尊重原创,转载请标明出处 http://blog.csdn.net/abcdef314159
在上一篇中我们分析了HashMap的源码,了解HashMap是以数组加链表的形式存储的,这一篇我们结合上一篇的内容来分析一下LinkedHashMap的源码,在阅读之前最好能把上一篇的《Android HashMap源码详解》看一遍,尤其是HashMap的结构图要理解清楚,我们来先看一下LinkedHashMap的构造方法,由于比较多,我们随便挑一个
-
public LinkedHashMap(
-
int initialCapacity, float loadFactor, boolean accessOrder) {
-
super(initialCapacity, loadFactor);
-
init();
-
this.accessOrder = accessOrder;
-
}
我们看到上面几个参数initialCapacity是初始化空间大小,loadFactor是加载因子,就是当他的size大于initialCapacity*loadFactor的时候就会扩容,他的默认值是0.75,我们看一下
-
/**
-
* The default load factor. Note that this implementation ignores the
-
* load factor, but cannot do away with it entirely because it's
-
* mentioned in the API.
-
*
-
* <p>Note that this constant has no impact on the behavior of the program,
-
* but it is emitted as part of the serialized form. The load factor of
-
* .75 is hardwired into the program, which uses cheap shifts in place of
-
* expensive division.
-
*/
-
static final float DEFAULT_LOAD_FACTOR = . 75F;
我们看上面的注释,意思是HashMap已经忽略了加载因子,但又不能完全废除它,其实我们看到HashMap中是没有任何用到,我们来看一下
-
public HashMap(int capacity, float loadFactor) {
-
this(capacity);
-
-
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
-
throw new IllegalArgumentException( "Load factor: " + loadFactor);
-
}
-
-
/*
-
* Note that this implementation ignores loadFactor; it always uses
-
* a load factor of 3/4. This simplifies the code and generally
-
* improves performance.
-
*/
-
}
所以这个loadFactor没有任何作用,我们看下面的注释大概也能明白,HashMap使用的加载因子是3/4,也就是0.75,这个我们在上一篇的 private HashMapEntry<K, V>[] makeTable(int newCapacity)方法中已经讲过,这里就不在介绍。我们看到LinkedHashMap的构造方法中还有一个参数accessOrder,我们看一下注释
-
/**
-
* True if access ordered, false if insertion ordered.
-
*/
-
private final boolean accessOrder;
我们知道,LinkedHashMap继承了HashMap,所以他的数据存储还是按照HashMap的存储结构存储的,即数组加链表(单向链表),但LinkedHashMap内部又维护了一个双向的环形链表,它主要是在删除的时候用到,删除最先加入的元素,上面的accessOrder主要对双向环形链表有影响,如果是true则表示双向环形链表按照访问的顺序存储,如果是false则表示按照插入的顺序存储,区别就是如果是插入顺序则双向环形链表的结构是不变的,如果是访问顺序则每次访问的时候比如get方法就会把get到的元素从链表中删除然后重新加到链表的尾部,因为尾部表示最新加入的,删除的时候是从头部开始删除,尾部是最后删除的,符合最近使用原则,LruCache中封装的LinkedHashMap是按照访问顺序存储的,因为LruCache实现的是LRU: 最近最少使用(Least Recently Used)原则。在讲LinkedHashMap的一些常用方法之前我们来先看一个类LinkedEntry
-
static class LinkedEntry<K, V> extends HashMapEntry<K, V> {
-
LinkedEntry<K, V> nxt;
-
LinkedEntry<K, V> prv;
-
-
/** Create the header entry */
-
LinkedEntry() {
-
super( null, null, 0, null);
-
nxt = prv = this;
-
}
-
-
/** Create a normal entry */
-
LinkedEntry(K key, V value, int hash, HashMapEntry<K, V> next,
-
LinkedEntry<K, V> nxt, LinkedEntry<K, V> prv) {
-
super(key, value, hash, next);
-
this.nxt = nxt;
-
this.prv = prv;
-
}
-
}
我们看到LinkedEntry继承了HashMapEntry,并且比他多了两个属性,nxt表示链表的下一个元素,prv表示链表的前一个元素,注意这里的nxt和HashMapEntry中的next是不一样的,这里的nxt是指双向环形链表的下一个,而HashMapEntry中的next是指存放数组挂载的下一个,是存放位置上的。我们看到构造方法中有这样一个方法init
-
/**
-
* A dummy entry in the circular linked list of entries in the map.
-
* The first real entry is header.nxt, and the last is header.prv.
-
* If the map is empty, header.nxt == header && header.prv == header.
-
*/
-
transient LinkedEntry<K, V> header;
-
-
void init() {
-
header = new LinkedEntry<K, V>();
-
}
他初始化了一个header,这个header是双向环形链表的头,不存放任何数据的,我们看到上面的注释,意思是第一个真正的entry是header的下一个,最后一个entry是header的前一个,如果为null,则他的前一个和后一个都等于header,因为他是个环形链表,所以header的下一个也是最先加入的,header的前一个是最后一个加入的,下面我给大家画个图可能就会明白一些
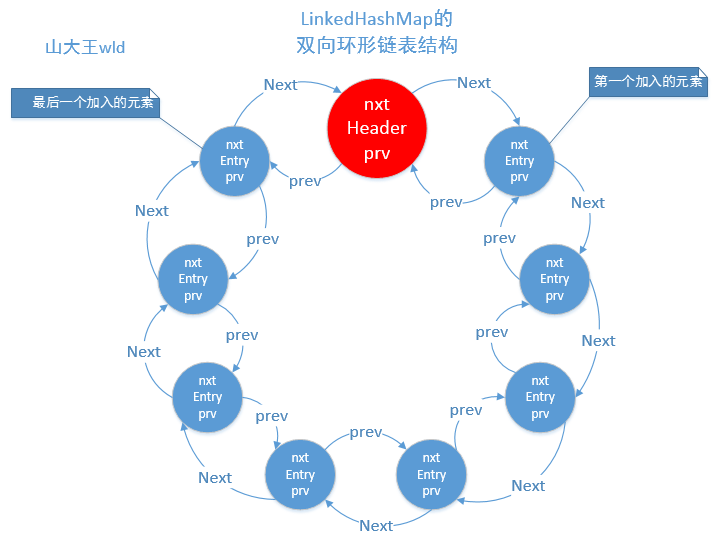
下面我们来看一下他的一些方法
-
public Entry<K, V> eldest() {
-
LinkedEntry<K, V> eldest = header.nxt;
-
return eldest != header ? eldest : null;
-
}
得到最老的元素,也是最先存放的元素,由上图我们可以看到最先存放的元素是header的下一个,这个比较好理解,我们在来看其他的一些方法
-
void addNewEntry(K key, V value, int hash, int index) {
-
LinkedEntry<K, V> header = this.header;
-
-
// Remove eldest entry if instructed to do so.
-
LinkedEntry<K, V> eldest = header.nxt;
-
if (eldest != header && removeEldestEntry(eldest)) {
-
remove(eldest.key);
-
}
-
-
// Create new entry, link it on to list, and put it into table
-
LinkedEntry<K, V> oldTail = header.prv;
-
LinkedEntry<K, V> newTail = new LinkedEntry<K,V>(
-
key, value, hash, table[index], header, oldTail);
-
table[index] = oldTail.nxt = header.prv = newTail;
-
}
所有的操作都是先找到header,看到第6行,在添加新的元素的时候如果removeEldestEntry方法返回true,将移除最老的元素,也就是header的下一个元素,removeEldestEntry默认返回为false,我们也可以自己复写他。
-
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
-
return false;
-
}
如果不移除最老的元素,当添加到一定数量的时候可能会扩容。我们仔细看addNewEntry方法中的最后3行代码,首先是new了一个新的LinkedEntry,然后在加入到table中,最后一行中header.prv = newTail,这回大家可能及明白了header的前一个元素就是新元素,也是最后一个加入的,当然上面的双向链表和存储结构是不冲突的,上面的方法还有一个奇葩的地方,就是加入一个元素之后他的size并没有改变。还有一个void addNewEntryForNullKey(V value)方法,其实和上面差不多,这个就不在叙述,我们在往下看,其中还有一个constructorNewEntry方法,他和上面也差不多,只不过他没有调用移除方法,在下面就是public V get(Object key)方法了,这个方法和HashMap的get方法差不多,只不过他多了一个判断,因为LinkedHashMap多了一个链表的维护,所以他要判断是否是按照访问顺序来维护,
-
if (accessOrder)
-
makeTail((LinkedEntry<K, V>) e);
如果是按照访问顺序来维护的就会调用makeTail方法。
-
private void makeTail(LinkedEntry<K, V> e) {
-
// Unlink e
-
e.prv.nxt = e.nxt;
-
e.nxt.prv = e.prv;
-
-
// Relink e as tail
-
LinkedEntry<K, V> header = this.header;
-
LinkedEntry<K, V> oldTail = header.prv;
-
e.nxt = header;
-
e.prv = oldTail;
-
oldTail.nxt = header.prv = e;
-
modCount++;
-
}
上面代码很好理解,就是把元素e从双向链表中删除,然后添加在header的前一个,就相当于新添加的一个,因为他是双向链表,所以断开的时候要保证他的前一个和后一个连接,不能让他断了。其中还有几个preModify和postRemove方法,都比较简单就不在介绍,我们来看一下containsValue方法
-
public boolean containsValue(Object value) {
-
if (value == null) {
-
for (LinkedEntry<K, V> header = this.header, e = header.nxt;
-
e != header; e = e.nxt) {
-
if (e.value == null) {
-
return true;
-
}
-
}
-
return false;
-
}
-
-
// value is non-null
-
for (LinkedEntry<K, V> header = this.header, e = header.nxt;
-
e != header; e = e.nxt) {
-
if (value.equals(e.value)) {
-
return true;
-
}
-
}
-
return false;
-
}
我们上一篇讲到HashMap的时候也说到containsKey和containsValue方法,HashMap的containsValue方法是通过遍历数组,然后在根据数组的next一个一个查找的,而LinkedHashMap的containsValue方法是遍历双向链表,从链表的header开始查找,因为是环形的,如果查找一圈还没找到则返回false。还有一个clear方法,他是先调用HashMap的clear方法把所有数据全部清除了,然后在通过循环把链表清空。剩下的就是迭代了,其中LinkedHashIterator类也是从header开始的,这里就不在详述。由于LinkedHashMap的源码很少,今天就暂时先分析到这,下一篇在分析Android中比较常用的缓存类LruCache。