摘要
本文主要介绍降维技术、主成分分析法,及其应用。
目录
一、降维
1.1 降维简介
降维是对数据高维度特征的一种预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为了应用非常广泛的数据预处理方法。
降维具有如下一些优点:
(1)使得数据集更易使用
(2)降低算法的计算开销
(3)去除噪声
(4)使得结果容易理解
1.2 主要降维方法
1.2.1 主成分分析
主成分分析,Principal Component Analysis,PCA。在PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行了降维处理。
1.2.2 因子分析
因子分析,即Factor Analysis。在因子分析中,我们假设在观察数据的生成中有一些观察不到的隐变量(latent variable)。假设观察数据是这些隐变量和某些噪声的线性组合。那么隐变量的数据可能比观察数据的数目少,也就是说通过找到隐变量就可以实现数据的降维。因子分析已经应用于社会科学、金融和其他领域中了。
1.2.3 独立成分分析
独立成分分析,即Independent Component Analysis,ICA。ICA假设数据是从 N 个数据源生成的,这一点和因子分析有些类似。假设数据为多个数据源的混合观察结果,这些数据源之间在统计上是相互独立的,而在PCA中只假设数据是不相关的。同因子分析一样,如果数据源的数目少于观察数据的数目,则可以实现降维过程。
二、主成分分析法
2.1 主成分分析法简介
主成分分析方法,即PCA(principal Component Analysis),是一种使用最广泛的数据压缩算法。在PCA中,数据从原来的坐标系转换到新的坐标系,由数据本身决定。转换坐标系时,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向……重复该过程,直至新坐标轴数量足够多。
通过这种方式获得的新的坐标系,我们发现,大部分方差都包含在前面几个坐标轴中,后面的坐标轴所含的方差远小于前面的,。于是,我们可以忽略余下的坐标轴,只保留前面的几个含有绝大部分方差的坐标轴。事实上,这样也就相当于只保留包含绝大部分方差的维度特征,而忽略包含方差小的特征维度,也就实现了对数据特征的降维处理。
2.2 主成分分析法的数学推导
在此假设读者具有线性代数知识(若否,出门右转,这里可能不适合你!)
2.2.1 数据集
记含有
个数据点的数据集
,其中,第
个数据点为:
假设 已经中心化,否则,只需要每一个 进行:
进可以将第 个维度的数据的中心与第 个坐标轴的原点重合,此时 的中心与 的原点重合,方便下面的推导。
在
中标准正交基为
,其中,
。对于
用标准正交基来线性表示为:
左右用 分别作用,有标准正交基性质可知:
所以,对于 可以写成:
于是, 在以 为方向的坐标轴上的投影距离即为 ,即是说, 在标准正交基 下第 维的坐标为 。
2.2.2 新坐标系需要满足的条件
现在需要取新的一组规范正交基 生成新的坐标轴系,使得原始数据 在第一个新坐标轴上原始数据 方差最大,第二个新坐标轴上 方差次大…即第 个新坐标轴上 方差第 大。
2.2.3 新坐标系的存在性
假设存在这样的一组新的标准正交基
,可知
在新坐标系的坐标表示为:
对于新的第1个维度,
的各个数据点
的坐标为
,为使得其尽可能分散开,也就是说其方差最大,即是:
使用一点简单的技巧处理上式,首先,可知:
所以,可得:
由于
属于标准正交基,则可得:
使用拉格朗日乘子法求解,记
为拉格朗日乘子,则:
可得:
代入原式,方差的表达式即是:
可知 是 的特征值, 是对应的单位特征向量。需要求出 的最大特征值 和对应的单位特征向量 ,此时方差最大等于 。
同理,对于新的第2个维度,
的各个数据点
的坐标为
,为使得其方差第2大,即是
所要求解的 即是 的第 大的特征值,取对应的单位特征向量为 。
对于新的第
个维度,
的各个数据点
的坐标为
,为使得其方差第
大,即是:
此时的所求的方差等于 ,即是 的第 大的特征值,
注意到 是 的协方差矩阵(严格地说, 的协方差矩阵为 ,但常系数在这儿可以忽略),并且 是实对称矩阵,由线性代数知识可知:
Thm. 实对称矩阵都可以对角化,且不同特征值对应的特征向量互相正交。
可知,对于实对称矩阵 必有 个实数特征值,记为 (若是重根,依次排列),对应可以取到 个不同的单位特征向量 (重根的特征向量可以取特征子空间的基),且互相正交。
于是 便是所求的新的标准正交基,同时称 为第一主成分, 为第二主成分……以此类推。在其对应的新坐标系下,满足条件:第1个新坐标轴是原始数据中方差最大的,第2个新坐标轴是与第一个新坐标轴正交且方差次大的……
到此,可知知道,必存在满足条件的新的坐标系,
在主成分来表示为:
2.2.4 主成分的选择
既然知道必存在满足条件的新的坐标系,在新坐标系中,选择前
个特征值和对应的特征向量作为主成分,使用前
个主成分
来表示
,则需要
保存更多关于
的信息。一种想法是这
个维度的方差贡献率达到所设定的阀值。一般地,取阀值
,则
需要满足:
取定
后,求得
,则
在此前
个主成分下的表示即是:
在 下, 降至 维后坐标即是:
换一种表达方式,为:
2.2.5 主成分的另一种表示
在一些些书籍上称呼主成分方式是与此不同的,令
是
经过坐标变换后的在新坐标系下表示,由上面推导可知:
提取 的第一主成分为:
提取
的第二主成分为:
直至到所需要 的第 个主成分。
实际上, 中数据点 经变换后的 ,便将 的 个维度转化为少数几个维度(即主成分),其中每个主成分都能够反映原始数据的大部分信息,且所含信息互不重复。
2.3 算法步骤
2.3.1 特征值和投影矩阵求解
输入:样本集
;
过程:
1. 对所有样本进行中心化:
;
2. 计算样本的协方差矩阵
;
3. 对协方差矩阵
做特征分解;
4. 求出
个特征值
和所对应的单位特征向量
。
输出:特征值
,投影矩阵
。
2.3.2 给定维数降维
输入:低维空间的维数
;
过程:
1. 取最大的
个特征值
和所对应的单位特征向量
;
2. 求出
在低维空间的坐标:
。
输出:
中
在低维空间的坐标。
2.3.3 给定阀值降维
输入:阀值
;
过程:
1. 取
使得
;
2. 取最大的
个特征值
和所对应的单位特征向量
;
3. 求出
在低维空间的坐标:
。
输出:
中
在低维空间的坐标。
三、示例
3.1 二维数据的主成分
原始数据的可视化为:
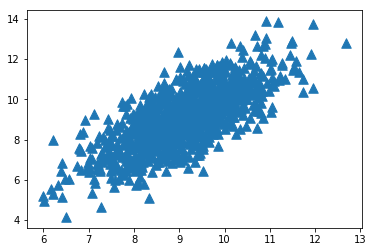
图1
进行上述的坐标变换,选择方差最大新坐标轴,并作投影为:
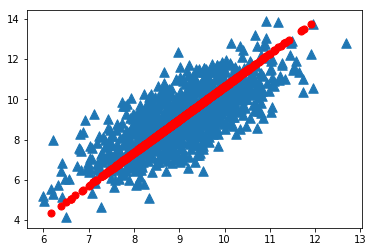
图2
3.2 二维数据划分
在这里考虑将二维的数据进行划分,首先降维至一维后,再在该一维子空间中进行划分。
效果如图所示:
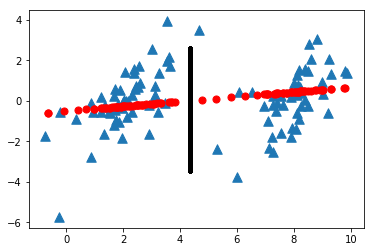
图3
图中,蓝色点样本点为原始数据,红色点为降维后的在一维子空间上的投影,黑色线段为在一维子空间上进行的划分。在低维的子空间进行划分后,在回到原始的高维空间,将对应的数据点分类,这是主成分分析法的一个应用。
四、小结
数据从原来的坐标系转换到了新的坐标系,使得在各新坐标系投影方差最大,而这样的坐标系是存在的,但不是不唯一的。通过主成分分析法进行降维处理,我们可以知道其一些优缺点:
优点:降低数据的复杂性,识别最重要的多个特征。
缺点:不一定需要,且可能损失有用信息。
适用数据类型:数值型数据。
五、参考文献
[1]周志华.机器学习[M].北京:清华大学出版社,2016.
[2]Peter Harrington.机器学习实战[M].北京:人民邮电出版社,2013.
[3]韩家炜等.数据挖掘概念与技术[M].北京:机械工业出版社,2012.
六、附录
《机器学习实战》的代码,其代码的资源网址为:
https://www.manning.com/books/machine-learning-in-action
其中,pca.py文件为:
"""
Created on Mon Jun 4 13:48:35 2018
@author: Diky
"""
"""
┏┓ ┏┓+ +
┏┛┻━━━━━━━┛┻┓ + +
┃ ┃
┃ ━ ┃ ++ + + +
█████━█████ ┃+
┃ ┃ +
┃ ┻ ┃
┃ ┃ + +
┗━━┓ ┏━┛
┃ ┃
┃ ┃ + + + +
┃ ┃
┃ ┃ +
┃ ┃
┃ ┃ +
┃ ┗━━━┓ + +
┃ ┣┓
┃ ┏┛
┗┓┓┏━━━┳┓┏┛ + + + +
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛+ + + +
Code is far away from bug with the animal protecting
神兽保佑 代码无bug
"""
from numpy import *
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [list(map(float,line) )for line in stringArr]
return mat(datArr)
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #remove mean
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
lowDDataMat = meanRemoved * redEigVects#transform data into new dimensions
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
def replaceNanWithMean():
datMat = loadDataSet('secom.data', ' ')
numFeat = shape(datMat)[1]
for i in range(numFeat):
meanVal = mean(datMat[nonzero(~isnan(datMat[:,i].A))[0],i]) #values that are not NaN (a number)
datMat[nonzero(isnan(datMat[:,i].A))[0],i] = meanVal #set NaN values to mean
return datMat测试文件main.py为:
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 4 13:48:35 2018
@author: Diky
"""
from pca import *
from matplotlib import *
import matplotlib.pyplot as plt
import matplotlib.image as mpimg # mpimg 用于读取图片
import numpy as np
dataMat = loadDataSet("testSet.txt")
lowDMat, reconMat = pca(dataMat, 1)
shape(lowDMat) #查看矩阵维数
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:,0].flatten().A[0], dataMat[:,1].flatten().A[0], marker="^", s=90)
ax.scatter(reconMat[:,0].flatten().A[0], reconMat[:,1].flatten().A[0], marker="o", s=50, c="red")
plt.show()