Python爬虫技术系列-04Selenium库的使用
1 Selenium库基本使用
1.1 Selenium库安装
- 安装Selenium:
pip install selenium==3.141.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
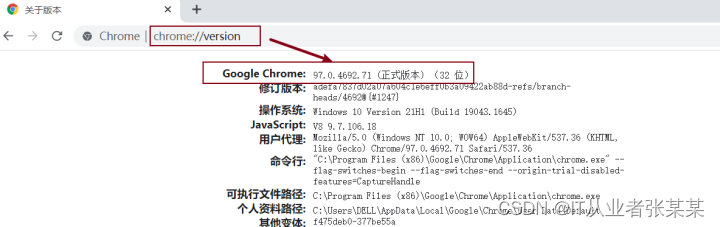
- 安装selenium库之后,还要安装浏览器,一般本地都已经安装完毕,本书采用chrome浏览器,打开浏览器,在地址栏输入Chrome://version,可以查看到浏览器的版本,如下图所示:
- 确定版本后,可以下载对应的驱动。
Selenium支持多种浏览器驱动,包括Chrome,opera,safari,firefox。为对应chrome浏览器,本例选用chrome驱动,
查看chrome驱动:
在浏览器的地址栏,输入chrome://version/,回车后即可查看到对应版本
chrome://version/
我电脑的版本为:
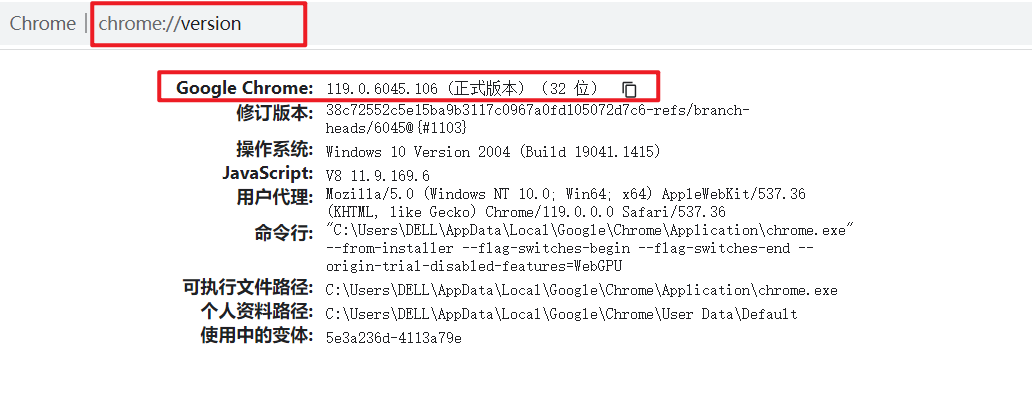
驱动的下载地址为
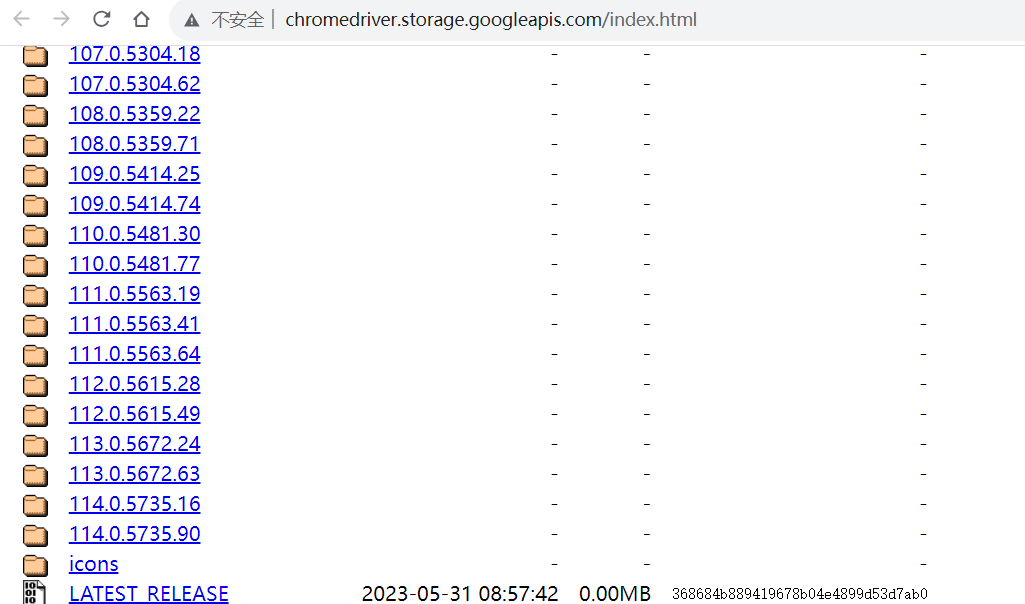
1.浏览器驱动官网:
http://chromedriver.storage.googleapis.com/index.html
2.淘宝镜像网站(推荐):
http://npm.taobao.org/mirrors/chromedriver/
在114版本前的驱动可以直接在上面的地址获取
针对119.0.x的版本驱动需要在
https://googlechromelabs.github.io/chrome-for-testing/
中下载
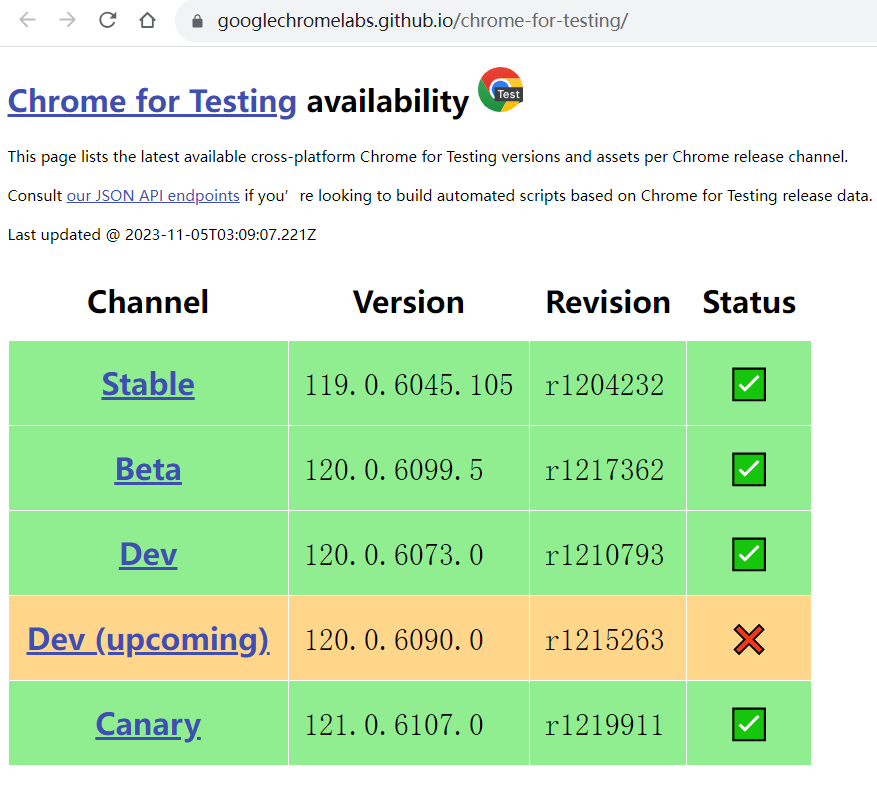

选择对应版本驱动chromedriver.exe,下载到本地,放在工程路径下即可。
1.2 Selenium库介绍
Selenium包含一系列工具和库,这些工具和库支持web浏览器的自动化。Selenium库最初用于自动化测试,但也可以应用数据爬取的场景。
有的网页中的信息需要执行js才能显现,动态网页中, 通常只会更新局部的Html元素, webdriver会很好的帮助用户快速定位这些元素,最终目的是通过提供精心设计的面向对象API来解决现代高级网页中的测试难题。动态网页的存在导致requests库爬取到的源代码与浏览器端看到的数据不一致,这种情况可以通过selenium进行爬取,Selenium会模拟浏览器,爬取执行 js 后的网页数据,实现“所见即所得”。尽管Selenium爬取数据的效率要低很多,但在一些不易爬取的网页中,有着神奇的效果。
2 Selenium库的使用
2.1 各个版本的区别
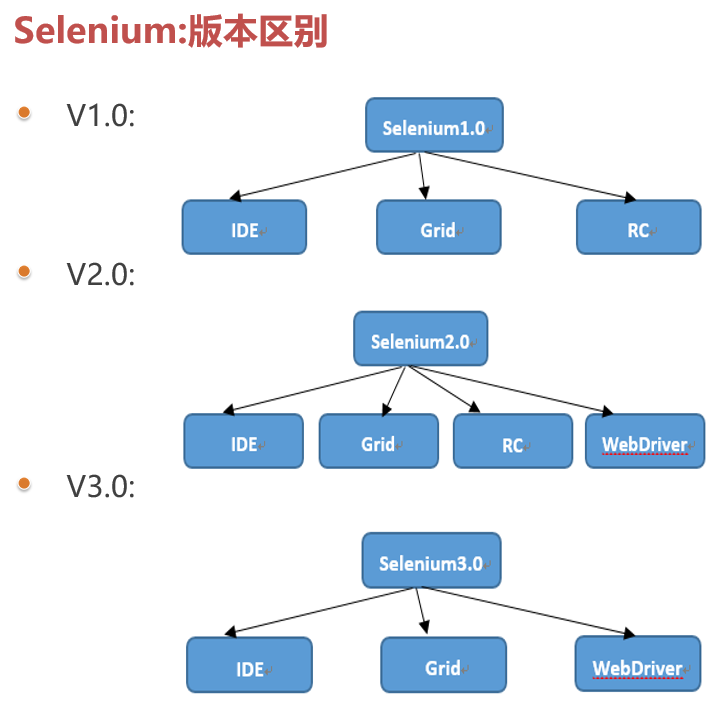
Selenium 1.0 = Selenium IDE + Selenium Grid + Selenium RC
Selenium 2.0 = Selenium 1.0 + WebDriver
Selenium 3.0 = Selenium 2.0 - Selenium RC(Remote Control)
2.1.1 Selenium IDE介绍与使用
Selenium IDE 是作为 Selenium 在浏览器 Firefox 和 Chrome 的插件,用于记录、重放测试脚本,并且脚本也可以导出到 C#,Java,Ruby 或 Python 等编程语言。github 地址:https://github.com/SeleniumHQ/selenium-ide
Selenium IDE 负责录制、回放脚本,模拟用户对页面的真实操作
使用的大致流程:
1.在firefox或chrome中按住拓展插件
以firefox浏览器为例
添加后,就可以使用Selenium IDE了
具体参考:浏览器自动化利器Selenium IDE使用指南
2.1.2 Selenium Grid介绍与使用
Selenium Grid 用于分布式自动化测试,通过控制多台机器、多个浏览器并行执行测试用例,在测试用例比较多的情况下比较实用。
① Selenium Grid 是Selenium套件的一部分,它专门用于并行运行多个测试用例在不同的浏览器、操作系统和机器上。
② Selenium Grid 主要使用 master-slaves 或者 hub-nodes 理念 :一个 master/hub 和多个基于 master/hub 注册的子节点 slaves/nodes 。
当我们在master上基于不同的浏览器/系统运行测试用例时,master将会将测试用例分发给适当的node运行。(当然也可以作为兼容性测试工具将测试用例运行在不同的web浏览器上)
③
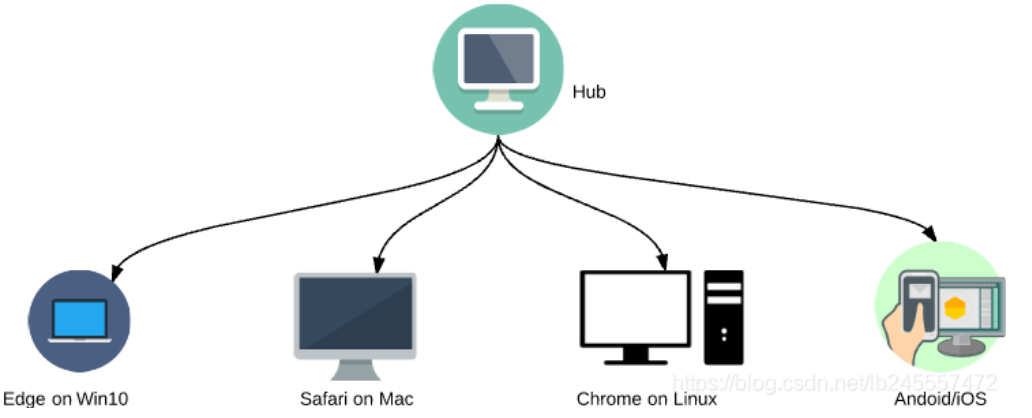
④ selenium Grid 主要的作用:实现分布式执行测试,解决浏览器兼容性问题。【通过 Selenium Grid 的可以控制多台机器多个浏览器执行测试用例,分布式上执行的环境在 Selenium Grid 中称为node节点。】
⑤举例:
当自动化测试用例达到一定数量的时候,比如上万,一台机器执行全部测试用例耗时5个小时(只是举例,真正的耗时是需要根据测试用例场景的复杂度决定的),而如果需要覆盖主流浏览器比如Chrome、Firefox,加起来就是10个小时;这时候领导跟你说有什么办法可以解决这个执行速度?当然最笨的办法就是另外拿台机器,然后部署环境,把测试用例分开去执行然后合并结果即可。而Selenium也想到了这点,所以有了Selenium Grid的出现,它就是解决分布式执行测试的痛点。
⑥总结:
Slenium Grid 分布式测试由hub主节点和node节点组成
Hub节点用来管理node节点注册信息。
脚本——》Hub节点——》node节点——》浏览器
具体参考:
selenium Grid详解
Selenium Grid 分布式 | 介绍与实战
2.1.3 Selenium RC介绍与使用
早期的Selenium使用的是Javascript注入技术与浏览器打交道,需要Selenium RC启动一个Server,将操作Web元素的API调用转化为一段段Javascript,在Selenium内核启动浏览器之后注入这段Javascript。
Javascript可以获取并调用页面的任何元素进行操作,实现了Selenium自动化Web操作的目的。这种Javascript注入技术的缺点是速度不理想,而且稳定性大大依赖于Selenium内核对API翻译成的Javascript质量高低。
2.1.4 WebDriver介绍与使用
Selenium2.x 提出了WebDriver的概念之后,它提供了完全另外的一种方式与浏览器交互。那就是利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)。由于使用的是浏览器原生的API,速度大大提高,而且调用的稳定性交给了浏览器厂商本身,显然是更加科学。然而带来的一些副作用就是,不同的浏览器厂商,对Web元素的操作和呈现多少会有一些差异,这就直接导致了Selenium WebDriver要分浏览器厂商不同,而提供不同的实现。例如Firefox就有专门的FirefoxDriver,Chrome就有专门的ChromeDriver等等。(甚至包括了AndroidDriver和iOS WebDriver)

2.2 WebDriver常用API
2.2.1 浏览器的操作
导入依赖
# #1.webdriver的使用
import time
from selenium import webdriver
from selenium.webdriver.support.select import Select
2.2.1.1 加载驱动
#使用方式1:放置环境变量路径
#例如将驱动文件直接放置到已配置好的python环境变量根路径。
dr = webdriver.Chrome()
dr = webdriver.Firefox()
dr = webdriver.Ie()
#使用方式2:指定绝对路径
dr = webdriver.Chrome(executable_path="C:\driver\chromedriver.exe")
dr = webdriver.Firefox(executable_path="C:\driver\geckodriver.exe")
dr = webdriver.Ie(executable_path="C:\driver\IEDriverServer.exe")
#注:可用于浏览器兼容性测试。
案例:
# firefox
wd = webdriver.Firefox(firefox_binary=r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe',executable_path=r'F:\桌面文件\工具\geckodriver.exe')
# chrome
wd = webdriver.Chrome(executable_path='./chromedriver.exe')
2.2.1.2 打开,关闭浏览器,浏览器窗口设置
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
wd = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
wd.maximize_window()
# 设置窗口宽度和高度
wd.set_window_size(1400,1500)
# 设置窗口位置
wd.set_window_position(100,100)
wd.get('https://www.baidu.com/')
time.sleep(4)
# 关闭窗口
# wd.close()
wd.quit()
2.2.1.3 前进后退刷新
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
# 设置窗口宽度和高度
driver.set_window_size(1400,1500)
# 设置窗口位置
driver.set_window_position(100,100)
driver.get('https://www.baidu.com/')
driver.get('https://www.zhihu.com/')
time.sleep(3)
driver.back() #后退
time.sleep(3)
driver.refresh() # 刷新
time.sleep(3)
driver.forward() # 前进
# 等待
time.sleep(4)
# 关闭窗口
# driver.close()
driver.quit()
2.2.2 元素的定位
2.2.2.1 定位元素的API
定位一个或多个:
driver.find_element_by_
driver.find_elements_by_
具体如下:
dr.find_element_by_id()
dr.find_element_by_name()
dr.find_element_by_tag_name()#标签名
dr.find_element_by_link_text()#完全匹配链接文本
dr.find_element_by_partial_link_text()# 模糊匹配链接文本
dr.find_element_by_class_name()
dr.find_element_by_css_selector()
dr.find_element_by_xpath()
注:
1.确保唯一属性的情况下,定位推荐使用顺序id-name-xpath-other;
2.定位一组具有相同属性的元素,例如:dr.find_elements_by_name();
3.有时即便有id也不能通过id定位,因为它可能是动态id;
4.由于selenium使用xpath定位时采用遍历页面的方式,在性能上采用CSS选择器的方式更优。xpath虽然性能指标较差,但是在浏览器中有比较好的插件支持,定位元素比较方便,对于性能要求严格的场景,可考虑通过xpath改写css的方式进行替换。
2.2.2.2 下拉列表的定位
div+li形成的下拉列表:
案例
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
driver.get('https://www.lagou.com/zhaopin/')
# 等待
time.sleep(4)
# 选择排序方式
driver.find_element_by_xpath('//*[@id="order"]/li/div[1]/a[1]').click()
time.sleep(4)
# 单击工作性质后的下拉框
driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div').click()
time.sleep(4)
# 单击兼职选项
driver.find_element_by_link_text("兼职").click()
time.sleep(4)
# 关闭窗口
# driver.close()
driver.quit()
select元素的下拉列表
# 通过索引选择
Select(driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div')).select_by_index(2)
# 通过内容选择选项
Select(driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div')).select_by_visible_text('兼职')
# 通过value属性选择选项
Select(driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div')).select_by_value('兼职')
# 需要注意如果被选择的元素不是select元素,会抛出错误 Select only works on <select> elements, not on <div>
2.2.2.3 层级元素的定位
案例
import time
from selenium import webdriver
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
driver.get('https://www.baidu.com/')
# 等待
time.sleep(4)
# 获取左上角百度新闻的链接
str1 = driver.find_element_by_id("s-top-left").find_elements_by_tag_name("a")[0].get_attribute("href")
print(str1)
time.sleep(4)
# 关闭窗口
# driver.close()
driver.quit()
2.2.2.4 对定位元素的操作
driver.find_element_by_name(“tj_trnews”).text#获取文本
driver.find_element_by_id(“kw”).click()#单击
driver.find_element_by_id(“kw”).send_keys(“selenium”)#输入内容
driver.find_element_by_id(“kw”).clear()#清空输入内容
driver.find_element_by_id(“kw”).get_attribute(“name”)#获取属性值
driver.find_element_by_id(“kw”).is_displayed()#是否显示
driver.find_element_by_id(“kw”).is_enabled()#是否可用
driver.find_element_by_id(“kw”).is_selected()#复选框是否被选中
2.3 等待时间
方法
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get('https://www.baidu.com/')
time.sleep(4) # 强制等待
driver.implicitly_wait(4) # 隐式等待 如果元素原先就存在会导致读取不到更新后的数据,可以先强制等待后再隐式等待
WebDriverWait(driver, 5, 0.5).until(lambda wd:wd.find_element_by_id('su').get_attribute("value")) # 显式等待
2.4 文件上传
通过
driver.find_element_by_id('kw').send_keys("刘德华")
# send_keys中可以设置文件的路径,即可完成对应的文件上传
#方式1:通过send_keys()
driver.find_element_by_id("batchfile").send_keys('D:\\woniu\\秦超\\教学\\UI自动化\\PiCiDaoRu.xls')
driver.find_element_by_xpath("//input[@value='确认导入本批次商品信息']").click()
#方式2:通过PyKeyboar,需要依次安装pyHook和PyUserInput
from pykeyboard import PyKeyboard
try:
driver.find_element_by_id("batchfile").click()#用firefox不行,chrome可以
except Exception as e:
driver.find_element_by_xpath("//*[@class='col-lg-5 col-md-5 col-sm-5 col-xs-5'][2]").click()
sleep(3)
k = PyKeyboard()
k.type_string("E:\\study\\PycharmProjects\\python_3issue\\GUI\\PiCiDaoRu.xls")#不支持中文
k.press_keys([k.alt_key,'o'])#alt+o组合键点击确定
sleep(1)
driver.find_element_by_xpath("//input[@value='确认导入本批次商品信息']").click()
#方式3:使用sikulix的jar包
#方式4:其它,比如AutoIt
2.5 窗口切换
在WebDriver中,焦点切换主要分为如下3类
警告窗体的焦点切换
内嵌页面的焦点切换
渐开窗口或者标签的焦点切换
焦点切换使用driver.switch_to的方式实现。
2.5.1 确认对话框
当对话框出现时,无法使用find_element_by的方式捕获元素,这时可以使用WebDriver的内置方法。
driver.switch_to.alert.dismiss() # 点击取消按钮
driver.switch_to.alert.accept() # 点击确认按钮
driver.switch_to.alert.text # 获取对话框的提示信息文本内容
driver.switch_to.alert.send_keys() # 向对话框中输入内容 如果没有文本框 则抛出异常
2.5.2 新窗口的切换
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
# 设置窗口宽度和高度
driver.set_window_size(1400, 1500)
# 设置窗口位置
driver.set_window_position(100, 100)
driver.get('https://www.baidu.com/')
# 等待
time.sleep(4)
driver.find_element_by_id('kw').send_keys("刘德华")
driver.implicitly_wait(4) # 隐式等待
# time.sleep(4) # 可以和隐式等待对比区别
driver.find_element_by_id('su').click()
# 显式加载 并获取属性
ele = WebDriverWait(driver, 5, 0.5).until(lambda wd:wd.find_element_by_id('su').get_attribute("value"))
print("ele-->",ele)
# 会切换到新的窗口
driver.find_element_by_partial_link_text("刘德华").click()
# 当前的窗口句柄
s_before = driver.current_window_handle
print("s_before-->",s_before)
# 获取所有窗口句柄
s_behind = driver.window_handles
print("s_behind-->",s_behind)
time.sleep(4)
# 可以通过非遍历的方式,用索引来切换
driver.switch_to.window(s_behind[-1])
time.sleep(4)
# 可以通过遍历的方式切换
for i in s_behind:
# 切换到原有的窗口
if i != s_before:
driver.switch_to.window(i)
# 关闭窗口
# wd.close()
driver.quit()
输出为:
ele–> 百度一下
s_before–> 0D69C66D5E67653C338C9CDE36921B2D
s_behind–> [‘0D69C66D5E67653C338C9CDE36921B2D’, ‘6EE2C14168E6F0137805F71C6401DBF3’]
2.5.3 frame切换
# 根据classname切换frame
driver.switch_to.frame(driver.find_element_by_class_name('myFrame'))
driver.switch_to.frame('myFrame') # 根据id转换
time.sleep(1)
driver.find_element_by_xpath('//a[@node="0"]').click()
driver.find_element_by_link_text('确定').click()
# 切换到原始页面
driver.switch_to.default_content()
2.6 WebDriver截图
import time
# import os
# print("os.getcwd()-->",os.getcwd())
now = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
# 方式1:
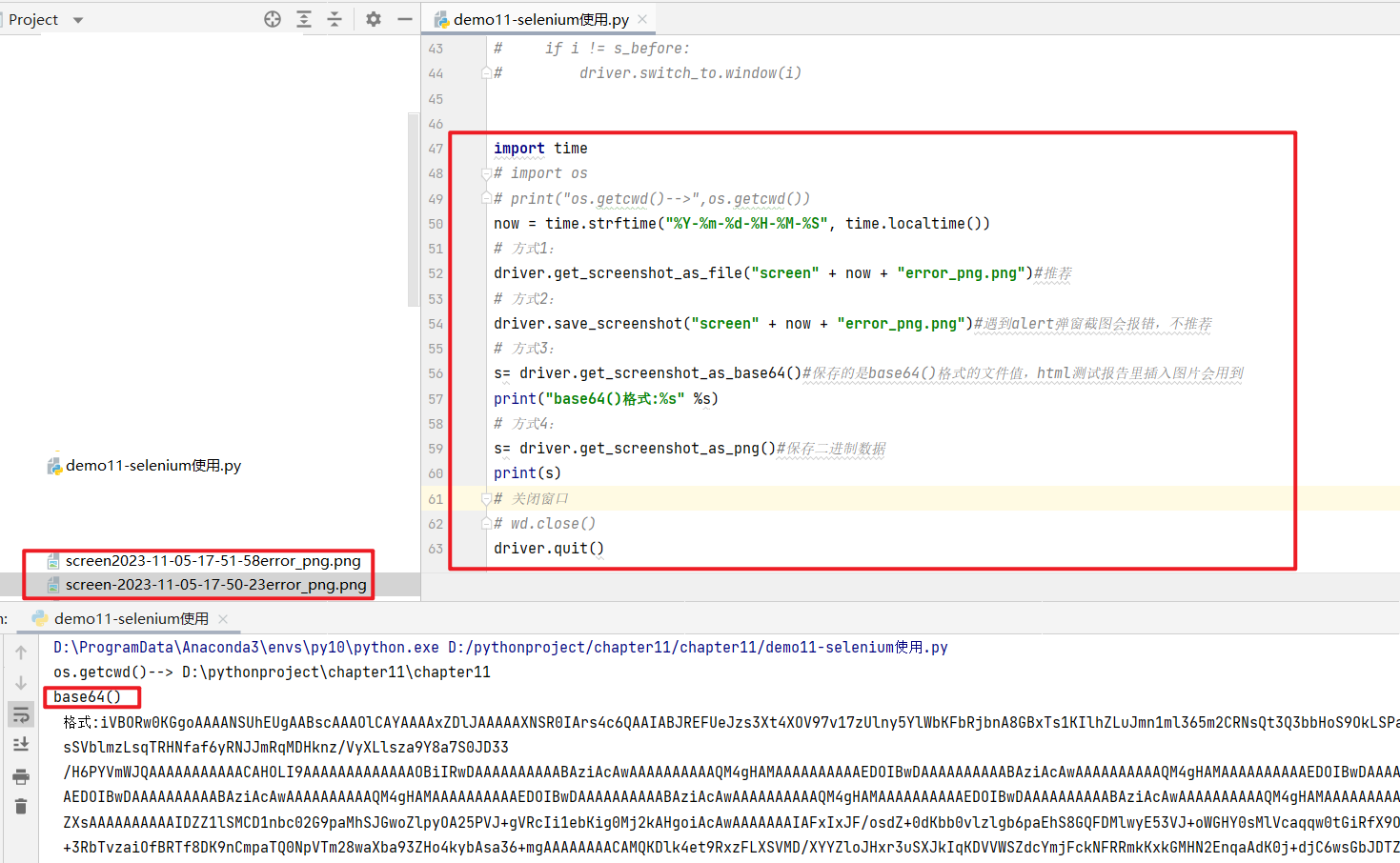
driver.get_screenshot_as_file("screen" + now + "error_png.png")#推荐
# 方式2:
driver.save_screenshot("screen" + now + "error_png.png")#遇到alert弹窗截图会报错,不推荐
# 方式3:
s= driver.get_screenshot_as_base64()#保存的是base64()格式的文件值,html测试报告里插入图片会用到
print("base64()格式:%s" %s)
# 方式4:
s= driver.get_screenshot_as_png()#保存二进制数据
print(s)
输出为:
2.7 WebDriver 调用JavaScript
#移动滚动条
#方式1:没有ID的滚动条不支持
js="var q=document.documentElement.scrollTop=10000"
# js_="var q=document.documentElement.scrollTop=0"
driver.execute_script(js_)
#方式2:拖动到指定元素
# target1 = driver.find_element_by_xpath("//*[text()='页顶']")
# driver.execute_script("arguments[0].scrollIntoView();", target1)
#修改属性
driver.execute_script("document.getElementById('barcode').readOnly=true;")
driver.execute_script("document.getElementById('barcode').removeAttribute('readonly');")
案例
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
# 设置窗口宽度和高度
driver.set_window_size(1400, 1500)
# 设置窗口位置
driver.set_window_position(100, 100)
# driver.get('https://www.baidu.com/')
driver.get('https://news.baidu.com/')
# 等待
time.sleep(4)
#拖动滚动条
driver.execute_script('window.scrollTo(0,1200)')
#添加标签
driver.execute_script('document.getElementById("headerwrapper").innerHTML+=\"<option>新增加的内容</option>\"')
#修改标签属性
driver.execute_script('document.getElementById("headerwrapper").readOnly=false')
time.sleep(4)
# 关闭窗口
# wd.close()
# driver.quit()
2.8 鼠标和键盘事件
2.8.1 鼠标事件
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
# 设置窗口宽度和高度
driver.set_window_size(1400, 1500)
# 设置窗口位置
driver.set_window_position(100, 100)
# driver.get('https://www.baidu.com/')
driver.get('https://news.baidu.com/')
# 等待
time.sleep(4)
right = driver.find_element_by_id("xx") #定位到元素
ActionChains(driver).click(right).perform()#单击
ActionChains(driver).context_click(right).perform()#对定位到的元素执行鼠标右键操作
ActionChains(driver).double_click(right).perform()#双击
ActionChains(driver).move_to_element (right).perform()#鼠标悬停在一个元素上
ActionChains(driver).click_and_hold(right).perform()#按下鼠标左键在一个元素上
element = driver.find_element_by_name("xxx") #定位元素的原位置
target = driver.find_element_by_name("xxx") #定位元素要移动到的目标位置
ActionChains(driver).drag_and_drop(element, target).perform()#拖动
ActionChains(driver).release(right).perform() # 释放鼠标
# ActionChains(dr):dr: wedriver 实例执行用户操作。ActionChains 用于生成用户的行为;所有的行为都存储在 ActionChains 对象。通过 perform()执行存储的行为。
# perform():执行所有 ActionChains 中存储的行为。perfrome()同样也是 ActionChains 类提供的的方法,通常与ActionChains()配对使用。
2.8.2 键盘事件
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
# 设置窗口宽度和高度
driver.set_window_size(1400, 1500)
# 设置窗口位置
driver.set_window_position(100, 100)
# driver.get('https://www.baidu.com/')
driver.get('https://news.baidu.com/')
# 等待
time.sleep(4)
driver.find_element_by_id("barcode").send_keys("123456")
driver.find_element_by_id("barcode").send_keys(Keys.BACK_SPACE)#单击回删键
driver.find_element_by_id("barcode").send_keys(Keys.SPACE)#单击空格
driver.find_element_by_id("barcode").send_keys(Keys.ENTER) #通过回车键盘来代替点击操作
driver.find_element_by_id("barcode").send_keys(Keys.DOWN) #单击向下键
#。。。。。。
driver.find_element_by_id("barcode").send_keys(Keys.CONTROL,'a') #ctrl+a 全选输入框内容
driver.find_element_by_id("barcode").send_keys(Keys.CONTROL,'c')
driver.find_element_by_id("barcode").send_keys(Keys.CONTROL,'v')
driver.find_element_by_id("barcode").send_keys(Keys.CONTROL,'x')
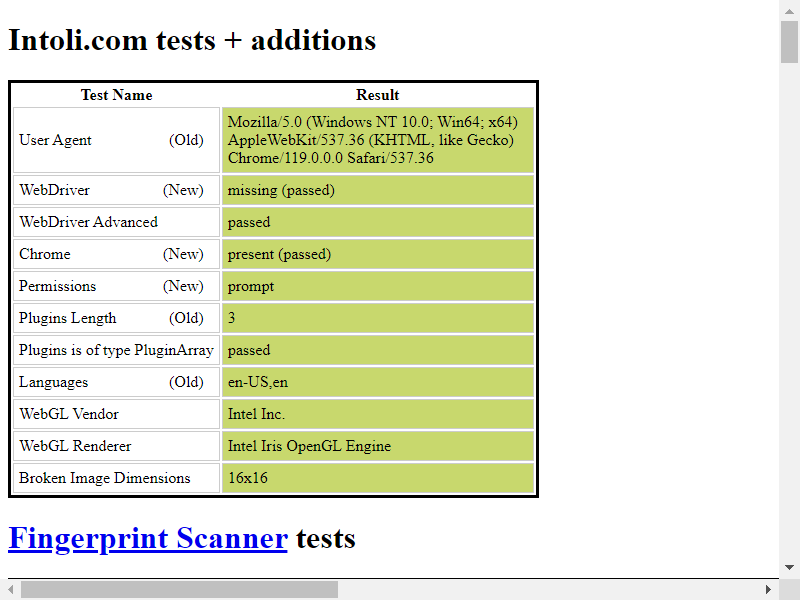
2.9 selenium如何防止被检测
参考:如何彻底防止Selenium被检测!
利用stealth.min.js隐藏selenium特征 - Python
通过谷歌浏览器访问:
https://bot.sannysoft.com
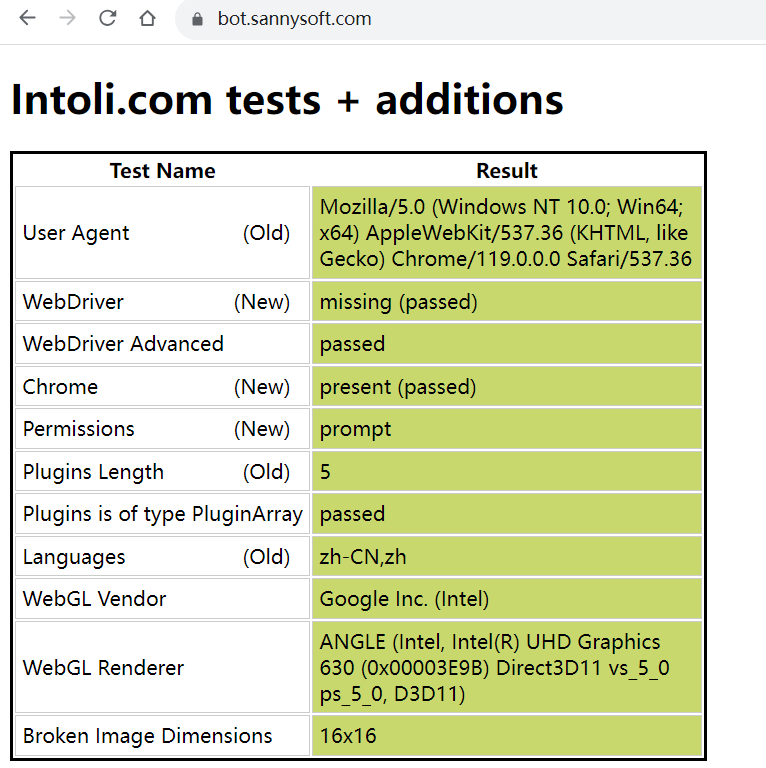
可以查看到哪些特征是会被检测的
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = Chrome(executable_path='./chromedriver', options=chrome_options)
driver.get('https://bot.sannysoft.com/')
driver.save_screenshot('screenshot.png')
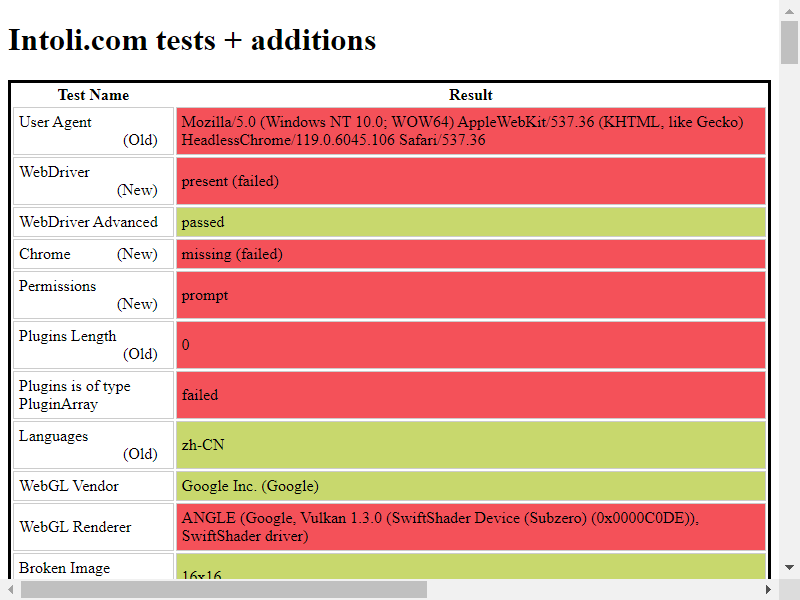
下面我们加载一个stealth.min.js文件后再来访问这个网站,查看特征值:
stealth.min.js的下载地址为:
https://gitcode.com/mirrors/requirecool/stealth.min.js/overview?utm_source=csdn_github_accelerator
把这个文件放在项目工程目录下
运行如下代码:
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36')
driver = Chrome(executable_path='./chromedriver', options=chrome_options)
with open('./stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://bot.sannysoft.com/')
time.sleep(5)
driver.save_screenshot('walkaround.png')
source = driver.page_source
with open('result.html', 'w') as f:
f.write(source)