主成分PCA分析的基本步骤:
· 对数据进行归一化处理(代码中并非这么做的,而是直接减去均值)
· 计算归一化后的数据集的协方差矩阵
· 计算协方差矩阵的特征值和特征向量
· 保留最重要的k个特征(通常k要小于n),也可以自己制定,也可以选择一个阈值,然后通过前k个特征值之 和减去后面n-k个特征值之和大于这个阈值,则选择这个k
· 找出k个特征值对应的特征向量
· 将m * n的数据集乘以k个n维的特征向量的特征向量(n * k),得到最后降维的数据。
关于主成分分析的详细讲解可以参考这里
import pandas as pd
inputfile = 'B:\pycharm\DataMining\data\principal_component.xls'
outputfile = 'B:\pycharm\DataMining\data\dimention_reducted.xls'
data = pd.read_excel(inputfile)
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
print(pca.components_) #返回模型的各个特征向量
print('每个成分各自方差百分比 :' )
print(pca.explained_variance_ratio_)#返回各个成分各自的方差百分比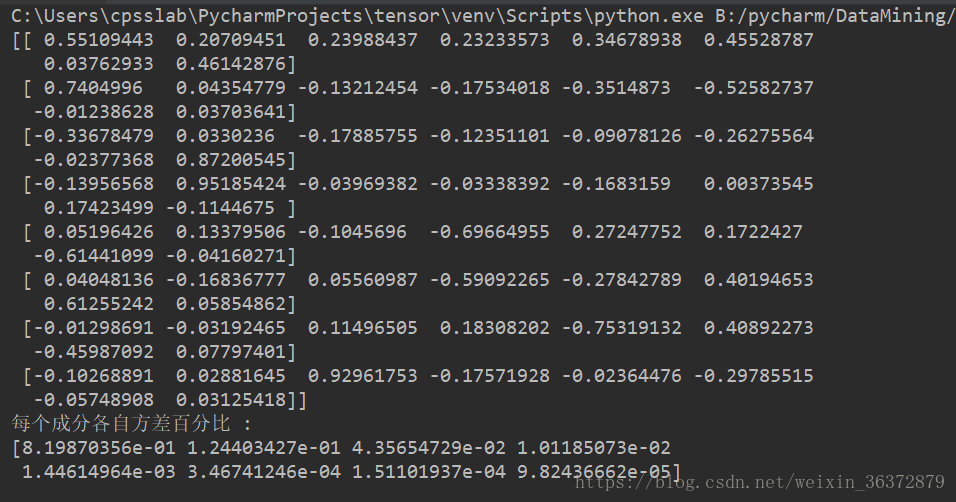
可以看到每一个特征向量和每一个成分各自方差百分比
pca = PCA(3) #保留主成分的个数
pca.fit(data)
low_d = pca.transform(data) #降低维度
pd.DataFrame(low_d).to_excel(outputfile) #输出文件
pca.inverse_transform(low_d) #恢复原始数据降维之后的数据: