从线性回归讲起
先说回归问题。对于回归问题,最常用的是用线性函数来拟合待预测值,即:
f(x)=wTx+b,
使得
f(x)≈y
上述情况中,待预测值是在线性尺度上变化,假若是在指数尺度上变化(
y
取值类似于1、2、4、8、16…),则可将待预测值的对数作为线性函数逼近的目标,即:
lny=wTx+b
这实际上是试图让
ewTx+b
来逼近
y
。更一般地,考虑单调可微函数
g
,有:
g(y)=wTx+b
则有:
y=g−1(wTx+b)
这样得到的模型称为“广义线性模型”(generalized linear model),其中
g
称为“联系函数”(link function)。
Logistic Regression
若要将线性函数用于分类,则只需找到
g
函数将分类任务的真实标记与线性函数预测值联系起来。考虑二分类问题,输出标记
y∈{0,1}
,而线性回归函数的预测值
z=wTx+b
为实数值,需要将实数值转换为0/1值。常用logistic function,即:
g(z)=11+e−z
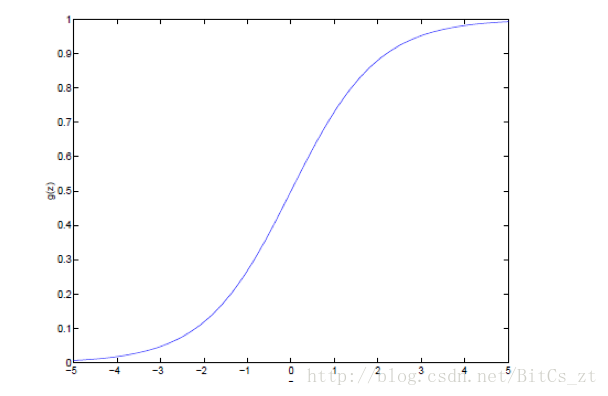
可以看到,
g(z)
:
-
z
趋近于正无穷时
g(z)
趋近于1
-
z
趋近于负无穷时
g(z)
趋近于0
-
g(z)∈(0,1)
-
g′(z)=g(z)(1−g(z))
将线性函数代入logistic function,有:
y=11+e−(wTx+b)
进行适当的反变换,有:
lny1−y=wTx+b
若将
y
视为样本
x
作为正例的可能性,则
1−y
是其反例可能性,两者的比值称为“几率”(odds),反映了
x
作为正例的相对可能性。由此看来,logistic function使用线性函数的预测结果去逼近真实标记的对数几率。它
- 直接对分类可能性建模,无需事先假设数据分布
- 得到样本属于某一类别的近似概率
- logistic function任意阶可导,数学性质良好
LR的求解
若将上式中的
y
视为
p(y=1|x)
,则有:
p(y=1|x)=ewTx+b1+ewTx+b
p(y=0|x)=11+ewTx+b
现在需要确定参数
w
使得所有训练样本属于对应标签的概率最大,即使用“极大似然法”进行参数估计。在当前模型下,每一个样本
{x(i),y(i)}
出现概率为:
p(y(i)|x(i),w)=p(y(i)=1|x(i),w)y(i)(1−p(y(i)=1|x(i),w))1−y(i)
似然函数为:
l(w)=∏ni=1p(y(i)|x(i),w)
取对数(借用别人的图,其中的
θ
即为上述
w
):
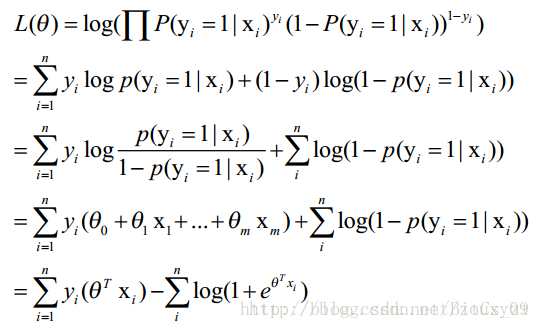
最大化似然函数,求导可得:
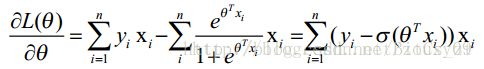
该式无法得到解析解,但
L(θ)
是关于
θ
的高阶可导连续凸函数,可通过梯度下降法(gradient descent method)求解。
结合logistic function图像可以看到,在使似然函数最大化的过程,实质是让所有标签为1的样本
{x(i),y(i)=1}
所对应的
y
趋近1,即
wTx+b
趋近于正无穷;而让是让所有标签为0的样本
{x(i),y(i)=0}
所对应的
y
趋近0,即
wTx+b
趋近于负无穷。
wTx+b
为一超平面,Logistic Regression和SVM的几何意义是十分相似的。
参考如下:
周志华《机器学习》第三章
机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)
SVM和logistic回归分别在什么情况下使用?