教程目录
1.3 CoolBlog开发笔记第3课:创建Django应用
前言
我新书《Python爬虫开发与项目实战》出版了。 这本书包括基础篇,中级篇和深入篇三个部分,不仅适合零基础的朋友入门,也适合有一定基础的爬虫爱好者进阶,如果你不会分布式爬虫,不会千万级数据的去重,不会怎么突破反爬虫,不会分析js的加密,这本书会给你惊喜。如果大家对这本书感兴趣的话,可以看一下 试读样章。废话少说,开始讲正题。从上一节我们知道home应用需要涉及文章,分类和标签三个部分,其实这就是个人博客系统最核心的功能:发表文章。下面我们分析一下数据库该如何设计?
一个Web应用最根本的功能是完成与客户端(浏览器)的交互,本质上其实是HTTP请求与响应的过程。下面咱们说一下HTTP的请求与响应,Django到底在其中扮演了什么样的角色?
1.5.1 HTTP请求过程
HTTP协议采取的是请求响应模型, HTTP协议永远都是客户端发起请求,服务器回送响应,模型如下所示:
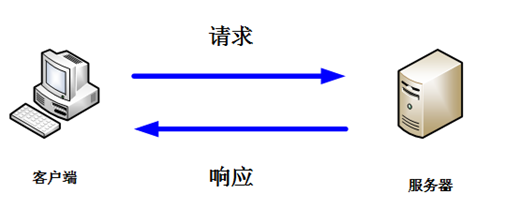
HTTP协议是一个无状态的协议,同一个客户端的这次请求和上次请求是没有对应关系。一次HTTP操作称为一个事务,其执行过程可分为四步:
1) 首先客户机与服务器需要建立连接,例如单击某个超链接,HTTP的工作就开始了。
2) 建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3) 服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4) 客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
在以上四步中,Django主要是完成其中的第三步:接收请求,处理请求并进行响应。其实Django已经把这个过程封装的非常完善,不需要关注HTTP协议的细节,开发者只需要关注用户逻辑的处理。
1.5.2 路由机制
作为一个Web应用,你要处理用户的请求,首先要接收到的用户的请求。例如访问http://www.cnblogs.com/qiyeboy/和http://www.cnblogs.com/qiyeboy/archive/2017/05.html,这两个网址肯定是不一样的,我们的Web应用如何区分呢?这就需要用到Django的路由机制来处理用户访问的不同网址。Django主张的办法是在应用目录下创建urls.py文件,将相应的url与对应的处理函数绑定起来。具体做法:在CoolBlog项目下的home应用文件夹里新建urls.py,目录结构如下。
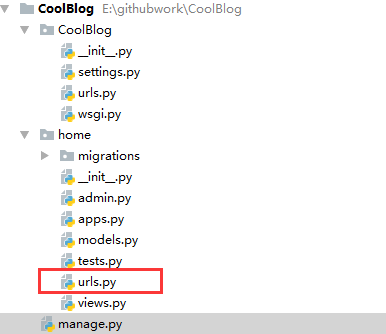
打开urls.py文件,写入以下代码:
#coding:utf-8
from django.conf.urls import url
from home import views
urlpatterns = [
url(r'^$', views.index, name='index'),
]
这就定义好了home应用中首页的路由方式,接下来解释一下urlpatterns变量的含义:urlpatterns是一个url实例的列表,用来存储一系列的匹配规则。上述url实例中传入了三个变量:
- r'^$'字符串是访问网址(去掉http(https)、域名和端口号)的正则表达式写法,其实就是一个空字符串,类似用户直接访问:http://www.baidu.com,在去掉https//和域名之后,就剩下空字符串了;
- views.index是home目录下views.py中的视图函数,用来处理请求;
- name=’index’是给url实例起的别名,这个在后面会有很大的用处。
但这时候并没有结束,因为Django并不知道home应用设置了什么url,我们需要将home应用下的urls文件注册到CoolBlog项目的路由机制中。打开CoolBlog项目下的CoolBlog文件夹中的urls.py文件,如下图所示。
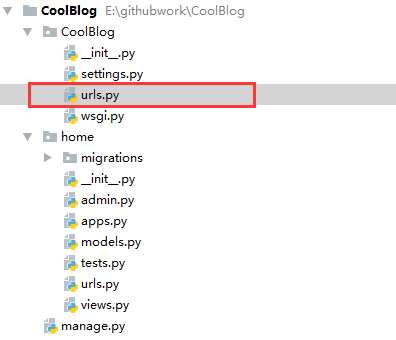
在其中添加如下代码,完成注册:
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'',include('home.urls'))
]
这个可以看做是CoolBlog项目的主路由,而home应用的urls.py文件可以看做是CoolBlog项目中的一个从路由,因此真正匹配的请求网址是这两者的组合,也就是说匹配到home应用首页的网址的正则表达式为r''+ r'^$',最后相加的结果依然是r'^$'。到此为止,home首页的路由搭建完成,下面开始进行视图函数的编写。
1.5.3 视图
在1.5.2中我们在urlpatterns配置的视图函数名称为index,那么我们需要在home应用下的views.py文件中,添加以下代码:
#coding:utf-8
from django.http import HttpResponse
# Create your views here.
def index(request):
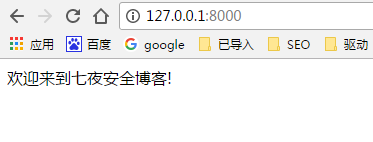
return HttpResponse("欢迎来到七夜安全博客!")
HttpResponse实例通过初始化字符串来生成HTTP响应,进行返回。下面我们看一下效果,激活虚拟环境,切换到CoolBlog目录下,运行python manage runserver。
打开浏览器,输入http://127.0.0.1:8000,效果如下:
1.5.4 模板机制
通过上面的配置,请求与响应的交互过程已经实现,但是显示界面实在太丑。通过HttpResponse传入字符串生成响应的方式,比较简陋,仅仅用于演示,毕竟我们不能总是传入大段字符串吧,于是Django提供了更好的视图方式:模板机制。模板机制工作流程大致如下:
- 我们将大段的字符串(比如HTML)保存成文件,放到Django能找到的位置。
- Django从我们指定的位置读取文件,转化为字符串,并解析成要显示的内容。
- 将要显示的字符串构造成HttpResponse实例,并在视图函数中返回。
下面我们开始自定义自己的模板文件。首先在CoolBlog项目根目录下,新建templates文件夹,并在此文件夹下新建home文件夹(我习惯按照应用名称将模板文件分类),最后在home文件夹下新建home应用的第一个模板文件:index.html。
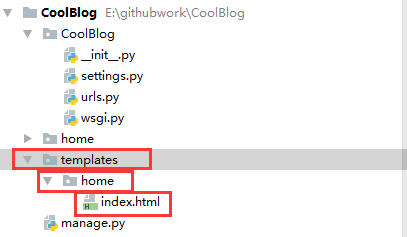
在index.html文件中输入如下内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{title}}</title>
</head>
<style>
h1
{
color:green;
text-align:center;
}
</style>
<body>
<h1> {{text}} </h1>
</body>
</html>
大家有没有注意到这和普通的html文件不一样,里面多了{{title}}和{{text}}这两项特殊的内容。其实这是Django自定义的模板语法,可以允许我们传入变量,动态改变显示的内容,用 {{ }} 包起来的变量叫做模板变量。大家有没有注意到之前提到的模板机制工作流程的第2步,从文件中读取字符串,经过解析才是我们要显示的内容,这里面说到的解析,指的就是Django通过模板引擎对模板文件中自定义的语法进行预处理的过程。
模板文件编写完成,但是现在还用不了,因为Django找不到它,我们需要将模板文件的位置告诉Django。打开settings.py文件,找到TEMPLATES变量,并在DIRS列表中添加templates的路径: os.path.join(BASE_DIR,'templates'),具体修改如下:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR,'templates'),],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
BASE_DIR即为CoolBlog项目的根目录,在settings.py中的定义为:
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
添加好路径,开始我们的重头戏,在index视图函数中渲染index.html模板文件,将原来views.py中的视图函数修改为:
def index(request):
return render(request,'home/index.html',context={
'title':'七夜安全博客','text':'欢迎进入七夜安全博客'
})
在index函数中我们调用了Django提供的render方法,并给render方法传入了三个参数:
- request:传入的HTTP请求
- 'home/index.html'是模板文件的相对路径,我们在settings.py中仅仅把templates文件夹的路径告诉了Django,因此如果想要定位其home文件夹下的index.html文件,我们还要传入相对路径。
- context是一个字典,里面储存的是index.html中模板变量所需的值。
这时候将修改过的文件保存,不过不需要重新运行python manage.py runserver命令,因为刚才已经启动了server,而且Django支持热更新,会将修改过的py文件重新加载(如果之前没启动,需要运行runserver命令)。打开浏览器,输入http://127.0.0.1:8000,效果如下:

虽然还是很简陋,但是给了我们无限拓展的空间。
最后
我新书《Python爬虫开发与项目实战》出版了。 这本书包括基础篇,中级篇和深入篇三个部分,不仅适合零基础的朋友入门,也适合有一定基础的爬虫爱好者进阶,如果你不会分布式爬虫,不会千万级数据的去重,不会怎么突破反爬虫,不会分析js的加密,这本书会给你惊喜。如果大家对这本书感兴趣的话,可以看一下 试读样章。

欢迎大家支持我公众号:
