1、sklearn中关于异常检测的说法
Novelty and Outlier Detection:
Many applications require being able to decide whether a new observation belongs to the same distribution as existing observations (it is an inlier), or should be considered as different (it is an outlier). Often, this ability is used to clean real data sets. Two important distinction must be made:
novelty detection:
The training data is not polluted by outliers, and we are interested in detecting anomalies in new observations.
outlier detection:
The training data contains outliers, and we need to fit the central mode of the training data, ignoring the deviant observations.
也就是说主要方法有两种:
1)、novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外新发现的样本;
2)、outlier detection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样本,忽视训练样本中的其它异常点;
sklearn提供了一些机器学习方法,可用于奇异(Novelty )点或异常(Outlier)点检测,包括OneClassSVM、Isolation Forest、Local Outlier Factor (LOF) 等。其中OneClassSVM可用于Novelty Detection,而后两者可用于Outlier Detection。
2、OneClassSVM(Unsupervised Outlier Detection)
2.1、关于一类SVM的形象解释:
作者:知乎用户
链接:https://www.zhihu.com/question/22365729/answer/115048306
最近因为做到异常行为检测、剧烈运动分析方面的任务,接触到了一类svm,尽我所能的介绍下我掌握的知识吧。先举个例子。比方说,我们要判断一张照片里的人脸,是男性还是女性,这是个二分类问题。对于一张未知性别的人脸,经过svm分类器分类(经典的二分类svm),我们会给出他\她是男性or不是男性的结果(不是男性就是女性啦,暂时不考虑第三性别,O(∩_∩)O~;为什么这么表达,是因为为了与下面的一类svm概念做区别)。那么经典svm训练的方式呢,就是将一堆已标注了男女性别的人脸照片(假设男性是正样本,女性是负样本),提取出有区分性别的特征(假设这种能区分男女性别的特征已构建好)后,通过svm中的支持向量,找到这男女两类性别特征点的最大间隔。进而在输入一张未知性别的照片后,经过特征提取步骤,就可以通过这个训练好的svm很快得出照片内人物的性别,此时我们得出的结论,我们知道要么是男性,不是男性的话,那一定是女性。以上情况是假设,我们用于训练的样本,包括了男女两类的图片,并且两类图片的数目较为均衡。现实生活中的我们也是这样,我们只有在接触了足够多的男生女生,知道了男生女生的性别特征差异后(比方说女性一般有长头发,男性一般有胡子等等),才能准确判断出这个人到底是男是女。但如果有一个特殊的场景,比方说,有一个小和尚,他从小在寺庙长大,从来都只见过男生,没见过女生,那么对于一个男性,他能很快地基于这个男性与他之前接触的男性有类似的特征,给出这个人是男性的答案。但如果是一个女性,他会发现,这个女性与他之前所认知的男性的特征差异很大,进而会得出她不是男性的判断。注意咯,这里所说的 “她不是男性” 的判断,与我们使用二分类svm中所说的 “不是男性” 的判断,虽然结论相同,但却不是同一个概念。 我们在使用经典二分类svm去分类人脸性别时,当我们判定未知样本不是男性时,我们会同时得到她是个女性的结论(因为我们是知道另一类,也即女性类别的),但对于以上介绍的特殊场景,我们只能根据它与小和尚认知的男性特征不一致,得出它不是男性的判断,至于它是女性呢,还是第三性别,甚至是外星人,对不起,并不知道,我们只能将其排除出男性的范围,并不能给它做出属于哪类的决策。以上场景就是一类svm的典型应用场景,当出现一个分类问题中,只有一种类型的样本,或有两种类型样本,但其中一类型样本数目远少于另一类型样本数目(如果此时采用二分类器,training set中正负样本不均衡,可能造成分类器过于偏向数目多的样本类别,使train出来的model有bias)时,就可以考虑使用一类svm进行分类。再举例子到异常行为检测上,比方说,在银行存取款大厅,正常情况大家都是在坐席耐心叫号等待,抑或取号,在柜台接受服务等。这些行为虽然各有不同,但却都会有比较相类似的特征,例如都会有比较一致性的运动方向(比如说,正常走动,取号,排队等),不是很大的运动幅度等,但对于一些异常行为,比如说银行大厅内的打斗、斗殴,抢劫等,你不能要求这些行为也按套路出牌,如武侠片里先摆pos、再出脚,最后再手上各种招式,正是因为这些异常行为无法有效度量。我们就可以将一类svm应用于其中,比方说,我们提取出人类在银行的正常行为操作的特征,并使用一类svm将之正确表达,那么对于一个异常行为,我们可以很快得出,这货提取的特征和我这个分类器包含的特征不一致,那么它肯定就不是正常的行为特征,那么就可以发出报警了。以上就是我口语表达的一类svm分类器的介绍,有很多不严谨的地方,望海涵。
2.2、OneClassSVM主要参数和方法
class sklearn.svm.OneClassSVM(kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1, random_state=None)
参数:
kernel:核函数(一般用高斯核)
nu:设定训练误差(0, 1]
方法:
fit(x):训练,根据训练样本和上面两个参数探测边界。(注意是无监督哦!)
predict(x):返回预测值,+1就是正常样本,-1为异常样本。
decision_function(X):返回各样本点到超平面的函数距离(signed distance),正的为正常样本,负的为异常样本。
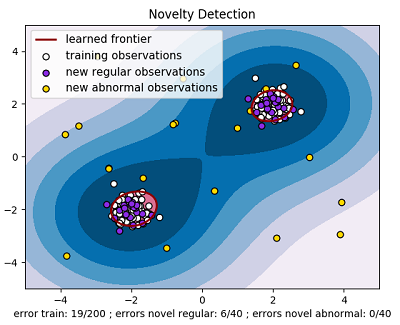
2.3、OneClassSVM官方实例
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# Generate train data
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
# plot the line, the points, and the nearest vectors to the plane
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("Novelty Detection")
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.PuBu) #绘制异常样本的区域
a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='darkred') #绘制正常样本和异常样本的边界
plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors='palevioletred') #绘制正常样本的区域
s = 40
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white', s=s, edgecolors='k')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='blueviolet', s=s,
edgecolors='k')
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='gold', s=s,
edgecolors='k')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([a.collections[0], b1, b2, c],
["learned frontier", "training observations",
"new regular observations", "new abnormal observations"],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
plt.xlabel(
"error train: %d/200 ; errors novel regular: %d/40 ; "
"errors novel abnormal: %d/40"
% (n_error_train, n_error_test, n_error_outliers))
plt.show()结果:
3、总结
1、严格地讲,OneClassSVM不是一种outlier detection方法,而是一种novelty detection方法:它的训练集不应该掺杂异常点,因为模型可能会去匹配这些异常点。 但在数据维度很高,或者对相关数据分布没有任何假设的情况下,OneClassSVM也可以作为一种很好的outlier detection方法。
2、其实在分类问题中,当两类样本及其不平衡时,也可以将个数比例极小的那部分当做异常点来处理,从另外一种角度来完成分类任务!
4、参考文献:
1、http://scikit-learn.org/stable/modules/outlier_detection.html#outlier-detection