介绍
Logistic Regression是目前应用比较广泛的一种优化算法,利用logistic regression进行分类的只要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。“回归”一词源于最佳拟合,表示要找到最佳拟合参数集。
Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的Logistic回归[1]。
最大似然估计数学背景
某位同学与一位猎人一起出去打猎,一只兔子从前方窜过。只听见一声枪响,野兔应声倒下,如果要你来推测,这一发命中的子弹是谁打的?你会怎么想呢?正常的情况下,猎人的枪法肯定比你的同学的枪法好,也就是说猎人的命中率比你的同学高。而一枪就打死兔子,命中率是100%的,这么高的命中率,应该是谁打中的呢?显然,猎人开的枪比较符合我们观察的想象了吧。如果是开了三枪才打中兔子的话,那枪法就不怎么样了,某同学开的枪比较符合已经发生的现象了[2]。这就是最大似然估计所隐含的意义。
Logistic Regression的推导过程
对于多元线性回归,线性边界:
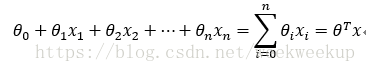
其中:

预测函数:
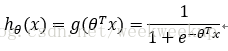
此时根据 代表着函数输出为1的概率,把分类结果看成类别1和类别2,也就是 ,故可得概率函数:

将两个公式进行合并:
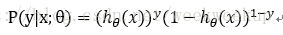
取似然函数:

取对数:
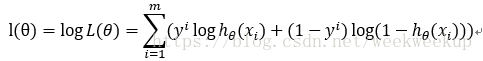
到这里可以采用梯度上升进行优化或者添加负系数用梯度下降进行优化,这里添加-1/m系数:

梯度下降法进行参数更新:
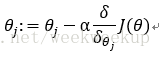
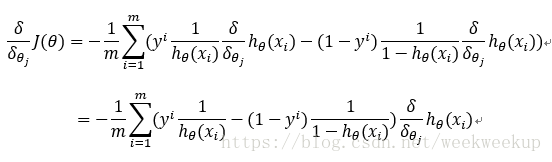
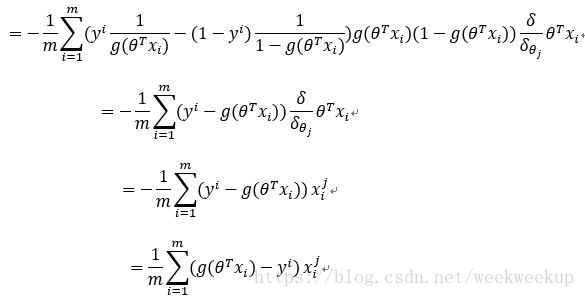
故参数更新过程如下:
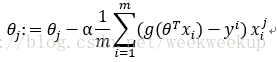
优缺点
优点:
计算代价不高,易于理解和实现;
预测结果是界于0和1之间的值。
缺点:
容易欠拟合,分类精度可能不高;
预测结果呈“S”型,概率变化很小,边际值太小,slope太小,而中间概率的变化很大,很敏感。 导致很多区间的变量变化对目标概率的影响没有区分度,不容易确定阀值。
实例代码
点击打开链接参考文献
[2] https://www.jianshu.com/p/8dc6df0be838
[3]Peter Harrington(著),李锐等(译).机器学习实战.