本文主要是记录学习《统计学习方法》的笔记总结,部分内容会直接摘录书中原文,特此申明
感知机(perceptron)由Rosenblatt于1957年提出,是一种二类分类的线性分类器模型,输入的是实例(样本)的特征向量,输出的是实例的类别,一般以+1和-1两个值。感知机其实就是输入空间中将实例划分的超平面,属于判别模型。如果熟悉SVM的同学可能会联想到那个支持向量,两者的几何含义差不多。感知机学习旨在求出将训练数据进行线性划分的超平面,利用梯度下降法,将损失函数极小化,求得感知机模型。感知机是神经网络和SVM的基础。
1、感知机模型
定义 1.1 (感知机)
假设输入空间(特征空间)
,输出空间是
,输入
表示实例的特征向量,代表输入空间的点,输出
表示实例的类别,从输入空间到输出空间的映射:
称为感知机。其中 是感知机的参数, 称为权重或者权值向量, 称为偏置(bias)。sign(x)是符号函数,即:
感知机有如下几何解释,线性方程 ,对应于特征空间 的一个超平面 ,其中 是超平面的法向量, 是超平面的截距,这个超平面将特征空间里样本点分为正负两类。
1.2 感知机学习策略
1.2.1 数据集的线性可分性
定义1.2 ( 数据集的线性可分性) 给定一个数据集 ,其中 , ,如果存在一个超平面 :
数据集的正样本和负样本完全分到超平面的两侧,对于所有 的样本,有 ,所有 的样本,有 ,则称数据 为线性可分数据集
1.2.2 感知机学习策略
为了找到能将数据集分开的超平面,也就是找到参数 ,我们需要确定一个学习策略,即定义一个损失函数并将损失最小化。我们自然想到会使用分类点的错误数作为损失函数,但是这个损失函数关于 不是连续可导的,不容易优化求解。我们可选择每一个误分类点到超平面 的总距离,根据空间几何知识,点 到平面 的距离为:
其中 是 的 范数。对于分类错误的点来说, 和 异号,所以 因此,误分类点到超平面的距离是
那么对于所有误分类点集合 ,所有点到超平面的总距离为
不考虑 (个人感觉这里稍微有点问题,不考虑这一项,结果和加上这一项肯定是有差异的,这里这样操作应该是出于方便求导的考虑),就得到感知机的损失函数
对于给定的训练数据集
,感知机
学习的损失函数定义为:
显然这个损失函数是非负的,分类错误的点越少,损失函数值越小,给定一个训练数据集 ,损失函数 是 的连续可导函数
1.3 感知机学习算法
1.3.1 感知机算法原始形式
感知机算法用于求解一下最优化问题:
其中 是分错点的集合
算法 1.1 (感知机算法原始形式)
输入:训练数据集
,其中
,
,
,学习率
输出:
,感知机模型
(1) 选取初始值
(2) 在训练集中选取(x_i, y_i)
(3) 如果
(4) 转至(2) ,直到训练集中没有误分类点
我们可以直观的来理解这个算法,当有一个样本点被分错时,改变
,也就是调整了超平面,让它减少与分错点的距离,直到被分对。
以下例子摘自《统计学习方法》p29
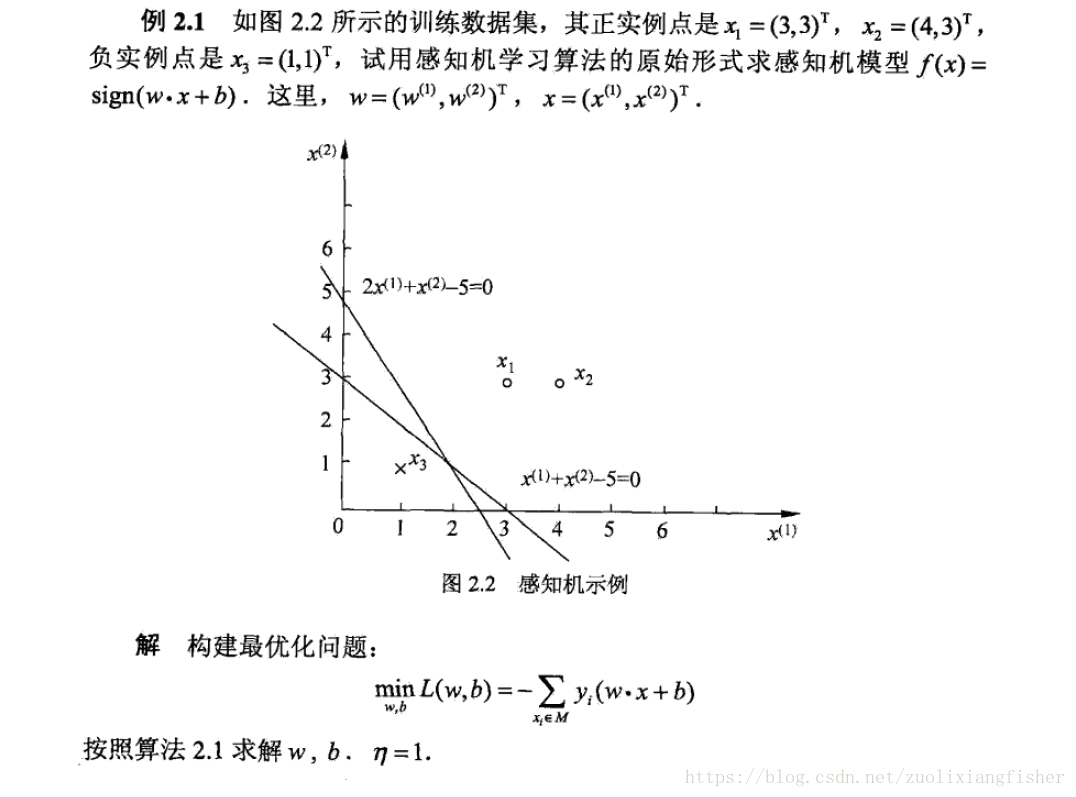

这是在计算中误分类点先后取 得到的分离超平面和感知机模型,如果在计算中误分类点依次取 ,那得到的平面就是 ,可以看到,感知机算法由于采用不同的初值或者选取不同的误分类点,解可能不一样。
1.3.2 算法的收敛性
可以证明,对于线性可分数据集感知机学习算法原始形式收敛,即经过有限次迭代可以得到一个将训练数据集完全划分的分离超平面和感知机模型,详细推导参考《统计学习方法》p31-p32
1.3.3 感知机学习算法的对偶形式
感知机算法的对偶形式,基本想法就是将 表示为 线性组合的形式
这里 ,表示第 i 个样本点由于分类错误而进行更新的次数,样本点如果更新次数越多,表示它离超平面越近,越难被区分。
算法 1.2 (感知机算法对偶形式)
输入:训练数据集
,其中
,
,
,学习率
输出:
,感知机模型
,
(1)
,
(2) 在训练集中选取(x_i, y_i)
(3) 如果
(4) 转至(2) ,直到训练集中没有误分类点
对偶形式中训练样本仅以内积的形式出现,为了方便,可以预先将训练集中样本间的内急计算出来存入到矩阵中,高等代数里这个矩阵称为 Gram矩阵
以下例子摘自《统计学习方法》p34-35

