统计学习方法第二章:感知机(perceptron)算法及python实现
统计学习方法第三章:k近邻法(k-NN),kd树及python实现
统计学习方法第四章:朴素贝叶斯法(naive Bayes),贝叶斯估计及python实现
统计学习方法第五章:决策树(decision tree),CART算法,剪枝及python实现
统计学习方法第五章:决策树(decision tree),ID3算法,C4.5算法及python实现
完整代码:
https://github.com/xjwhhh/LearningML/tree/master/StatisticalLearningMethod
欢迎follow和star
感知器(perceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值。
感知器对应于输出空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。感知器学习旨在求出将训练数据进行线性划分的分离超平面,为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。
感知器学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。
感知器预测是用学习得到的感知机模型对新的输入实例进行分类。
下图是感知机学习算法的原始形式:

更详细的说明和证明可以在《统计学习方法》或者其他博客里看到,我在这里不再赘述,直接看代码。
我的python实现也是基于这个算法,使用的是MINST数据集,代码如下:
import pandas as pd
import random
import time
import logging
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def log(func):
def wrapper(*args, **kwargs):
start_time = time.time()
logging.debug('start %s()' % func.__name__)
ret = func(*args, **kwargs)
end_time = time.time()
logging.debug('end %s(), cost %s seconds' % (func.__name__, end_time - start_time))
return ret
return wrapper
class Perceptron(object):
def __init__(self):
self.learning_step = 0.00001
self.max_iteration = 5000
def predict_(self, x):
wx = 0
for i in range(len(self.w)):
wx += self.w[i] * x[i]
return int(wx > 0)
@log
def train(self, features, labels):
# (1)
self.w = [0.0] * (len(features[0]) + 1)
correct_count = 0
while True:
# (2)
# 有可能随机生成相同的数字,使得correct_count对一个数据有重复计算,但无伤大雅
index = random.randint(0, len(labels) - 1)
x = list(features[index])
x.append(1.0)
if labels[index] == 1:
y = 1
else:
y = -1
wx = 0
for i in range(len(self.w)):
wx += self.w[i] * x[i]
# 验证正确
if wx * y > 0:
correct_count += 1
# 训练集大约有两万多数据,这里可随意取适宜的值,用来跳出while循环
if correct_count > 10000:
break
continue
# (3)
# 验证错误,修改w值
for i in range(len(self.w)):
self.w[i] += self.learning_step * (y * x[i])
@log
def predict(self, features):
predict_labels = []
for feature in features:
x = list(feature)
x.append(1)
predict_labels.append(self.predict_(x))
return predict_labels
if __name__ == '__main__':
# 记录
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
raw_data = pd.read_csv('../data/train_binary.csv', header=0)
data = raw_data.values
images = data[0:, 1:]
labels = data[:, 0]
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
train_features, test_features, train_labels, test_labels = train_test_split(
images, labels, test_size=0.33, random_state=1)
# 模型训练
p = Perceptron()
p.train(train_features, train_labels)
# 使用测试集预测
test_predict = p.predict(test_features)
# 计算准确率
# 因为是随机的,每次得到的准确率都不同
score = accuracy_score(test_labels, test_predict)
print("The accuracy score is ", score)
结果如下,还是比较准确的
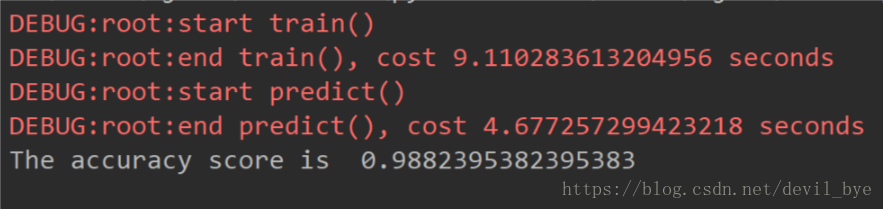
水平有限,如有错误,希望指出