Logistic regression 的目的和作用
logistic regression 的作用是分类。不过是通过预测某事件发生的概率进行分类的。
概率是一个连续值,如果某一类出现的概率最大,则认为这个instance属于这个类。
logistic regression 虽然简单,但是对于大多数情况来说是适用的,而且实现简单,计算速度快。
应用实例:
给出一个员工的工作数据,使用logistic regression 来预测员工是否会跳槽。这里的目标是得到 P[Y = True|X]的值。X 表示某个员工的所有属性。
这个值的意义是,在给定 X 属性的情况下, Y = True 发生的概率。有没有很熟悉,这和 Naive Bayes 的目标是一样的。所以可以认为,所有分类问题,就是求概率的问题。当概率大于某一个值时,就属于某一个类。
哑变量(dummy variable)
离散变量:只表示分类的变量,其取值不是数字,故无法进行数学操作。而且离散变量的取值和强度大小无关。
需要将离散变量变成为哑变量。
哑变量是one hot encoding 中的 0 和 1。
如果离散变量有K 个值,那么就设置 K 个哑变量。如果离散变量取值是第i个值,就让第i个哑变量为1,其余的都是0。
当离散变量变为哑变量时,相当于将instance的feature数增大来。
哑变量将离散变量取值扩大之后,其的意义表示,值越大,性质越强。故对于某一个离散变量的取值,只有一个哑变量是1,其余都是0。
在实际计算中,因为有截距的存在,如果一个离散变量有 K 类,哑变量只需 K - 1 类,相当于截距将第K类吸收了。故每一个哑变量的系数变为原来的系数 - 被吸收的那一项的系数。
以此类推,所有的categorical类都可以被截距吸收。
Logistic regression 与 linear regression 之间的联系
其实从logistic regression 的等式中,我门可以看到里面有浓厚的 linear regression的风格。其实logistic regression就是借用了linear regression的思想,并对其进行修改得到的。至于为何要借用linear regression,应该是由于linear regression模型简单,而且经过实际运用,发现其实是能够满足大多数情况的。既然简单模型能够用,根据奥卡姆剃刀原则,干嘛要去选复杂模型的?
但是logistic regression 中也是出现了e, 分数之类的。为什么要这么麻烦呢?
logistic regression 的修改
由于使用linear regression,概率值和feature之间呈线性关系。所以最后算得的概率可能是 > 1 或者 < 0 的,这和概率的实际意义不一致。
修改目的:将 负无穷到正无穷的 值,映射到 [0,1] 但是不改变其性质。
这种修改的方法有很多种,但是最有效最简单的,也是大家常用的,是使用 log(odds) 来做
修改的过程如下:
引入odds假设一个事件发生的概率为p,则不发生的概率为 1 - p。定义这个事件的odds 为 odds = p / (1 - p )
odds也能表示一个事件发生的概率,但是由于其范围是 [0,正无穷] 所以选用odds而不用概率。
由于odds不可能是负数,但是 linear regression可能是负数,所以需要将负数部分都转移到 0, 正无穷上去。
引入 对数 log
对数的定义域是 0,正无穷。值域是 正无穷和负无穷。
可得出结论: log(odds) 能够成功与 linear regression 相对应。不管 linear regression 最后得到一个什么值,都能通过 log(odds) 转换成一个 [0,1] 的概率 P。
当然,这个结论是通过大量实验得到的。
由log(odds) 得到 P 和 linear regression 之间的关系
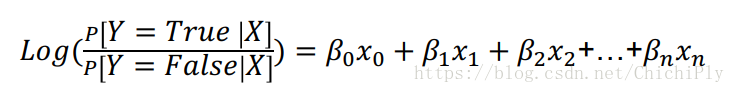
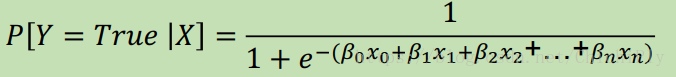
得到的这个函数可以作为 sigmoid 函数
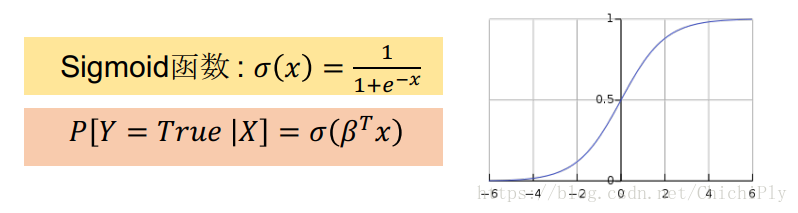
X 的系数的意义为:
系数为正,表示最终概率随着这个feature的增高而增高;
系数为负,表示最终概率随着这个feature的增高而降低;
系数越大,表示这个feature的影响越大
这里注意一点,截距其实是吸收了其中一个哑变量的。意思是,其他的哑变量都是以某一个哑变量作为基础的。
Logistic regression 的 loss function
交叉熵涉及到机器学习的基本原理。
机器学习认为,所有instance的分布是符合一个规律的。而机器学习的目的就是找到这个分布的规律,使模拟的分布规律能够近似等于实际的分布规律。而衡量两个分布规律的方法就是交叉熵。
机器学习的训练过程就是调整参数,使得模型在训练集上的错误率达到最小。如果参数比较少,并且已知参数的取值范围,最直观的寻找参数的方法是挨个去试。但是当参数数目多,取值范围大时,这种方法就不能用来。这里就引入了 loss function 的概念。
loss function 表达的是参数与错误率之间的关系。所有模型的loss function的目的都是为了模拟错误率。
loss function 是一个关于参数的方程。它可以近似地表示错误率,即当f值越大,错误率近似地越大。我们为什么要用loss function 来表示错误率,而不直接用错误率来做呢?因为对与错误率来说,往往是不能求导的。当稍微改变某一个参数时,有肯能并不会导致错误率的变化。所以错误率的变化曲线是不连续的。所以采用 loss function,因为 loss function是可以求导的。
loss function实际上只干了一件事,计算预测值与真实值之间的差别。我们的目的是使得预测值与真实值之间的差别越小越好。
对于yi = True 的那些instance,我们希望跳槽概率尽量大,对于yi = False 的那些instance,我们希望跳槽概率尽量小。
在logistic regression 中,将loss function 定义为 cross entropy。公式如下:
CE = -[yi * log(P[yi = 1|Xi]) + (1 - yi) * log(1-P[yi = 1|Xi])]
要求得 CE 的最小值,就是求括号里面式子的最大值。而括号里面的式子可以看作是求对于每一个Xi 预测正确的概率的对数。
Cross Entropy 在定义的时候,是包含真实的yi和预测的yi。但是当涉及到多分类时,yi就不好取值了,所以推荐将 cross entropy 记做 log(p[yihat = yi|Xi])。其意义是 对于每个instance预测对的概率的对数
所以逻辑是这样的:
为了描述模型与真实情况之间的差异,引入loss function,只需求得 loss function 的最小值即可。
loss function 中每一项表示的是预测正确的概率的对数,所以loss function 能够表达模型与真实情况之间的差异。
在这里有一点很有意思,交叉熵和最大似然估计是可以相互替换的。
因为要使得预测值和真实值之间的差异最小,等价于最大化 Pi[Y = Yi|Xi]。
而P[Y = Yi |Xi] 就是似然函数。 最大话这些的乘积就是求最大似然估计。
loss function的种类很多,比如对于 linear regression来说,用的loss function就是 MSE。
Logistic regression 模型评价标准
通过混淆矩阵表示预测的准确率。
confusion matrix 中,横轴表示预测,纵轴表示实际
混淆矩阵中,较为迷惑的是 false negative 和 false positive 这两项所表达的含义。
False negative 表示实际上是 True,但是你预测得到的结果是 false
False positive 表示实际上是 False,但是你越长得到的结果是 true
评价标准有: precision, recall, f1, accuracy
Precision: 在预测为正确的样本里,有多少是真正正确的
Precision = True positive / (True positive + False positive)
Recall: 所有实际为正确的样本里,你挑出来了多少
Recall = True positive / ( True positive + False negative)
Accuracy:搞对的比例
Accuracy = (True positive + True negative) / All
Recall 和 Positive 表示的是模型的两个方面的能力。在实际应用的时候,选择将两者结合起来的 F1 score。
在实际判断中,可以用 classification_report 来得到所有分类的 precision , recall ,f1
其中的support是真实数据中,每个分类的样本数。