链接:[ 全文章目录 ]
一、感知机模型[2.1]
超平面:
输入空间是n维向量,那么超空间就是(n-1)维向量
【键盘字母上面的数字1到0(10个不同的变量),如果想把它们分割开,需要有(10-1)个隔板(9个超空间)】
分离超平面(将n整合为2的超平面):
在一个平面中划一条线,使平面中的样本尽可能的分为正负两类。(一般判断是或不是)
(一)定义2.1
简单定义:【感知机就是 求出分离超平面,再 通过分离超平面来进行二分类 的一种模型。】
具体定义:


w∊Rn:叫作权值或权值向量
b∊R :叫作偏置
w·x表示w和x的内积(就是点积)
!注意,w和x都是长度为n的向量
感知机是一种 线性分类模型 ,属于 判别模型 。
感知机模型的假设空间是定义在特征空间中的 所有线性分类模型 或 线性分类器 ,
即函数集合 { f | f(x)=w·x+b } 。
(二)几何解释
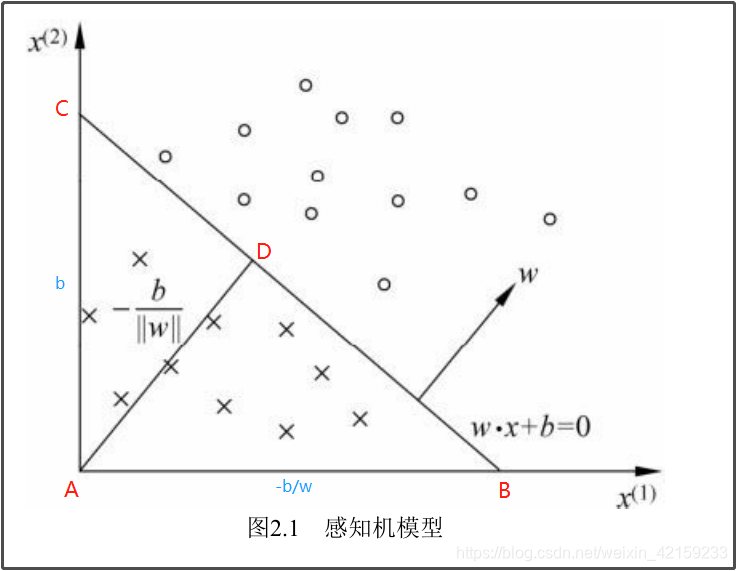
||w||:向量w的2范数是w中各个元素平方之和再开根号,就是向量的模(长度) ;
AD算出来是:
−1+w2
b
怎么变成:
−∣∣w∣∣b 也就是
−w2
b 的不是很清楚
二、感知机学习策略[2.2]
(一)数据集的线性可分型[2.2.1]
能用一条线 完全的 分割为两种类型,就称数据集有线性可分型。(不能有一类的某个点跑到另一类里面)
(二)感知机学习策略[2.2.2]
定义(经验)损失函数并将损失函数 极小化 ,求出w、b。
这里的损失函数为:误分类点到超平面(那条线)S的总距离。
具体推倒:
1、把点到直线距离公式摆上来,代入超平面方程
距离
d=A2+B2
∣Axi+Byi+C∣
已知超平面方程为:w·x+b=0,代入上式,得:
距离
d=w2
∣wxi+b∣=∣∣w∣∣∣wxi+b∣
2、为了去掉绝对值,我们现在看看误分类数据有什么特点
已知有个误分类的数据(xi, yi)
因为它误分类了,所以当:
(1)w·xi+b>0,即被分类为正类时,它的原分类yi必为-1(负类)
(2)w·xi+b<0,即被分类为负类时,它的原分类yi必为+1(正类)
那么对误分类的数据必有:
yi(w⋅xi+b)<0
而距离是正数,所以在前面加上负号,变成:
d=−∣∣w∣∣yi(wxi+b)
【乘上一个 “-yi” 就可以把绝对值去掉,还可以筛出误分类的数据(正确分类的距离必为负值)】
3、推广到多个点
M为误分类点的集合
(1)总距离为:
−∣∣w∣∣1xiϵM∑yi(w⋅x+b)
(2)因为w是超平面的法向量,与大小无关,而
∣∣w∣∣1是一个标量,所以可以忽略
∣∣w∣∣1
(3)得到感知机学习的损失函数(经验风险函数):
L(w,b)=−xiϵM∑yi(w⋅x+b)
(三)损失函数特性
1、非负(距离)
2、正确分类时值为0
3、损失函数是连续可导函数:在误分类时,它是线性函数;正确分类时它是常数函数。
三、感知机学习算法[2.3]
(一)感知机学习算法的原始形式[2.3.1]
通过 梯度下降法 求损失函数的极小值:
minw,bL(w,b)=−xiϵM∑yi(w⋅x+b)(2.5)
1、梯度下降法的几何解释:通过 不断的运算,使点向 极小值 逼近。
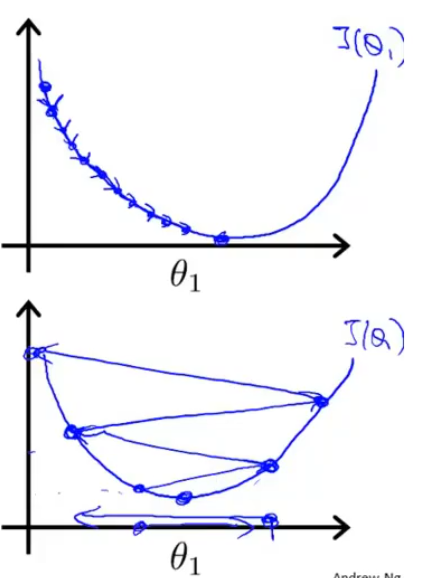
2、梯度下降法的具体算法【本章重点】
损失函数的梯度:
(由2.5对w求偏导)▽wL(w,b)=−xiϵM∑yixi
(由2.5对b求偏导)▽bL(w,b)=−xiϵM∑yi
(1)任取一个超平面(任取w,b)
(2)得到误分类点的集合M
(3)遍历误分类点求梯度对w,b进行更新:
w←w+ηyixi
b←b+ηyi
(4)直到L(w,b)=0
η(0<
η<=1)是步长,又称学习率,用来控制梯度大小。
(在吴恩达的machine learning中,学习率用的是
θ )
3、梯度下降法的其他解释
当一个实例点被误分类,即位于分离超平面的错误一侧时,则调整w,b的值,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面间的距离,直至超平面越过该误分类点使其被正确分类。
4、例2.1(略),通过梯度下降法的具体算法很容易理解
(二)算法的收敛性[2.3.2](算法收敛的证明)(尽量简化通俗了)
这里证明经过 有限次迭代 可以得到一个将训练数据集 完全正确划分 的分离超平面及感知机模型。
为了便于叙述与推导,
将偏置b并入权重向量w,记作:
w^=(wT,b)T,
同样也将输入向量加以扩充,加进常数1,记作:
x^=(xT,1)T 。
这样,
w^∊R N+1 ,
x^∊R N+1 。 显然,
w^·
x^=w·x+b。
结论:

1、对于(1)书中的证明
(1)由于训练数据集是线性可分的,存在超平面可将训练数据集完全正确分开,
取此超平面为
w^opt⋅x^=wopt⋅x+bopt=0,使
∣∣w^opt∣∣=1。由于对有限的i=1,2,…,N,均有:
yi(w^opt⋅xi^)=yi(wopt⋅x+bopt)>0
所以存在
γ=mini{yi(wopt⋅x+bopt)}
使
∗∗∗∗∗∗yi(w^opt⋅xi^)=yi(wopt⋅x+bopt)≥γ(公式1)∗∗∗∗∗∗
(2)解释
-
w^opt、wopt、bopt的下标opt的意思是:【对任意可选的】
w^、w、b。只要满足式子即可。
-
∣∣w^opt∣∣=1,原因:
w^opt可以乘上任意常数使公式1都成立,所以,为了特殊化,使
w^opt为单位长度,一般是
∣∣w^opt∣∣=1
-
γ就是一个大于0的数,没啥意义
2、对于(2)书中的证明(含解释)
感知机算法从
w^0=0 (方便后面推导) 开始,如果实例被误分类,则更新权重。
分步证明每一步最终都会得到一个公式,最后进行合并得到推论
分步证明1
(1) 令 k-1 是第k个误分类实例之前的扩充权重向量(就是
w^在右下角加了个k-1的下标),即
w^k−1=(wk−1T,bk−1)T
(2) 则第k个误分类实例的前提条件(第k次更新前的损失函数)是【这里是把上面的
wk−1和
bk−1代入了损失函数】
yi(w^k−1⋅x^i)=yi(wk−1⋅xi+bk−1)≤0
小于0上面有推导,等于0是因为存在没有误分类的情况
(3) 若(xi,yi)是被
w^k−1=(wk−1T,bk−1)T误分类的数据,则w和b的更新是
wk←wk−1+ηyixi
bk←bk−1+ηyi
【就是w和b的更新公式加了个下标】
根据上面的两个更新公式化简得:
∗∗∗∗∗∗w^k=w^k−1+ηyix^i(公式2)∗∗∗∗∗∗
化简过程如下
w^k=(wkT,bk)T=wk+bk=wk−1+ηyixi+bk−1+ηyi=[wk−1+bk−1]+[ηyi(xi+1)]=w^k−1+ηyix^i
分步证明2
(4) 由公式2
w^k=w^k−1+ηyix^i
可以求出:
w^k⋅w^opt=w^k−1⋅w^opt+η[yix^i⋅w^opt]
(5)
由公式1(的一部分)
yi(w^opt⋅xi^)≥γ
我们就可以把上面(4)式子里面方括号的东西换掉:
w^k−1⋅w^opt+η[yix^i⋅w^opt]≥w^k−1⋅w^opt+ηγ
(6) 我们把(5)中不等式的右边推广一下,得到(
η和
γ都是正的):
左边≥w^k−1⋅w^opt+ηγ≥w^k−2⋅w^opt+2⋅ηγ≥⋅⋅⋅≥w^0⋅w^opt+k⋅ηγ
这里
k>=1,kϵN+(k是大于等于1的正整数)
由(4)和(5)整理得:
w^k⋅w^opt≥w^0⋅w^opt+k⋅ηγ=k⋅ηγ(w^0=0)
得到
∗∗∗∗∗∗w^k⋅w^opt≥k⋅ηγ(公式3)∗∗∗∗∗∗
分步证明3
(7) 由分步证明1得出的公式2 “
w^k=w^k−1+ηyix^i ”,等式两边平方得:
∣∣w^k∣∣2=∣∣w^k−1∣∣2+2⋅w^k−1⋅ηyix^i+η2yi2∣∣x^i∣∣2
因为yi取正负1,所以
yi2=1,就变成了书中的式子(最后那项少了
yi2):
∣∣w^k∣∣2=∣∣w^k−1∣∣2+2⋅w^k−1⋅ηyix^i+η2∣∣x^i∣∣2
(8) 由分步证明1的(2)中式子 “
yi(w^opt⋅xi^)≤0 ”;再由于“步进
η”必大于0
所以(7)最后式子中的
2⋅w^k−1⋅ηyix^i(必定小于等于0)
即有:
∣∣w^k−1∣∣2+2⋅w^k−1⋅ηyix^i+η2∣∣x^i∣∣2≤∣∣w^k−1∣∣2+η2∣∣x^i∣∣2
(9) 最后,将
∣∣x^i∣∣看作是R的下限,得到:
∣∣w^k−1∣∣2+2⋅w^k−1⋅ηyix^i+η2∣∣x^i∣∣2≤∣∣w^k−1∣∣2+η2∣∣x^i∣∣2≤∣∣w^k−1∣∣2+η2R2
仿造分步证明2(6)中的推广,得到
∣∣w^k−1∣∣2+η2R2≤∣∣w^0∣∣2+k⋅η2R2
最后,整理(7)(9)得:
∗∗∗∗∗∗∣∣w^k∣∣2≤kη2R2(公式4)∗∗∗∗∗∗
分步证明4
由公式3 “
w^k⋅w^opt≥k⋅ηγ ”,
和公式4 “
∣∣w^k∣∣2≤kη2R2 ”,得:
kηγ≤w^k⋅w^opt≤∣∣w^k∣∣⋅∣∣w^opt∣∣≤k
ηR(∣∣w^opt∣∣=1,左边用公式3,右边用公式4)
由不等式最左边与最右边 “
kηγ≤k
ηR ” 两边同时平方化简得:
k2γ≤kR2
移下字母得:
∗∗∗∗∗∗k≤(γR)2(证毕)∗∗∗∗∗∗
定理表明,误分类的次数k是有上界的,经过有限次搜索可以找到将训练数据完全正确分开的分离超平面。
当训练集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。
*公式3和公式4的意义:
公式3:
w^k⋅w^opt≥k⋅ηγ ,说明
w^k 随k的变大,下界变大
公式4 “
∣∣w^k∣∣2≤kη2R2 ”,说明
w^k的绝对值有上界
公式3+公式4的几何意义,
w^k向量通过旋转越来越接近
w^opt向量
(三)感知机学习算法的对偶(等效)形式[2.3.3]
对偶形式对于原始形式最大的不同在于,对偶形式多给了 不同的点不同权重 ,而且对于计算机来说,计算量更小。
(因为在超平面附近的点是最容易误分类的,所以给这些点高权重,可以更快收敛)
在原始形式中:
w←w+ηyixib←b+ηyi
那么把上面的递推式子整合(对全部的n个点),得到:
w=i=1∑Nαiyixib=i=1∑Nαiyi
上式中的 “
αi=niη” ,
η是递推式子中本来就有的,
ni其实就是个计数(出现几次就是几)的变量,那个点出现的次数越多,就代表着那个点离超平面越近,
ni代表的权重越大。
这里把原始形式的经验损失函数摆上来:
L(w,b)=−xiϵM∑yi(w⋅x+b)≥0
把上面w的整合式代入,得:
−xiϵM∑yi(i=1∑Nαiyixi⋅x+b)≥0
去负号:
xiϵM∑yi(i=1∑Nαiyixi⋅x+b)≤0
这时,在原始形式中更新w和b,就变成了更新
αi和b,即:
αi←αi+η(就是计数器的意思)b←b+ηyi
补充,书中的Gram矩阵
Gram矩阵,用来储存不同向量的内积
比如有x1,x2,x3,三个向量,那么Gram矩阵表示为
| x1·x1 |
x1·x2 |
x1·x3 |
| x2·x1 |
x2·x2 |
x2·x3 |
| x3·x1 |
x3·x2 |
x3·x3 |
例子:x1=(3,3)T,x2=(4,3)T,x3=(1,1)T,它们生成的Gram矩阵为:

第二章结束… …
链接:[ 全文章目录 ]
