package com.immooc.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Encoders, SparkSession}
object DataSetTest {
case class Person(name:String, age:Long)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("DataSetTest")
val ssc = new SparkContext(sparkConf)
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
import spark.implicits._
val df = spark.read.json("file:///usr/local/Cellar/spark-2.3.0/examples/src/main/resources/people.json")
val peopleDS = df.as[Person]
peopleDS.map(line => (line.name, line.age)).show()
//peopleDS.show()
spark.close()
}
}
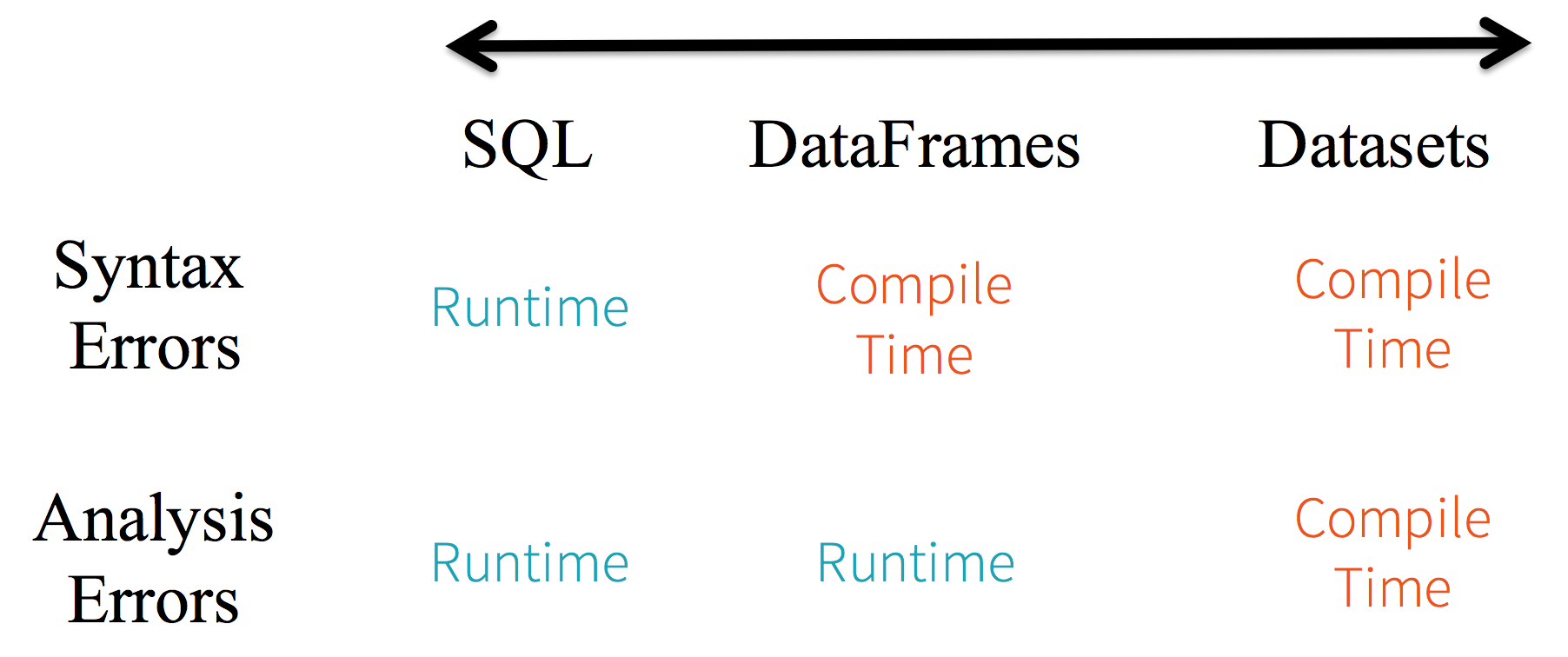
dataset 主要是强类型的。