 查找B结点:B(E,F(G,H)) 头结点:A(B(E,F(G,H)),C,D(I,J)) 尾结点:() 深度:4 |
由测试结果可以看到输入树的广义表表示形式,运用广义表的链式存储结构存储了树的数据信息。
2.双亲表示法
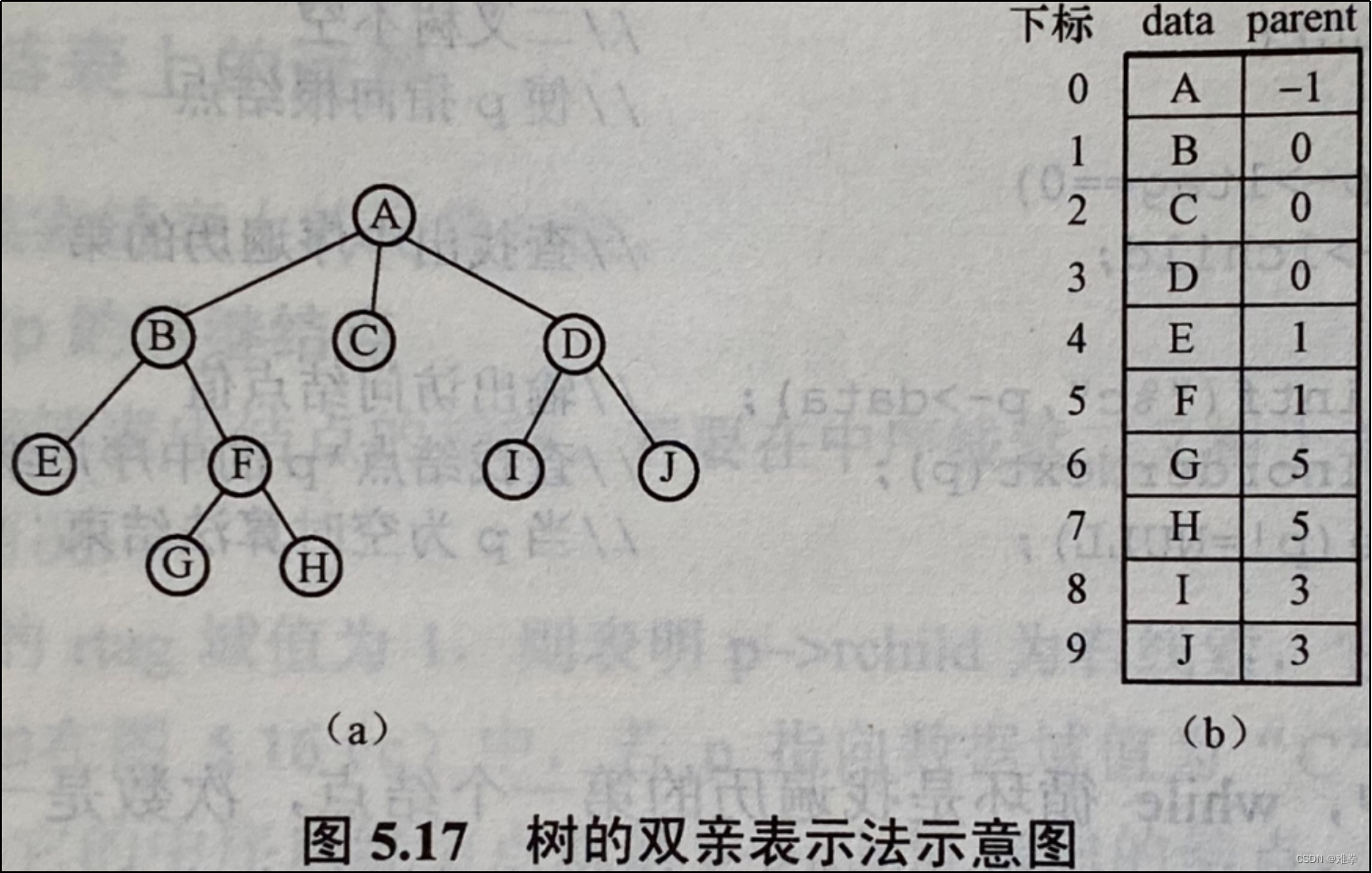
在树结构中,每个结点的双亲是唯一的。假设以一组连续空间来存储树的结点,同时为每个结点附设一个指向双亲的指针parent,就可唯一地表示一棵树。其结构类型说明如下:
| struct ForestNode { int parent; char* data; }; struct ArrayList* forest; |
如图5.17所示为一棵树及树的双亲表示的存储结构,这种存储结构求指定结点的双亲(或祖先包括根)都是十分方便的。查找parent 操作可以常量时间内实现。反复调用parent操作,直到遇见无双亲结点时,便找到了树根,这就是查找root 操作的执行过程。但是在这种存储表示法中,求指定结点的孩子或其他后代则可能需要遍历整个结构。
3.孩子链表法
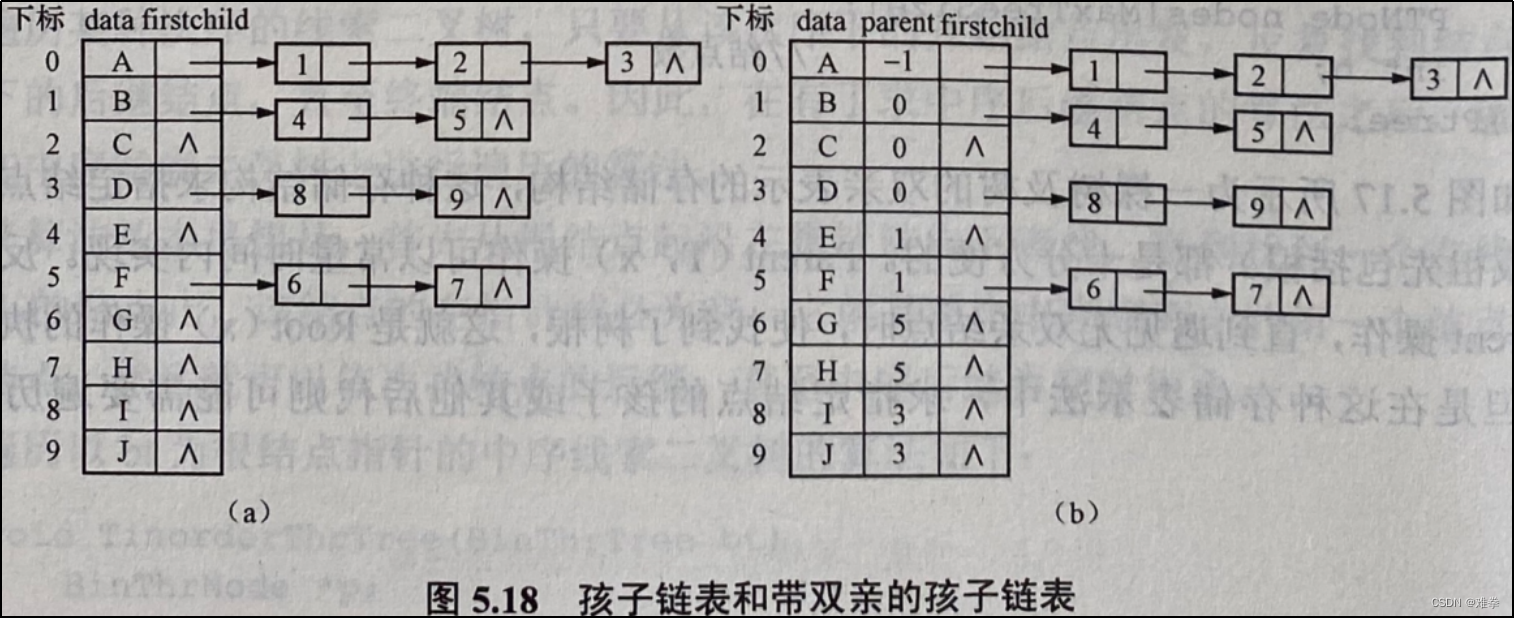
由于树中每个结点可能有多棵子树(即多个孩子),因此可以把每个结点的孩子结点看成一个线性表,并以单链表结构存储其孩子结点,这样, n个结点就有n个孩子链表。为了便于查找,可将树中各结点的孩子链表的头结点存放在一个指针数组中。其存储结构定义如下:
| struct ChildNode { int index; struct ChildNode* next; }; struct ForestNode { char* data; struct ChildNode* firstChild; }; struct ArrayList* forest |
图5.18 (a)是图5.17 (a)的孩子链表表示。与双亲表示法相反,孩子链表表示法便于那些涉及孩子结点的操作的实现,而不适用查找parent的操作。可以把双亲表示法和孩子链表表示法结合起来,即将双亲表示和孩子链表合在一起,这种结构称为带双亲的孩子链表,如图5.18 (b)所示。
| struct ChildNode { int index; struct ChildNode* next; }; struct ForestNode { int parent; char* data; struct ChildNode* firstChild; }; struct ArrayList* forest |
运用广义表存储树的信息,将树构建成带双亲的孩子链表结构。
新建头文件forest.h。
| #pragma once #ifndef FOREST_HEAD #define FOREST_HEAD #include "dynamicArray.h" struct Forest { char* name; struct ArrayList* root; }; struct ChildNode { int index; struct ChildNode* next; }; struct ForestNode { int parent; char* data; struct ChildNode* firstChild; }; struct Forest* initForest(); #endif |
实现头文件逻辑forest.c:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "forest.h" #define PRINT 1 void initForestRoot(struct Forest* forest); struct Forest* initForest() { struct Forest* forest = malloc(sizeof(struct Forest)); if (forest == NULL) { #ifdef PRINT printf("创建森林失败,开辟内存空间不足!\n"); #endif return NULL; } initForestRoot(forest); return forest; } void createChildNode(struct ChildNode** child) { (*child) = malloc(sizeof(struct ChildNode)); if ((*child) == NULL) { #ifdef PRINT printf("森林孩子结点创建失败,内存空间不足!\n"); #endif return; } (*child)->index = -1; (*child)->next = NULL; } char setForestNode(struct ForestNode* forestNode, char ch) { while (ch == ' ') { scanf("%c", &ch); } struct ArrayList* list = initArrayList(5); char* chr; while (ch != '(' && ch != ',' && ch != ')') { chr = malloc(sizeof(char)); if (chr == NULL) { #ifdef PRINT printf("森林结点创建失败,记录结点值的内存空间不足!\n"); #endif return NULL; } *chr = ch; list->insert(list->size(list), chr, list); scanf("%c", &ch); } forestNode->data = list->toString(list); list->ruin(list); return ch; } void createForestNode(struct ArrayList* arrayList, struct ChildNode* child, int* index, int parent) { char ch; scanf("%c", &ch); while (ch == ' ') { scanf("%c", &ch); } if (*index < 0 && ch == '(') { *index = 0; createForestNode(arrayList, NULL, index, parent); return; } if (child != NULL) child->index = *index; struct ForestNode* forestNode = malloc(sizeof(struct ForestNode)); if (forestNode == NULL) { #ifdef PRINT printf("森林结点创建失败,内存空间不足!\n"); #endif return; } forestNode->parent = parent; forestNode->data = NULL; forestNode->firstChild = NULL; arrayList->insert((*index)++, forestNode, arrayList); ch = setForestNode(forestNode, ch); if (ch == '(') { createChildNode(&forestNode->firstChild); createForestNode(arrayList, forestNode->firstChild, index, *index- 1); scanf("%c", &ch); while (ch == ' ') { scanf("%c", &ch); } } if (ch == ',') { createChildNode(&child->next); createForestNode(arrayList, child->next, index, parent); } return; } void initForestRoot(struct Forest* forest) { char ch; scanf("%c", &ch); while (ch == '\n') { scanf("%c", &ch); } struct ArrayList* list = initArrayList(5); char* chr; while (ch != '=') { chr = malloc(sizeof(char)); if (chr == NULL) { #ifdef PRINT printf("森林名称获取失败,内存空间不足!\n"); #endif return; } *chr = ch; list->insert(list->size(list), chr, list); scanf("%c", &ch); } forest->name = list->toString(list); list->ruin(list); forest->root = initArrayList(5); int* index = malloc(sizeof(int)); *index = -1; createForestNode(forest->root, NULL, index, -1); } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "forest.h" void print(void* data) { struct ForestNode* forestNode = data; printf("结点:%s ", forestNode->data); printf(" 父结点:%d", forestNode->parent); printf("孩子结点:"); struct ChildNode* child = forestNode->firstChild; while (child != NULL) { printf("%d ", child->index); child = child->next; } printf("\n"); } int main() { struct Forest* forest = initForest(); forest->root->foreach(print, forest->root); return 0; } |
运行结果:
| LS=(A(B(E,F(G,H)),C,D(I,J))) 结点:A 父结点:-1孩子结点:1 6 7 结点:B 父结点:0孩子结点:2 3 结点:E 父结点:1孩子结点: 结点:F 父结点:1孩子结点:4 5 结点:G 父结点:3孩子结点: 结点:H 父结点:3孩子结点: 结点:C 父结点:0孩子结点: 结点:D 父结点:0孩子结点:8 9 结点:I 父结点:7孩子结点: 结点:J 父结点:7孩子结点: |
4.孩子兄弟表示法
孩子兄弟表示法又称二叉链表表示法,即以二叉链表作为树的存储结构,链表中两个链指针域分别指向该结点的第一个孩子结点和下一个兄弟结点,命名为firstchild域和nextsibling域。如图5.19所示就是图5.17中树的孩子兄弟链表。这种存储结构的最大优点是,它和二叉树的二叉链表表示完全一样,因此可利用二叉树的各种算法来实现对树的操作。

5.5.2.树、森林与二叉树的转换
树、森林与二叉树之间有一个自然的对应关系,即任何一棵树或一个森林都可唯一地对应于一棵二叉树,而任何一棵二叉树也能唯一地对应于一个森林或一棵树。
1.树、森林转换二叉树
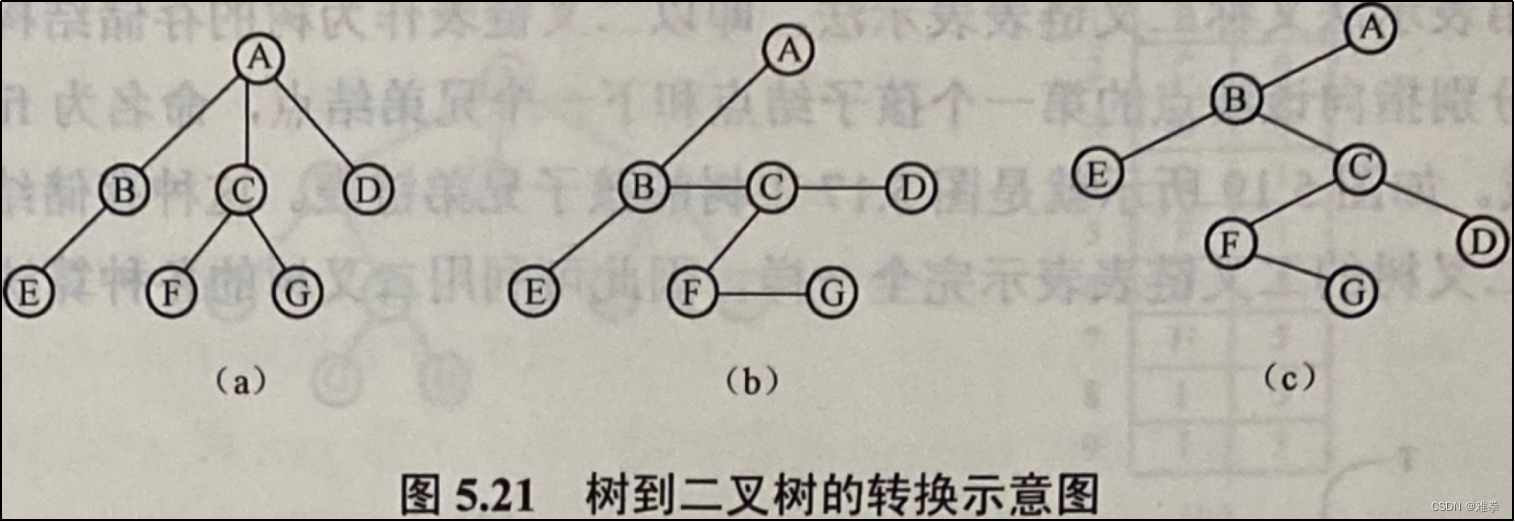
以二叉链表作为媒介,可导出树与二叉树之间的一个对应关系。也就是说,给定一棵树,可以找到唯一的一棵二叉树与之对应,从物理结构上来看,它们的结构是相同的,只是解释不同而己。图5.20直观地展示了树与二叉树之间的对应关系。
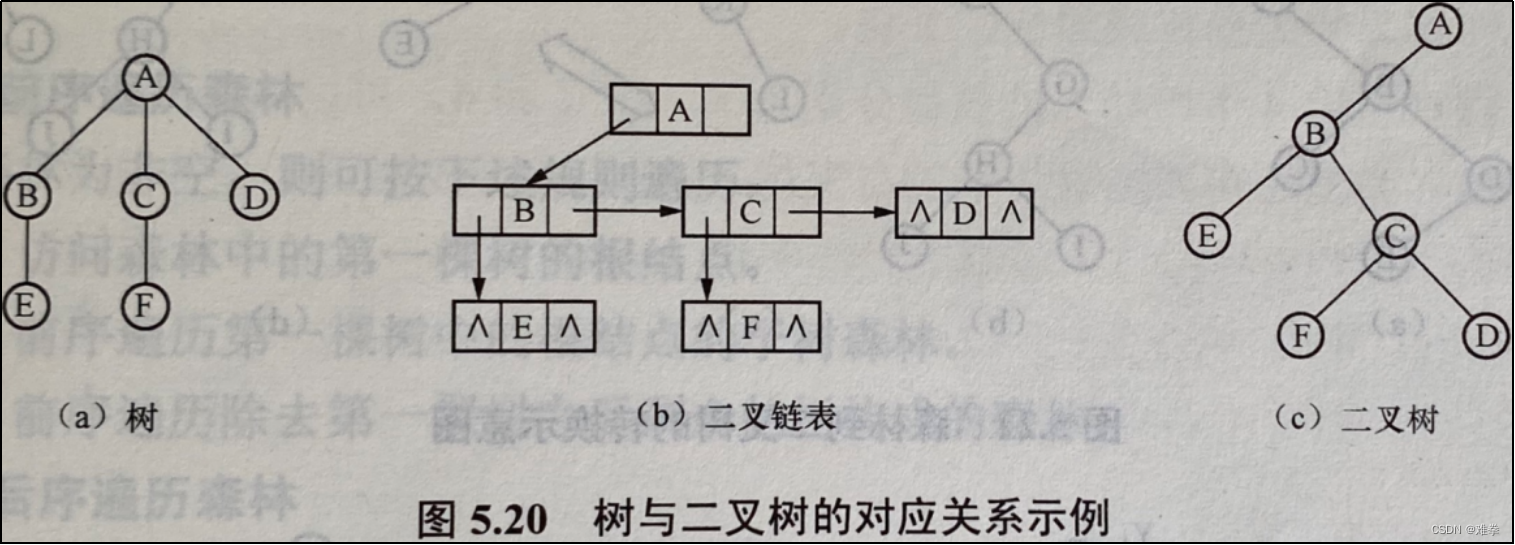
我们知道,树中每个结点至多只有一个最左边的孩子(长子)和一个右邻的兄弟,按照这种关系,只要按下面的方法即可将一棵树转换成二叉树:
1.首先在所有兄弟结点之间加一道连线;
2.然后再对每个结点保留长子的连线,去掉该结点与其他孩子的连线;
3.由于树根没有兄弟,所以转换后的二叉树,其根结点的右子树必为空。
使用上述转换方法可以将图5.21 (a)所示的树转换成图5.21 (b)所示的形式。它实际上就是一棵二叉树,若将所有兄弟之间的连线按顺时针方向旋转45°就看得更清楚,如图5.21 (c)所示。
将一个森林转换为二叉树的方法是:先将森林中的每棵树转化成二叉树,然后再将各二叉树的根结点看作是兄弟连在一起,形成一棵二叉树。如图5.22中图(a)、 (b)、 (c)三棵树构成的森林转换成图(d)所示的二叉树。
在森林数据结构forest中将森林孩子链表转换为二叉树链表结构,将结点的第一个孩子作为二叉树的左子树,将距离结点最近的兄弟结点作为当前结点的右孩子。
在forest.h头文件声明森林转换成二叉树功能。
| struct Forest { char* name; struct ArrayList* root; struct BinaryTree* (*convertBinaryTree)(struct Forest* forest); }; |
在forest.c中添加森林转换成二叉树结构的功能(完整代码见5.5.4小节)。
| struct BinaryTree* convertBinaryTree(struct Forest* forest) { if (forest == NULL || forest->root == NULL) { #ifdef PRINT printf("森林不存在!\n"); #endif return NULL; } return initTreeByForestArray(forest->root); } |
具体的实现由二叉链表binaryTree.c完成(详见5.4.3小节二叉树算法)。
| int isNextsibling(struct ArrayList* forestArray, struct ForestNode* forest, int index) { struct ForestNode* parent = forestArray->get(forest->parent, forestArray); struct ChildNode* child = parent->firstChild; while (child != NULL) { if (child->index == index) { if (child->next == NULL) { return 0; } else { return 1; } } child = child->next; } } struct BinaryNode* createNodeByForestArray(struct ArrayList* forestArray, int* index, int* depth, int probe) { int currentIndex = *index; struct ForestNode* forest = forestArray->get((*index)++, forestArray); struct BinaryNode* binaryNode = malloc(sizeof(struct BinaryNode)); if (binaryNode == NULL) { #if PRINT printf("创建二叉树根结点失败,内存空间不足!\n"); #endif return NULL; } binaryNode->data = forest->data; binaryNode->left = NULL; if (forest->firstChild != NULL) { binaryNode->left = createNodeByForestArray(forestArray, index, depth, ++probe); probe--; } binaryNode->right = NULL; if (*index < forestArray->size(forestArray) && forest->parent >= 0 && isNextsibling(forestArray, forest, currentIndex)) { binaryNode->right = createNodeByForestArray(forestArray, index, depth, ++probe); probe--; } if (*depth < probe) *depth = probe; return binaryNode; } struct BinaryTree* initTreeByForestArray(struct ArrayList* forestArray) { if (forestArray == NULL) { #if PRINT printf("创建二叉树失败,数据源森林数组不存在!\n"); #endif return NULL; } struct BinaryTree* binaryTree = malloc(sizeof(struct BinaryTree)); int* index = malloc(sizeof(int)), * depth = malloc(sizeof(int)); if (index == NULL || depth == NULL || binaryTree == NULL) { #if PRINT printf("创建二叉树失败,内存空间不足!\n"); #endif return NULL; } binaryTree->root = NULL; *index = 0; *depth = 0; int probe = 0; do { probe++; struct BinaryNode* binaryNode = createNodeByForestArray(forestArray, index, depth, probe); if (binaryTree->root == NULL) { binaryTree->root = binaryNode; } else { struct BinaryNode* rightNode = binaryTree->root; while (rightNode->right != NULL) { rightNode = rightNode->right; } rightNode->right = binaryNode; } } while (*index < forestArray->size(forestArray)); if (forestArray->size(forestArray) <= 0) { *depth = 0; } binaryTree->depth = *depth; setBinaryTreeFunction(binaryTree); free(index); index = NULL; free(depth); depth = NULL; return binaryTree; } |
测试图5.21转换过程:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "forest.h" void print(void* data) { struct ForestNode* forestNode = data; printf("结点:%s ", forestNode->data); printf(" 父结点:%d", forestNode->parent); printf("孩子结点:"); struct ChildNode* child = forestNode->firstChild; while (child != NULL) { printf("%d ", child->index); child = child->next; } printf("\n"); } int main() { while (1) { struct Forest* forest = initForest(); forest->root->foreach(print, forest->root); struct BinaryTree* binaryTree = forest->convertBinaryTree(forest); binaryTree->draw(binaryTree); } return 0; } |
运行结果:
| LS=(A(B(E),C(F,G),D)) 结点:A 父结点:-1孩子结点:1 3 6 结点:B 父结点:0孩子结点:2 结点:E 父结点:1孩子结点: 结点:C 父结点:0孩子结点:4 5 结点:F 父结点:3孩子结点: 结点:G 父结点:3孩子结点: 结点:D 父结点:0孩子结点:7 结点:H 父结点:6孩子结点: A / \ B * / \ / \ E C * * / \ / \ / \ / \ * * F D * * * * / \ / \ / \ / \ / \ / \ / \ / \ * * * * * G * * * * * * * * * * / / / / / / / / / / / / / / / / \ |
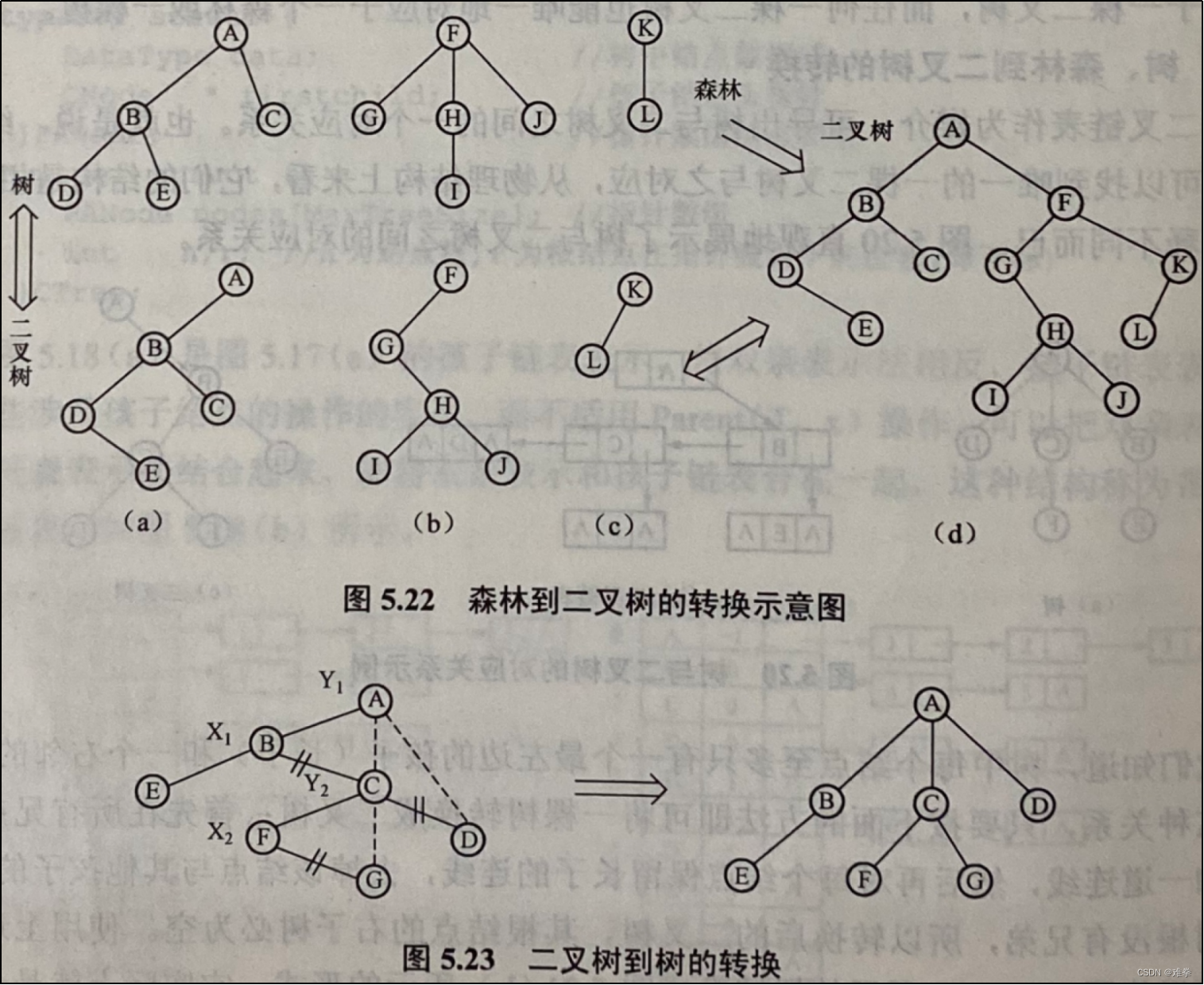
2.二叉树转换树、森林
同样,可以把二叉树转换成对应的树或森林,方法是:若二叉树中结点x是双亲Y的左孩子,则把x的右孩子、右孩子的右孩子······,都与Y用连线连起来,最后去掉所有双亲到右孩子的连线,即可得到对应的树或森林。如图5.23所示是将图5.21 (c)所示的二叉树转换成对应树的过程;图5.24是将图5.22 (d)所示的二叉树转换成森林的示意图。

添加二叉树转换成森林功能,在binaryTree.h与binaryTree.c中添加新功能(详见5.4.3小节二叉树算法)。
添加声明binaryTree.h:
| struct BinaryTree { struct BinaryNode* root; int depth; void (*draw)(struct BinaryTree* binaryTree); void (*foreachUseRecursion)(struct BinaryTree* binaryTree, enum Sequence sequence); void (*foreachUseStack)(struct BinaryTree* binaryTree, enum Sequence sequence); void (*foreachTier)(struct BinaryTree* binaryTree); struct Forest* (*convertForest)(struct BinaryTree* binaryTree); }; |
添加实现binaryTree.c(完整代码见5.5.4小节):
| struct Forest* convertForest(struct BinaryTree* binaryTree) { if (binaryTree == NULL || binaryTree->root == NULL) { #if PRINT printf("二叉树不存在!\n"); #endif return NULL; } return initForestByBinaryTree(binaryTree); } |
添加声明forest.h:
| struct Forest { char* name; struct ArrayList* root; struct BinaryTree* (*convertBinaryTree)(struct Forest* forest); }; |
添加实现forest.c:
| struct ForestNode* createRootForestNode(struct ArrayList* forestArray, struct BinaryNode* binaryNode, int index, int parent) { struct ForestNode* forestNode = malloc(sizeof(struct ForestNode)); if (forestNode == NULL) { #ifdef PRINT printf("根据二叉链表创建森林结点失败,内存空间不够!\n"); #endif return NULL; } forestNode->parent = parent; forestNode->data = binaryNode->data; forestNode->firstChild = NULL; forestArray->insert(index, forestNode, forestArray); return forestNode; } void createForestNodeByBinaryTree(struct ArrayList* forestArray, int* index, struct BinaryNode* binaryNode, struct ChildNode* frontChild, int parent) { struct ForestNode* forestNode = createRootForestNode(forestArray, binaryNode, *index, parent); int currentIndex = *index; (*index)++; if (binaryNode->left != NULL) { struct ChildNode* childNode = malloc(sizeof(struct ChildNode)); if (childNode == NULL) { #ifdef PRINT printf("根据二叉链表创建森林结点第一个孩子失败,内存空间不够!\n"); #endif return NULL; } childNode->index = *index; childNode->next = NULL; forestNode->firstChild = childNode; createForestNodeByBinaryTree(forestArray, index, binaryNode->left, forestNode->firstChild, currentIndex); } if (binaryNode->right != NULL) { if (frontChild == NULL && parent == -1) { createForestNodeByBinaryTree(forestArray, index, binaryNode->right, frontChild, parent); return; } struct ChildNode* nextChild = malloc(sizeof(struct ChildNode)); if (nextChild == NULL) { #ifdef PRINT printf("根据二叉链表创建森林结点其它孩子失败,内存空间不够!\n"); #endif return NULL; } nextChild->index = *index; nextChild->next = NULL; frontChild->next = nextChild; createForestNodeByBinaryTree(forestArray, index, binaryNode->right, frontChild->next, parent); } } struct Forest* initForestByBinaryTree(struct BinaryTree* binaryTree) { if (binaryTree == NULL || binaryTree->root == NULL) { #ifdef PRINT printf("根据二叉链表创建森林失败,二叉链表不存在!\n"); #endif return NULL; } struct ArrayList* forestArray = initArrayList(5); int* index = malloc(sizeof(int)); if (index == NULL) { #ifdef PRINT printf("根据二叉链表创建森林索引失败,内存空间不足!\n"); #endif return NULL; } *index = 0; createForestNodeByBinaryTree(forestArray, index, binaryTree->root, NULL, -1); struct Forest* forest = malloc(sizeof(struct Forest)); if (forest == NULL) { #ifdef PRINT printf("创建森林失败,开辟内存空间不足!\n"); #endif return NULL; } char* name = malloc(sizeof(char) * 3); name = "LS"; forest->name = name; forest->root = forestArray; setForestFunction(forest); return forest; } |
测试输入图5.24的森林结构LS=(A(B(D,E),C),F(G,H(I),J),K(L)):
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "forest.h" void print(void* data) { struct ForestNode* forestNode = data; printf("结点:%s ", forestNode->data); printf(" 父结点:%d ", forestNode->parent); printf("孩子结点:"); struct ChildNode* child = forestNode->firstChild; while (child != NULL) { printf("%d ", child->index); child = child->next; } printf("\n"); } int main() { while (1) { struct Forest* forest = initForest(); forest->root->foreach(print, forest->root); struct BinaryTree* binaryTree = forest->convertBinaryTree(forest); binaryTree->draw(binaryTree); struct Forest* converForest = binaryTree->convertForest(binaryTree); converForest->root->foreach(print, converForest->root); struct BinaryTree* converTree = converForest->convertBinaryTree(converForest); converTree->draw(converTree); } return 0; } |
运行结果:
| LS=(A(B(D,E),C),F(G,H(I),J),K(L)) 结点:A 父结点:-1 孩子结点:1 4 结点:B 父结点:0 孩子结点:2 3 结点:D 父结点:1 孩子结点: 结点:E 父结点:1 孩子结点: 结点:C 父结点:0 孩子结点: 结点:F 父结点:-1 孩子结点:6 7 9 结点:G 父结点:5 孩子结点: 结点:H 父结点:5 孩子结点:8 结点:I 父结点:7 孩子结点: 结点:J 父结点:5 孩子结点: 结点:K 父结点:-1 孩子结点:11 结点:L 父结点:10 孩子结点: A / \ B F / \ / \ D C G K / \ / \ / \ / \ * E * * * H L * / \ / \ / \ / \ / \ / \ / \ / \ * * * * * * * * * * I J * * * * / / / / / / / / / / / / / / / / \ 结点:A 父结点:-1 孩子结点:1 4 结点:B 父结点:0 孩子结点:2 3 结点:D 父结点:1 孩子结点: 结点:E 父结点:1 孩子结点: 结点:C 父结点:0 孩子结点: 结点:F 父结点:-1 孩子结点:6 7 9 结点:G 父结点:5 孩子结点: 结点:H 父结点:5 孩子结点:8 结点:I 父结点:7 孩子结点: 结点:J 父结点:5 孩子结点: 结点:K 父结点:-1 孩子结点:11 结点:L 父结点:10 孩子结点: A / \ B F / \ / \ D C G K / \ / \ / \ / \ * E * * * H L * / \ / \ / \ / \ / \ / \ / \ / \ * * * * * * * * * * I J * * * * / / / / / / / / / / / / / / / / \ |
从运行结果不难看出,数据结构从森林转换成二叉树,又从二叉树转换成了森林,数据结果没有发生错误。
5.5.3.树和森林的遍历
在树中,任何一个结点都可能有两棵以上的子树,不易于讨论中根次序的遍历。为此,一般都只给出两种次序遍历树的方法,即前序(先根次序)遍历和后序(后根次序)遍历。
树的前序遍历是指先访问树的根结点,然后依次前序遍历根的每棵子树。树的后序遍历是指先依次后序遍历根的每棵子树,然后访问根结点。
例如,对如图5.21 (a)所示的树进行前序遍历和后序遍历,得到树的前序序列和后序序列分别为ABECFGD和EBFGCDA。
由此可见,前序遍历一棵树等价于前序遍历该树对应的二叉树,而后序遍历一棵树则等价于中序遍历该树对应的二叉树。例如,在图5.21中,图(b)所示的二叉树是图(a)所示的树转换而成的。读者可以写出该二叉树的前序序列和中序序列,验证上述等价说法的正确性。
按照森林和树相互递归的定义,可以推出访问森林的两种遍历方法:前序遍历和后序遍历。
1.前序遍历森林
若森林为非空,则可按下述规则遍历:
1.访问森林中的第一棵树的根结点。
2.前序遍历第一棵树中的根结点的子树森林。
3.前序遍历除去第一棵树之后剩余的树构成的森林。
2.后序遍历森林
若森林为非空,则可按下述规则遍历:
1.后序遍历森林中第一棵树的根结点的子树森林。
2.访问第一棵树的根结点。
3.后序遍历除去第一棵树之后剩余的树构成的森林。
简而言之,前序遍历森林是从左到右依次按前序(先根)次序遍历森林中的每一棵树,而后序遍历森林则是从左到右依次按后序(后根)次序遍历森林中的每一棵树。
若对如图5.22所示的森林进行前序遍历和后序遍历,则得到该森林的前序序列和后序序列分别为ABDECFGHIJKL和DEBCAGIHJFLK;而对图5.22 (d)所示的二叉树进行前序遍历和后序遍历,可以得到同前一样的遍历序列。
也就是说,前序遍历森林和前序遍历其对应的二叉树的结果是相同的,而后序遍历森林和中序遍历其对应二叉树的结果一样。
5.5.4.封装森林结构算法
头文件forest.h:
| #pragma once #ifndef FOREST_HEAD #define FOREST_HEAD #include "dynamicArray.h" #include "binaryTree.h" struct Forest { char* name; struct ArrayList* root; struct BinaryTree* (*convertBinaryTree)(struct Forest* forest); }; struct ChildNode { int index; struct ChildNode* next; }; struct ForestNode { int parent; char* data; struct ChildNode* firstChild; }; struct Forest* initForest(); struct Forest* initForestByBinaryTree(struct BinaryTree* binaryTree); #endif |
头文件实现forest.c:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "forest.h" #define PRINT 1 void initForestRoot(struct Forest* forest); struct BinaryTree* convertBinaryTree(struct Forest* forest); void setForestFunction(struct Forest* forest) { forest->convertBinaryTree = convertBinaryTree; } struct Forest* initForest() { struct Forest* forest = malloc(sizeof(struct Forest)); if (forest == NULL) { #ifdef PRINT printf("创建森林失败,开辟内存空间不足!\n"); #endif return NULL; } initForestRoot(forest); setForestFunction(forest); return forest; } void createChildNode(struct ChildNode** child) { (*child) = malloc(sizeof(struct ChildNode)); if ((*child) == NULL) { #ifdef PRINT printf("森林孩子结点创建失败,内存空间不足!\n"); #endif return; } (*child)->index = -1; (*child)->next = NULL; } char setForestNode(struct ForestNode* forestNode, char ch) { while (ch == ' ') { scanf("%c", &ch); } struct ArrayList* list = initArrayList(5); char* chr; while (ch != '(' && ch != ',' && ch != ')') { chr = malloc(sizeof(char)); if (chr == NULL) { #ifdef PRINT printf("森林结点创建失败,记录结点值的内存空间不足!\n"); #endif return NULL; } *chr = ch; list->insert(list->size(list), chr, list); scanf("%c", &ch); } forestNode->data = list->toString(list); list->ruin(list); return ch; } void createForestNode(struct ArrayList* arrayList, struct ChildNode* child, int* index, int parent) { char ch; scanf("%c", &ch); while (ch == ' ') { scanf("%c", &ch); } if (*index < 0 && ch == '(') { *index = 0; createForestNode(arrayList, NULL, index, parent); return; } if (child != NULL) child->index = *index; struct ForestNode* forestNode = malloc(sizeof(struct ForestNode)); if (forestNode == NULL) { #ifdef PRINT printf("森林结点创建失败,内存空间不足!\n"); #endif return; } forestNode->parent = parent; forestNode->data = NULL; forestNode->firstChild = NULL; arrayList->insert((*index)++, forestNode, arrayList); ch = setForestNode(forestNode, ch); if (ch == '(') { createChildNode(&forestNode->firstChild); createForestNode(arrayList, forestNode->firstChild, index, *index - 1); scanf("%c", &ch); while (ch == ' ') { scanf("%c", &ch); } } if (ch == ',') { if (parent == -1 && child == NULL) { createForestNode(arrayList, NULL, index, parent); } else { createChildNode(&child->next); createForestNode(arrayList, child->next, index, parent); } } return; } void initForestRoot(struct Forest* forest) { char ch; scanf("%c", &ch); while (ch == '\n') { scanf("%c", &ch); } struct ArrayList* list = initArrayList(5); char* chr; while (ch != '=') { chr = malloc(sizeof(char)); if (chr == NULL) { #ifdef PRINT printf("森林名称获取失败,内存空间不足!\n"); #endif return; } *chr = ch; list->insert(list->size(list), chr, list); scanf("%c", &ch); } forest->name = list->toString(list); list->ruin(list); forest->root = initArrayList(5); int* index = malloc(sizeof(int)); if (index == NULL) { #ifdef PRINT printf("构建森林索引失败,内存空间不足!\n"); #endif return; } *index = -1; createForestNode(forest->root, NULL, index, -1); } struct BinaryTree* convertBinaryTree(struct Forest* forest) { if (forest == NULL || forest->root == NULL) { #ifdef PRINT printf("森林不存在!\n"); #endif return NULL; } return initTreeByForestArray(forest->root); } //=====↓↓↓=init Forest By Binary Tree=↓↓↓==== struct ForestNode* createRootForestNode(struct ArrayList* forestArray, struct BinaryNode* binaryNode, int index, int parent) { struct ForestNode* forestNode = malloc(sizeof(struct ForestNode)); if (forestNode == NULL) { #ifdef PRINT printf("根据二叉链表创建森林结点失败,内存空间不够!\n"); #endif return NULL; } forestNode->parent = parent; forestNode->data = binaryNode->data; forestNode->firstChild = NULL; forestArray->insert(index, forestNode, forestArray); return forestNode; } void createForestNodeByBinaryTree(struct ArrayList* forestArray, int* index, struct BinaryNode* binaryNode, struct ChildNode* frontChild, int parent) { struct ForestNode* forestNode = createRootForestNode(forestArray, binaryNode, *index, parent); int currentIndex = *index; (*index)++; if (binaryNode->left != NULL) { struct ChildNode* childNode = malloc(sizeof(struct ChildNode)); if (childNode == NULL) { #ifdef PRINT printf("根据二叉链表创建森林结点第一个孩子失败,内存空间不够!\n"); #endif return NULL; } childNode->index = *index; childNode->next = NULL; forestNode->firstChild = childNode; createForestNodeByBinaryTree(forestArray, index, binaryNode->left, forestNode->firstChild, currentIndex); } if (binaryNode->right != NULL) { if (frontChild == NULL && parent == -1) { createForestNodeByBinaryTree(forestArray, index, binaryNode->right, frontChild, parent); return; } struct ChildNode* nextChild = malloc(sizeof(struct ChildNode)); if (nextChild == NULL) { #ifdef PRINT printf("根据二叉链表创建森林结点其它孩子失败,内存空间不够!\n"); #endif return NULL; } nextChild->index = *index; nextChild->next = NULL; frontChild->next = nextChild; createForestNodeByBinaryTree(forestArray, index, binaryNode->right, frontChild->next, parent); } } struct Forest* initForestByBinaryTree(struct BinaryTree* binaryTree) { if (binaryTree == NULL || binaryTree->root == NULL) { #ifdef PRINT printf("根据二叉链表创建森林失败,二叉链表不存在!\n"); #endif return NULL; } struct ArrayList* forestArray = initArrayList(5); int* index = malloc(sizeof(int)); if (index == NULL) { #ifdef PRINT printf("根据二叉链表创建森林索引失败,内存空间不足!\n"); #endif return NULL; } *index = 0; createForestNodeByBinaryTree(forestArray, index, binaryTree->root, NULL, -1); struct Forest* forest = malloc(sizeof(struct Forest)); if (forest == NULL) { #ifdef PRINT printf("创建森林失败,开辟内存空间不足!\n"); #endif return NULL; } char* name = malloc(sizeof(char) * 3); name = "LS"; forest->name = name; forest->root = forestArray; setForestFunction(forest); return forest; } //=====↑↑↑=init Forest By Binary Tree=↑↑↑==== |
测试输入图5.24的森林结构LS=(A(B(D,E),C),F(G,H(I),J),K(L)):
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "forest.h" void print(void* data) { struct ForestNode* forestNode = data; printf("结点:%s ", forestNode->data); printf(" 父结点:%d ", forestNode->parent); printf("孩子结点:"); struct ChildNode* child = forestNode->firstChild; while (child != NULL) { printf("%d ", child->index); child = child->next; } printf("\n"); } int main() { while (1) { struct Forest* forest = initForest(); forest->root->foreach(print, forest->root); struct BinaryTree* binaryTree = forest->convertBinaryTree(forest); binaryTree->draw(binaryTree); struct Forest* converForest = binaryTree->convertForest(binaryTree); converForest->root->foreach(print, converForest->root); struct BinaryTree* converTree = converForest->convertBinaryTree(converForest); converTree->draw(converTree); } return 0; } |
5.6.哈夫曼树及其应用
哈夫曼树又称最优树,是一类带权路径长度最短的树,在许多方面有着广泛的应用。
5.6.1.最优二叉树(哈夫曼树)
有关路径的概念在树的概念一节中已作过介绍。在此基础上,再给出路径长度等概念。在两个结点构成的路径上的分支(边)数目称为路径长度,而树根到树中每个结点的路径长度之和称为树的路径长度。完全二叉树就是这种路径长度最短的二叉树。
在许多应用中,常常将树中的结点赋上一个具有某种意义的实数,我们称此实数为该结点的权(weight或叫做权重)。而从树根结点到某结点之间的路径长度与该结点上权的乘积称为该结点的带权路径长度,树中所有叶子结点的带权路径长度之和称为树的带权路径长度,通常记为:

其中, n表示叶子结点个数, wi和li分别表示叶子结点ki的权值和根到ki之间的路径长度。
当在权值为w1, w2,···, wn的n个叶结点构成的所有二叉树中,带权路径长度WPL最小的二叉树称为哈夫曼树或最优二叉树。
例如,假设给定4个叶结点的权值分别为8、5、2和4,可以构造出如图5.25所示的三棵二叉树(当然还可以构造更多的二叉树),它们的带权路径长度分别为:
图5.25 (a): WPL=8×3+5×3+2×1+4×2=49
图5.25 (b): WPL=8×3+5×2+2×3+4×1=44
图5.25 (c): WPL=8×1+5×2+2×3+4×3=36
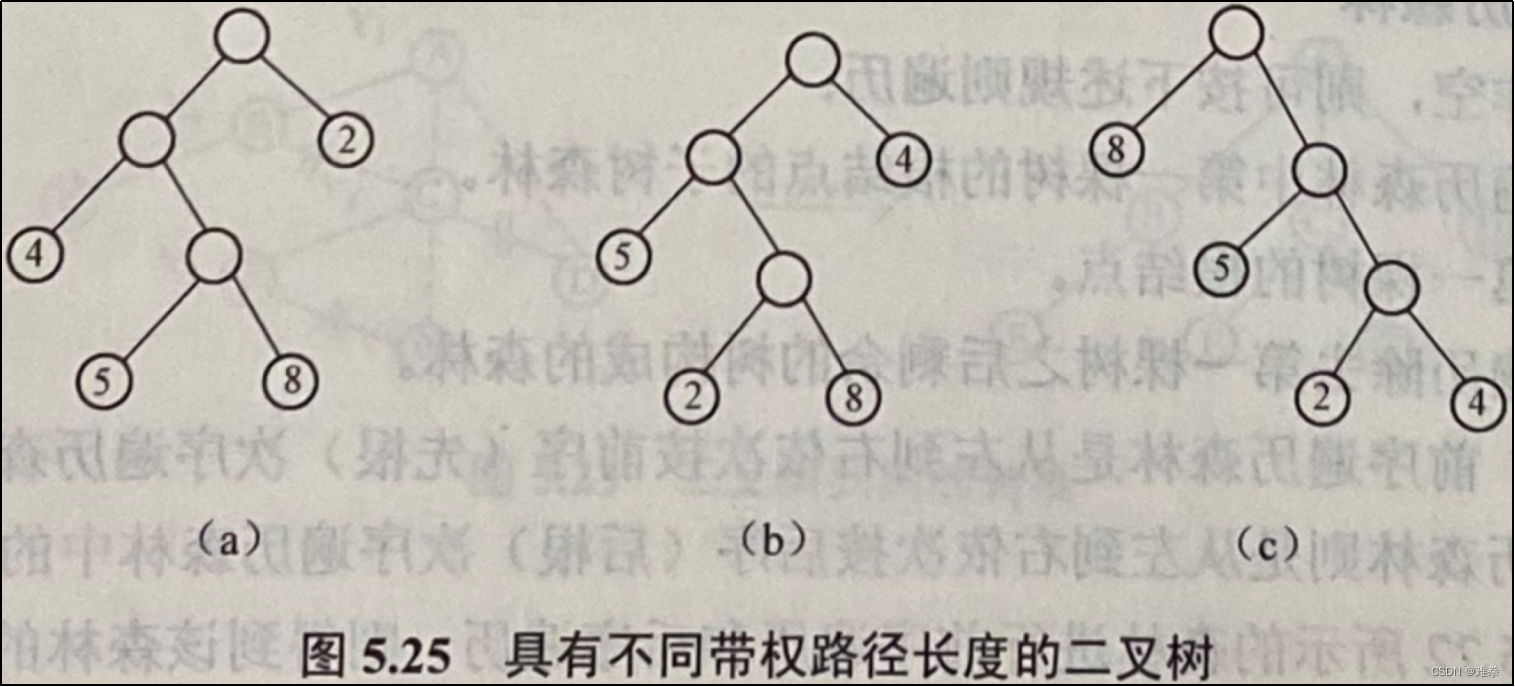
其中,图5.25 (c)所示树的WPL最小,可以验证它就是一棵哈夫曼树,即它的带权路经长度在所有带权值为8、5、2、4的四个叶结点的二叉树中为最小。若叶结点上的权值均相同,其中完全二叉树一定是最优二叉树,否则不是完全二叉树就不一定是最优二叉树。
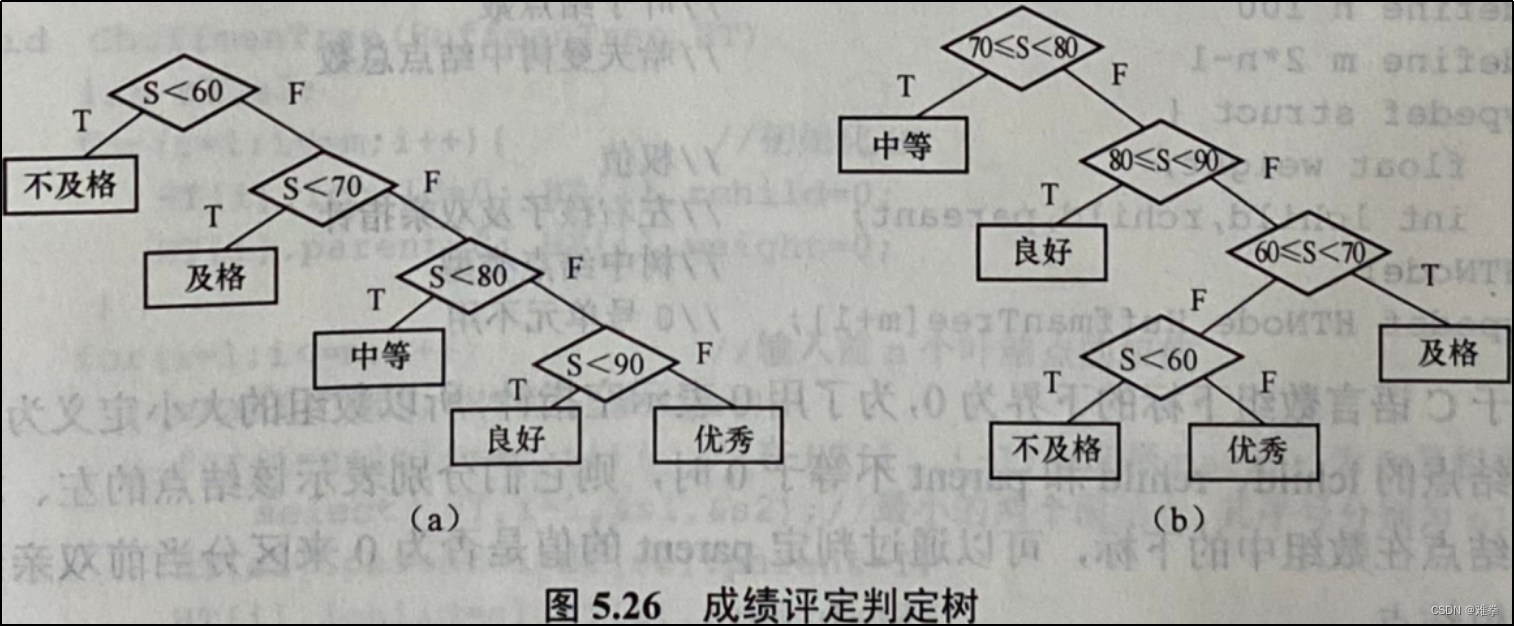
在用算法语言编写应用程序时,经常会遇到判定问题,利用哈夫曼树可以得到最佳的判定算法。例如,编制一个将百分制成绩转换成“优秀"、“良好”、“中等"、“及格”和“不及格”五个等级的程序。显然,此程序的编写是很简单的,只要利用条件判断语句便可实现。用C语言实现如下(设成绩为s):
| if(s<60) grade=”不及格”; else if(s<70) grade=”及格”; else if(s<80) grade=”中等”; else if(s<90) grade=”良好”; else grade=”优秀”; |
该问题的判定树可以用图5.26(a)来表示。如果上述程序需要反复使用,而且每次的输入量都很大,那么应考虑上述程序的质量问题。因为在实际应用中,学生成绩在五个等级的分布是不均匀的。假设其成绩分布的概率如表5.1所示。

用5个百分数作为5个叶结点的权,构造一棵哈夫曼树,可得图5.26 (b)所示的判定过程图。它可使大部分的数据经过较少的比较次数得出结果,可按此判定树写出相应的程序。假设有10000个学生的成绩数据,如果用图5.26(a)所示的判定过程进行处理,则总共需要31 500次比较;若用图5.26 (b)所示的判定过程进行处理,则仅需要20 500次比较。如果需要处理的数据量更多,差距会更大!
1.哈夫曼算法
那么,如何构造一棵哈夫曼树呢?哈夫曼首先提出了构造最优二叉树的方法,所以称其为哈夫曼算法,其基本思想如下:
1.根据与n个权值{ w1, w2, .., wn}对应的n个结点构成n棵二叉树的森林F={T1, T2,...,Tn},其中每棵二叉树Ti都只有一个权值为wi的根结点,其左、右树均为空。
2.在森林F中选出两棵根结点的权值最小的树作为一棵新树的左、右子树,且置新树的附加根结点的权值为其左、右子树上根结点的权值之和。
3.从F中删除这两棵树,同时把新树加入到F中;
4.重复步骤(2)和(3),直到F中只有一棵树为止,此树便是哈夫曼树。例如,图5.25 (c)所示的哈夫曼树按上述算法思想构造的过程如图5.27所示。
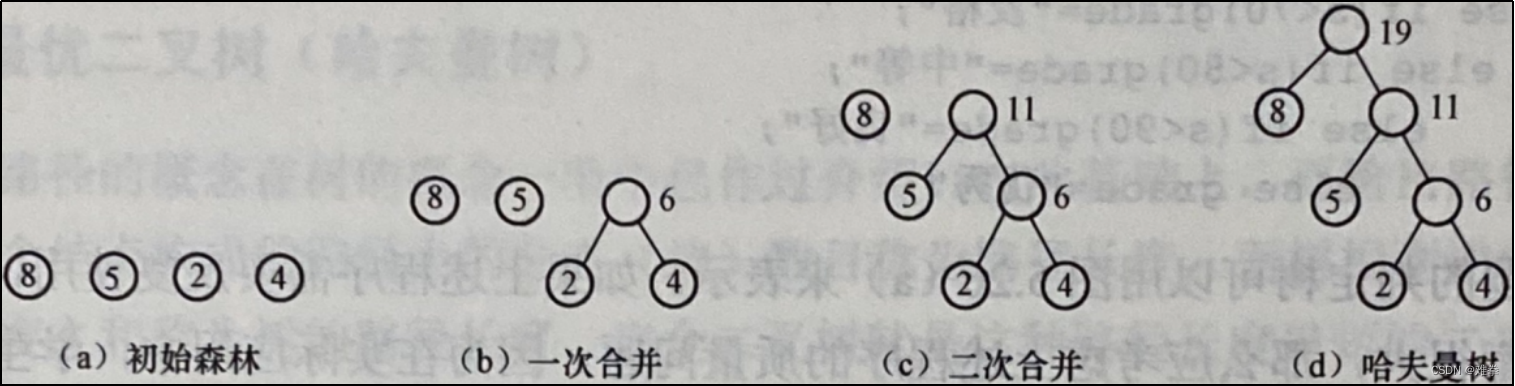
哈夫曼树特点:
1.具有相同带权结点的哈夫曼树不唯一。
2.哈夫曼树中权值越大的叶子离根越近。
3.对于二叉哈夫曼树结点的度数为2或0,没有度为1的结点。
4.包含n棵树的森林要经过n-1次合并才能形成哈夫曼树,共产生n-1个新结点,一共有2n-1个结点,新结点都是具有两个孩子的分支结点。
2.哈夫曼算法的实现
由哈夫曼算法的定义可知,初始森林中共有n棵只含有根结点的二叉树,这是第一步;将当前森林中的两棵根结点权值最小的二叉树,合并成一棵新的二叉树,这是第二步;每合并一次就产生一个新结点,森林中相应减少一棵树。显然要进行n-1次合并,所以共产生n-1个新结点,它们都是具有两个孩子的分支结点。由此可知,最终求得的哈夫曼树中一共有2n-1个结点,其中n个叶结点是初始森林的n个孤立结点。并且哈夫曼树中没有度数为1的分支结点,可用一个大小为2n-1的一维数组来存储哈夫曼树中的结点。因此,哈夫曼树的存储结构描述为:
| struct HuffmanTree { int weight; int parent; int leftChild; int rightChild; }; |
由于C语言数组下标已0为起始点,用-1表示空指针。树中某结点的leftChild, rightChild和parent不等于-1时,则它们分别表示该结点的左、右孩子和双亲结点在数组中的下标,可以通过判定parent的值是否为-1来区分当前双亲结点是根与非根结点。
在有了上述存储结构定义后,实现哈夫曼算法可大致描述为以下几步:
- 将哈夫曼树数组中的2n-1个结点初始化:将各结点中的三个指针均置为空(即置为-1值),权值置为0值。
- 读入n个权值,存入数组的前n个元素中,它们是初始森林中n个孤立的根结点上的权值。
- 对森林中的树进行n-1次合并,共产生n-1个新结点,依次存入数组的第i个元素中(size≤i≤capacity),每次合并的的步骤是:
①在当前森林的所有结点中选取具有最小权值和次小权值的两个根结点,分别记住这两个根结点在数组中的下标;
②将根为huffmanTree[*minOneIndex]和huffmanTree[*minTwoIndex]的两棵树合并,使其成为新结点huffmanTree[i]的左右孩子,得到一棵以新结点huffmanTree[i]为根的二叉树,同时修改huffmanTree[*minOneIndex]和huffmanTree[*minTwoIndex]的双亲域parent,使其指向新结点huffmanTree[i],并将huffmanTree[*minOneIndex]和huffmanTree[*minTwoIndex]的权值之和作为新结点huffmanTree[i]的权值。
先按第①步,给出选择两个最小权值根结点并返回其在数组中的下标minOneIndex和minTwoIndex的选则算法。
| void select(struct HuffmanTree* huffmanTree, int size, int* minOneIndex, int* minTwoIndex) { int min = INT_MAX; for (int i = 0; i < size; i++) { if (huffmanTree[i].weight < min && huffmanTree[i].parent == -1) { *minOneIndex = i; min = huffmanTree[i].weight; } } min = INT_MAX; for (int i = 0; i < size; i++) { if (huffmanTree[i].weight < min && huffmanTree[i].parent == -1 && i != *minOneIndex) { *minTwoIndex = i; min = huffmanTree[i].weight; } } } |
在有了选择函数的定义之后,上述构造哈夫曼树的算法可以进一步用C语言描述如下:
| void huffmanTree(struct HuffmanTree* huffmanTree) { int size = 8, capacity = 15; for (int i = 0; i < capacity; i++) { huffmanTree[i].weight = 0; huffmanTree[i].parent = -1; huffmanTree[i].leftChild = -1; huffmanTree[i].rightChild = -1;
} for (int i = 0; i < size; i++) { scanf("%d", &huffmanTree[i].weight); } int* minOneIndex = malloc(sizeof(int)); int* minTwoIndex = malloc(sizeof(int)); for (int i = size; i < capacity; i++) { select(huffmanTree, i, minOneIndex, minTwoIndex); huffmanTree[*minOneIndex].parent = i; huffmanTree[*minTwoIndex].parent = i; huffmanTree[i].leftChild = *minOneIndex; huffmanTree[i].rightChild = *minTwoIndex; huffmanTree[i].weight = huffmanTree[*minOneIndex].weight + huffmanTree[*minTwoIndex].weight; } } |
【例5.5】某种系统在通信中只可能出现8中字符:a,b,c,d,e,f,g,h。它们在电文出现的频率分别为: 0.06, 0.15, 0.07, 0.09, 0.16, 0.27, 0.08, 0.12,现以其频率的百分数作为权值,即6, 15, 7, 9, 16, 27, 8, 12建立哈夫曼树。按上述算法,此树的建立过程如表5.2所示。

此表仅说明数组huffmanTree[0..14]中权值域在算法执行过程中的变化情况。因为n=8,所以一共合并7次。表中第二行表示合并前的初始状态,数组中只有前8个叶结点的权,其中带方框的是当前两个最小的权,产生一个新结点作为这两个权所对应结点huffmanTree[0]和huffmanTree[2]的双亲,得到表中第三行所表示的情形。由于权6和7的结点已被合并有了双亲结点,其权值为13,存储在huffmanTree[8].weight中,因此它们不再是根结点,用方括号括起来,这便是一次合并的结果。在一次合并的基础上,继续寻找两个具有最小权值的根结点,即表中第三行上带方框的权9和8,再把它们合并后得到第四行. ...依次进行下去,最后一个数组元素huffmanTree[14]就是所求哈夫曼树的根结点。按此算法构造的哈夫曼树如图5.28所示。

测试:
| int main() { struct HuffmanTree* huffmanArray = malloc(sizeof(struct HuffmanTree) * 15); huffmanTree(huffmanArray); for (int i = 0; i < 15; i++) { printf("index=%d ", i); printf("权值%d ", huffmanArray[i].weight); printf("父结点%d ", huffmanArray[i].parent); printf("左子树%d ", huffmanArray[i].leftChild); printf("右子树%d", huffmanArray[i].rightChild); printf("\n"); } return 0; } |
运算结果:
| 6 15 7 9 16 27 8 12 index=0 权值6 父结点8 左子树-1 右子树-1 index=1 权值15 父结点11 左子树-1 右子树-1 index=2 权值7 父结点8 左子树-1 右子树-1 index=3 权值9 父结点9 左子树-1 右子树-1 index=4 权值16 父结点11 左子树-1 右子树-1 index=5 权值27 父结点13 左子树-1 右子树-1 index=6 权值8 父结点9 左子树-1 右子树-1 index=7 权值12 父结点10 左子树-1 右子树-1 index=8 权值13 父结点10 左子树0 右子树2 index=9 权值17 父结点12 左子树6 右子树3 index=10 权值25 父结点12 左子树7 右子树8 index=11 权值31 父结点13 左子树1 右子树4 index=12 权值42 父结点14 左子树9 右子树10 index=13 权值58 父结点14 左子树5 右子树11 index=14 权值100 父结点-1 左子树12 右子树13 |
以上例子可以很明显的看出来,这种哈夫曼的计算与存储算法并不是很方便,它需要同时借助于数组与结构体才能将哈夫曼展示出来,并且要提前知道元素的个数。其实哈夫曼树也是可以使用二叉链表的方式存储,而且不会受到元素个数的约束。
下面输入元素值,构建一个哈夫曼树的二叉链表存储结构。其构造方法为:
1.解析输入值,使用动态数组存储起来,在存储的同时使用冒泡排序改变数组中元素为升序存储顺序,这样索引为0和1的两个元素的权值即为当前元素中权值最小的两个元素。
2.从最小权值的两个元素开始,依次构建二叉链表树。
3.每次由两个最小权值建立一个新权值的二叉链表,都将当前动态数组中权值最小的两个元素(即下标0和1的元素)删除,然后将新建的二叉链表存入动态数组中。
4.最后动态数组中只剩下一个元素,即为创建好的哈夫曼二叉链表存储结构。
这样构建的哈夫曼树其叶子结点存储字符编码信息,非叶子结点存储权值信息。
在二叉链表树的生成算法binaryTree.c(5.4.3小节)中添加哈夫曼树链式存储的实现:
| struct HuffmanArrayNode { char* data; int weight; struct BinaryNode* binaryNode; }; int sortHuffmanNode(void* data, void* ArrayData) { struct HuffmanArrayNode* front = data; struct HuffmanArrayNode* array = ArrayData; if (front->weight < array->weight) { return 1; } return 0; } struct ArrayList* createHuffmanArrayNode(struct HuffmanTree* huffmanTree) { int size = huffmanTree->leafCount; struct HuffmanNode* root = huffmanTree->root; struct HuffmanCode* huffmanCode = huffmanTree->huffmanCode; struct ArrayList* arrayList = initArrayList(5); for(int i = 0; i < size; i++) { struct HuffmanArrayNode* huffmanNode = malloc(sizeof(struct HuffmanArrayNode)); if (huffmanNode == NULL) { #if PRINT printf("初始化哈夫曼,内存空间不足!\n"); #endif return NULL; } huffmanNode->data = huffmanCode[i].code; huffmanNode->weight = root[i].weight; huffmanNode->binaryNode = NULL; arrayList->addSort(huffmanNode, sortHuffmanNode, arrayList); } return arrayList; } int compareHuffmanNode(void* firstData, void* secondData) { if (firstData == secondData) { return 1; } return 0; } struct BinaryNode* createHuffmanTree(struct ArrayList* huffmanArrayList) { int size = huffmanArrayList->size(huffmanArrayList); struct BinaryNode* root = NULL; for (int i = 0; i < size - 1; i++) { struct HuffmanArrayNode* leftWeight = huffmanArrayList->get(0, huffmanArrayList); if (leftWeight->binaryNode == NULL) { // char* leftData = malloc(sizeof(char) * 10); struct BinaryNode* leftNode = malloc(sizeof(struct BinaryNode)); if (leftNode == NULL) { #if PRINT printf("构建哈夫曼结点,内存空间不足!\n"); #endif return NULL; } // sprintf(leftData, "%d", leftWeight->weight); leftNode->data = leftWeight->data; leftNode->left = NULL; leftNode->right = NULL; leftWeight->binaryNode = leftNode; } struct HuffmanArrayNode* rightWeight = huffmanArrayList->get(1, huffmanArrayList); if (rightWeight->binaryNode == NULL) { // char* rightData = malloc(sizeof(char) * 10); struct BinaryNode* rightNode = malloc(sizeof(struct BinaryNode)); if (rightNode == NULL) { #if PRINT printf("构建哈夫曼结点,内存空间不足!\n"); #endif return NULL; } // sprintf(rightData, "%d", rightWeight->weight); rightNode->data = rightWeight->data; rightNode->left = NULL; rightNode->right = NULL; rightWeight->binaryNode = rightNode; } int weight = leftWeight->weight + rightWeight->weight; char* data = malloc(sizeof(char) * 10); root = malloc(sizeof(struct BinaryNode)); if (root == NULL) { #if PRINT printf("构建哈夫曼结点,内存空间不足!\n"); #endif return NULL; } sprintf(data, "%d", weight); root->data = data; root->left = leftWeight->binaryNode; root->right = rightWeight->binaryNode; huffmanArrayList->removeByData(leftWeight, compareHuffmanNode, huffmanArrayList); free(leftWeight); leftWeight = NULL; huffmanArrayList->removeByData(rightWeight, compareHuffmanNode, huffmanArrayList); free(rightWeight); rightWeight = NULL; struct HuffmanArrayNode* huffmanNode = malloc(sizeof(struct HuffmanArrayNode)); if (huffmanNode == NULL) { #if PRINT printf("添加构建的哈夫曼,内存空间不足!\n"); #endif return NULL; } huffmanNode->data = NULL; huffmanNode->weight = weight; huffmanNode->binaryNode = root; huffmanArrayList->addSort(huffmanNode, sortHuffmanNode, huffmanArrayList); } huffmanArrayList->ruin(huffmanArrayList); return root; } int depthHuffmanTree(struct BinaryNode* node) { if (node == NULL) { return 0; } int left = depthHuffmanTree(node->left); int right = depthHuffmanTree(node->right); return left > right ? left + 1 : right + 1; } void convertHuffmanBinaryTree(struct HuffmanTree* huffmanTree) { if (huffmanTree == NULL || huffmanTree->root == NULL) { #if PRINT printf("哈夫曼树为空不存在!\n"); #endif return; } if (huffmanTree->huffmanCode == NULL) { #if PRINT printf("哈夫曼树未编译编码,跳转编译!\n"); #endif compileHuffmanCode(huffmanTree); } struct BinaryTree* binaryTree = malloc(sizeof(struct BinaryTree)); if (binaryTree == NULL) { #if PRINT printf("创建二叉树失败,内存空间不足!\n"); #endif return; } binaryTree->root = createHuffmanTree(createHuffmanArrayNode(huffmanTree)); binaryTree->depth = depthHuffmanTree(binaryTree->root); setBinaryTreeFunction(binaryTree); huffmanTree->huffmanBinaryTree = binaryTree; } |
测试输入6, 15, 7, 9, 16, 27, 8, 12建立哈夫曼树:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "binaryTree.h" int main() { struct BinaryTree* binaryTree = initHuffmanTree(); binaryTree->draw(binaryTree); return 0; } |
运行结果与例5.5一致:
| 请输入构建顺序哈夫曼树的8个权值: 6 15 7 9 16 27 8 12 哈夫曼树未编译编码,跳转编译! 请按权值顺序输入8个编码值: A B C D E F G H 100 / \ 42 58 / \ / \ 17 25 F 31 / \ / \ / \ / \ G D H 13 * * B E / \ / \ / \ / \ / \ / \ / \ / \ * * * * * * A C * * * * * * * * / / / / / / / / / / / / / / / / \ |
5.6.2.哈夫曼编码
在当今这样一个信息爆炸的时代,如何采用有效的数据压缩技术来节省数据文件的存储空间和计算机网络的传送时间,已越来越引起人们的重视。哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。
利用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。树中从根到每个叶子都有一条路径,对路径上的各分支约定指向左子树的分支表示"0"码,指向右子树的分支表示"1"码,取每条路径上的"0"或"1"的序列作为各个叶子结点对应的字符编码,这就是哈夫曼编码。
通常数据压缩的过程称为编码,反之,解压缩的过程称为解码。电报通信是由传递文字的二进制码组成的字符串。例如,字符串"ABCDBACA"有四种字符,只需要2位二进制码表示即可: A,B,C,D分别为00,01,10.11,那么,上述串编码为0001101101001000,长为16位,译码时两位一分即可。但在信息传递时,总希望总长能尽可能地短,即采用最短码。如果对每个字符设计长度不等的编码,且要让电文中出现次数较多的字符用尽可能短的编码,那么传送电文的总长便可减短。比如,设计字母A,B,C和D的编码分别为0、1、00和01,则上述8个字符的电文可转换成总长为11的字符串“01000110001"。这样编码总长虽然短了,但是这样的电文无法译码。例如编码串的前4位"0100"既可以译成“ABAA",也可以译成“ABC",还可以译为“DC"等。
因此,若设计一种长短不等的编码,则必须保证任一字符的编码都不是另一个字符编码的前缀,这种编码称为前缀编码。
可以利用二叉树来设计二进制的前缀编码。如图5.29 (a)所示的哈夫曼树,其左分支表示字符“0",右分支表示字符"1",则以根结点到叶结点路径上的分支字符组成的串作为该叶结点的字符编码,可得到字符a、b、c、d的二进制前缀编码分别为: 0,10,110, 111。 
以例5.5所构造的哈夫曼树为例,将其左分支标上字符"0",右分支标上字符"1",如图5.29 (b)所示。从该树中,可以很容易得该例通信电文中八种字符的前缀编码:a (0110), b (110), с (0111), d (000), е (111), f (10), g (001), h (010)。
假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长为∑WiLi。若将此对应到二叉树上, Wi为叶结点的权, Li为根结点到叶结点的路径长度。那么, ∑WiLi恰好为二叉树上带权路径长度。
因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作为权构造一棵哈夫曼树,由哈夫曼树求得的编码就是哈夫曼编码,哈夫曼编码是一个前缀编码,是最优前缀编码。
我们知道,在哈夫曼树的顺序存储结构中,因为增加了结点与其双亲的链接,所以在具体实现求哈夫曼编码时,可以很容易的从子结点找到根节点的路径。由此可以得到一个求哈夫曼编码的算法:
从哈夫曼树的叶子结点huffmanTree[i]出发,一直向上回溯到根结点。回溯过程中,利用双亲指针parent找到叶子结点huffmanTree[i]的双亲huffmanTree[p],再利用该双亲的指针域leftChild和rightChild,可知huffmanTree[i]是huffmanTree[p]的左孩子还是右孩子,若是左孩子则生成代码0,否则生成代码1;然后再以huffmanTree[p]为出发点,重复上述过程,直至找到根结点为止。
显然,这样生成的代码序列与要求的编码次序相反,我们可以利用动态数组,每获取到一个代码0或1就通过头插法,插入动态数组中,直至找到根结点为止,将动态数组中记录的编码赋值给哈夫曼编码存储起来,动态数组因为使用的是头插法,0和1的编码顺序正好是从根节点到叶子结点的路径。
哈夫曼编码的存储结构与生成算法封装在5.4.3小节的二叉树算法中,其核心算法描述如下:
| void initHuffmanCode(struct HuffmanCode* huffmanCode, int leafCount) { printf("请按权值顺序输入%d个编码值:\n", leafCount); char ch; scanf("%c", &ch); for (int i = 0; i < leafCount; i++) { while (ch == ' ' || ch == '\n') { scanf("%c", &ch); } char* chr = malloc(sizeof(char) * 2); chr[0] = ch; chr[1] = '\0'; huffmanCode[i].code = chr; huffmanCode[i].bits = NULL; scanf("%c", &ch); } } void huffmanEncoding(struct HuffmanTree* huffmanTree, struct HuffmanCode* huffmanCode) { struct HuffmanNode* huffmanNode = huffmanTree->root; int index = 0, parentIndex = 0; for (int i = 0; i < huffmanTree->leafCount; i++) { index = parentIndex = i; struct ArrayList* list = initArrayList(5); do { parentIndex = huffmanNode[index].parent; if (huffmanNode[parentIndex].leftChild == index) { char* zero = malloc(sizeof(char)); if (zero == NULL) return; *zero = 48; list->insert(0, zero, list); } else { char* zero = malloc(sizeof(char)); if (zero == NULL) return; *zero = 49; list->insert(0, zero, list); } index = parentIndex; } while (huffmanNode[index].parent != -1); huffmanCode[i].bits = list->toString(list); list->ruin(list); } } void compileHuffmanCode(struct HuffmanTree* huffmanTree) { if (huffmanTree == NULL || huffmanTree->root == NULL) { #if PRINT printf("哈夫曼树为空不存在!\n"); #endif return; } huffmanTree->huffmanCode = malloc(sizeof(struct HuffmanCode) * huffmanTree->leafCount); if (huffmanTree->huffmanCode == NULL) { #if PRINT printf("构建哈夫曼编码失败,内存空间不足!\n"); #endif return; } initHuffmanCode(huffmanTree->huffmanCode, huffmanTree->leafCount); huffmanEncoding(huffmanTree, huffmanTree->huffmanCode); } char* encodeHuffmanCode(char* soundCode, struct HuffmanTree* huffmanTree) { if (huffmanTree == NULL || huffmanTree->root == NULL || huffmanTree->huffmanCode == NULL) { #if PRINT printf("哈夫曼树为空不存在或者哈夫曼树未编译编码!\n"); #endif return NULL; } struct ArrayList* binaryCode = initArrayList(5); struct HuffmanCode* huffmanCode = huffmanTree->huffmanCode; int size = huffmanTree->leafCount; while (*soundCode != '\0') { for (int i = 0; i < size; i++) { if (*soundCode == *huffmanCode[i].code) { char* bits = huffmanCode[i].bits; while (*bits != '\0') { char* ch = malloc(sizeof(char) * 2); if (ch == NULL) { } ch[0] = bits[0]; ch[1] = '\0'; binaryCode->insert(binaryCode->size(binaryCode), ch, binaryCode); bits++; } break; } } soundCode++; } char* ciphertext = binaryCode->toString(binaryCode); binaryCode->ruin(binaryCode); return ciphertext; } |
若以图5.29 (b)所示的哈夫曼树为例,则上述算法求出的哈夫曼编码如图5.30所示。
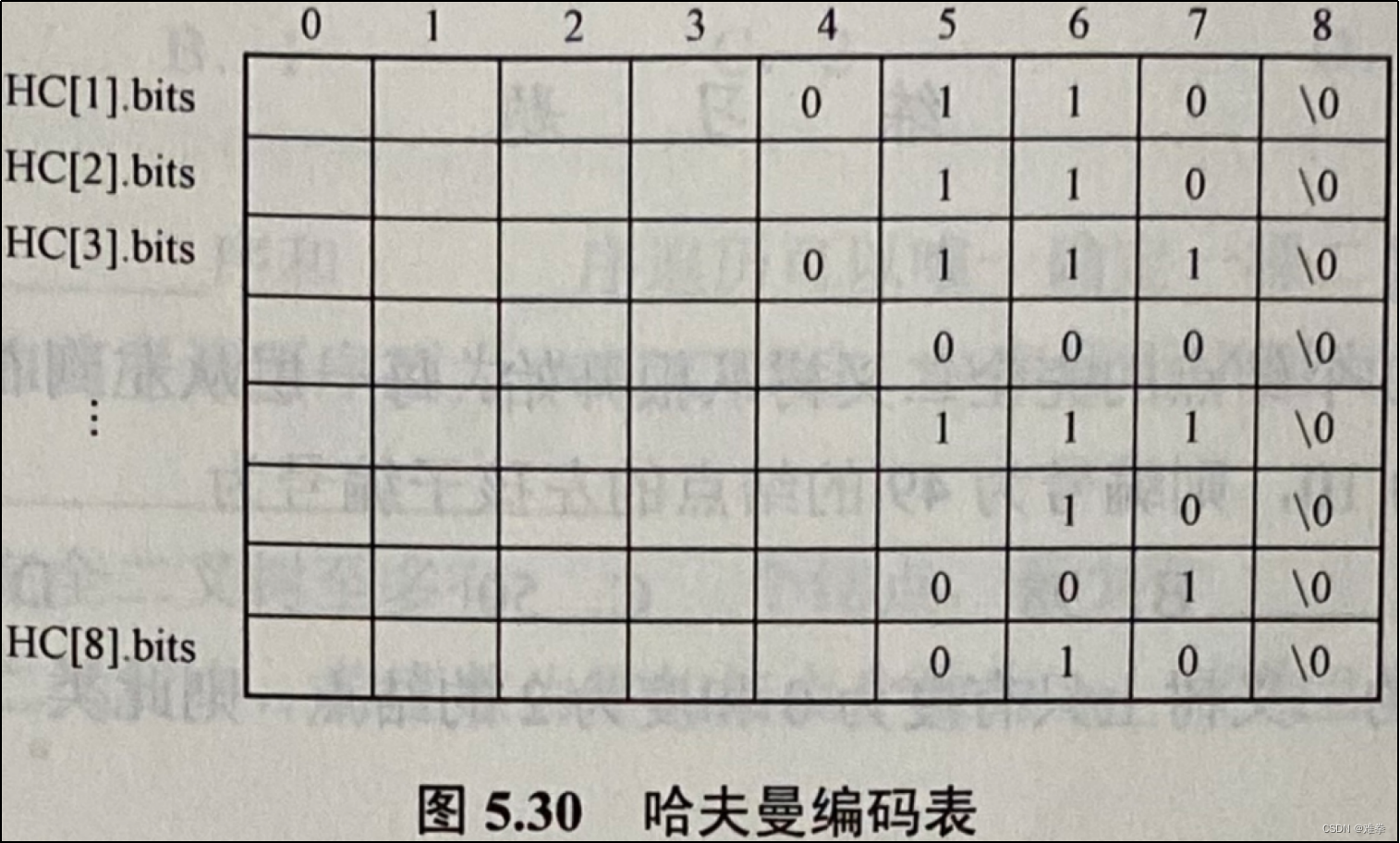
测试哈夫曼编码输入5.29 (b)所示的哈夫曼树:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "binaryTree.h" int main() { struct HuffmanTree* huffmanTree = initHuffmanTreeArray(8); huffmanTree->compile(huffmanTree); huffmanTree->foreach(huffmanTree); char* ciphertext = huffmanTree->encode("ABBDCCGHAABBGGD", huffmanTree); printf("哈夫曼密文:%s\n", ciphertext); return 0; } |
测试结果与图5.30相同。
| 请输入构建顺序哈夫曼树的8个权值: 6 15 7 9 16 27 8 12 请按权值顺序输入8个编码值: A B C D E F G H index=0 权值6 父结点8 左子树-1 右子树-1 index=1 权值15 父结点11 左子树-1 右子树-1 index=2 权值7 父结点8 左子树-1 右子树-1 index=3 权值9 父结点9 左子树-1 右子树-1 index=4 权值16 父结点11 左子树-1 右子树-1 index=5 权值27 父结点13 左子树-1 右子树-1 index=6 权值8 父结点9 左子树-1 右子树-1 index=7 权值12 父结点10 左子树-1 右子树-1 index=8 权值13 父结点10 左子树0 右子树2 index=9 权值17 父结点12 左子树6 右子树3 index=10 权值25 父结点12 左子树7 右子树8 index=11 权值31 父结点13 左子树1 右子树4 index=12 权值42 父结点14 左子树9 右子树10 index=13 权值58 父结点14 左子树5 右子树11 index=14 权值100 父结点-1 左子树12 右子树13 哈夫曼编码表: index=0 字符编码:A 二进制编码:0110 index=1 字符编码:B 二进制编码:110 index=2 字符编码:C 二进制编码:0111 index=3 字符编码:D 二进制编码:001 index=4 字符编码:E 二进制编码:111 index=5 字符编码:F 二进制编码:10 index=6 字符编码:G 二进制编码:000 index=7 字符编码:H 二进制编码:010 哈夫曼密文:01101101100010111011100001001100110110110000000001 |
5.6.3.哈夫曼译码
哈夫曼树也可用来译码。与编码过程相反,译码过程是从树根结点出发,逐个读入电文中的二进制码。若读入0,则走向左孩子,否则走向右孩子。一旦到达叶结点, huffmanTree[i]便译出相应的字符,然后重新从根出发继续译码,直到二进制电文结束。
哈夫曼的二叉链式存储结构可以很方便的利用树的路径,从根节点找到唯一的叶子结点,叶子结点上存储着译码后的字符数据。
哈夫曼译码核心代码实现(完整代码见5.4.3小节二叉树算法):
| char recursionDecodeCiphertext(char** ciphertext, struct BinaryNode* huffmanBinaryNode) { if (huffmanBinaryNode->left == NULL && huffmanBinaryNode->right == NULL) { // 这里二叉链表存储的是字符串 而这里只取第一个字符是没有问题的 因为哈夫曼编码字符是单个的! return huffmanBinaryNode->data[0]; } if (**ciphertext == 48) { (*ciphertext)++; return recursionDecodeCiphertext(ciphertext, huffmanBinaryNode->left); } else { (*ciphertext)++; return recursionDecodeCiphertext(ciphertext, huffmanBinaryNode->right); } } char* decodeHuffmanCode(char* ciphertext, struct HuffmanTree* huffmanTree) { if (huffmanTree == NULL || huffmanTree->root == NULL || huffmanTree->huffmanBinaryTree == NULL) { #if PRINT printf("哈夫曼树为空不存在或者哈夫曼树未编译译码!\n"); #endif return NULL; } struct ArrayList* soundArray = initArrayList(5); struct BinaryNode* huffmanBinaryNode = huffmanTree->huffmanBinaryTree->root; while (*ciphertext != '\0') { char* charCode = malloc(sizeof(char)); if (charCode == NULL) { #if PRINT printf("破译哈夫曼编码内存空间不足!\n"); #endif return NULL; } *charCode = recursionDecodeCiphertext(&ciphertext, huffmanBinaryNode); soundArray->insert(soundArray->size(soundArray), charCode, soundArray); } char* sourceCode = soundArray->toString(soundArray); soundArray->ruin(soundArray); return sourceCode; } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include <string.h> #include "binaryTree.h" int main() { struct HuffmanTree* huffmanTree = initHuffmanTreeArray(8); huffmanTree->compile(huffmanTree); huffmanTree->foreach(huffmanTree); char* ciphertext = huffmanTree->encode("ABBDCCGHAABBGGD", huffmanTree); printf("哈夫曼密文:%s\n", ciphertext); huffmanTree->convert(huffmanTree); struct BinaryTree* binaryTree = huffmanTree->huffmanBinaryTree; binaryTree->draw(binaryTree); char* sourceCode = huffmanTree->decode("01101101100010111011100001001100110110110000000001", huffmanTree); printf("哈夫曼源文:%s\n", sourceCode); return 0; } |
运行结果:
| 请输入构建顺序哈夫曼树的8个权值: 6 15 7 9 16 27 8 12 请按权值顺序输入8个编码值: A B C D E F G H index=0 权值6 父结点8 左子树-1 右子树-1 index=1 权值15 父结点11 左子树-1 右子树-1 index=2 权值7 父结点8 左子树-1 右子树-1 index=3 权值9 父结点9 左子树-1 右子树-1 index=4 权值16 父结点11 左子树-1 右子树-1 index=5 权值27 父结点13 左子树-1 右子树-1 index=6 权值8 父结点9 左子树-1 右子树-1 index=7 权值12 父结点10 左子树-1 右子树-1 index=8 权值13 父结点10 左子树0 右子树2 index=9 权值17 父结点12 左子树6 右子树3 index=10 权值25 父结点12 左子树7 右子树8 index=11 权值31 父结点13 左子树1 右子树4 index=12 权值42 父结点14 左子树9 右子树10 index=13 权值58 父结点14 左子树5 右子树11 index=14 权值100 父结点-1 左子树12 右子树13 哈夫曼编码表: index=0 字符编码:A 二进制编码:0110 index=1 字符编码:B 二进制编码:110 index=2 字符编码:C 二进制编码:0111 index=3 字符编码:D 二进制编码:001 index=4 字符编码:E 二进制编码:111 index=5 字符编码:F 二进制编码:10 index=6 字符编码:G 二进制编码:000 index=7 字符编码:H 二进制编码:010 哈夫曼密文:01101101100010111011100001001100110110110000000001 100 / \ 42 58 / \ / \ 17 25 F 31 / \ / \ / \ / \ G D H 13 * * B E / \ / \ / \ / \ / \ / \ / \ / \ * * * * * * A C * * * * * * * * / / / / / / / / / / / / / / / / \ 哈夫曼源文:ABBDCCGHAABBGGD |
小结
树也是许多重要数据结构的基础。本章首先介绍了一般树和二叉树的基本概念。在一棵二叉树中,每个结点最多只有两个子结点,所以对二叉树运算的算法比较简单易解。人们经常把一般树的数据结构转换成二叉树形式。本章还主要介绍了四种不同的遍历二叉树算法,前三种算法的主要区别在于对一个结点本身与它的左右子树中结点的处理采用了不同的次序,而层次遍历与其他都不同。遍历二叉树是本章的一个重点。另一个重点就是使用哈夫曼算法生成哈夫曼树和构造哈夫曼编码。要求大家能够熟练掌握四种次序遍历二叉树的算法,并能灵活运用遍历算法,实现二叉树的其他运算以及解决简单的实际应用问题,这也是本章的难点所在。