感知器学习算法(PLA)及python实现
1、感知器原理
感知器是最简单的人工神经网络结构之一,由 Frank Rosenblatt 发明于 1957。它是基于一种稍微不同的人工神经元,称为线性阈值单元(LTU):输入和输出现在是数字(而不是二进制开/关值),并且每个输入连接都与权重相连。LTU计算其输入的加权和( z = W1×1 + W2×2 + … + + WN×n = Wt·x ),然后将阶跃函数应用于该和,并输出结果: HW(x) = STEP(Z) = STEP(W^T·x) 。
单一的 LTU 可被用作简单线性二元分类。它计算输入的线性组合,如果结果超过阈值,它输出正类或者输出负类。例如,你可以使用单一的 LTU基于花瓣长度和宽度去分类鸢尾花。训练一个 LTU 意味着去寻找合适的 W0 和 W1 值,。感知器简单地由一层 LTU 组成,每个神经元连接到所有输入。这些连接通常用特殊的被称为输入神经元的传递神经元来表示:它们只输出它们所输入的任何输入。此外,通常添加额外偏置特征( X0=1 )。这种偏置特性通常用一种称为偏置神经元的特殊类型的神经元来表示,它总是输出 1。
引入这样一个例子具体说明一下:某银行要根据用户的年龄、性别、年收入等情况来判断是否给该用户发信用卡。我们把用户的个人信息作为特征向量x,令总共有d个特征,每个特征赋予不同的权重w,表示该特征对输出(是否发信用卡的影响有多大。那所有特征的加权和的值与一个设定的阈值threshold进行比较:大于这个阈值,输出为+1,即发信用卡;小于这个阈值,输出为-1,即不发信用卡。感知器模型,就是当特征加权和与阈值的差大于或等于0,则输出h(x)=1;当特征加权和与阈值的差小于0,则输出h(x)=-1,而我们的目的就是计算出所有权值w和阈值threshold。
2、训练过程
首先随机选择一条直线进行分类。然后找到第一个分类错误的点,如果这个点表示正类,被误分为负类,则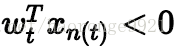
同理,如果是误分为正类的点,即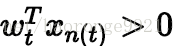
按照这种思想,遇到个错误点就进行修正,不断迭代。要注意一点:每次修正直线,可能使之前分类正确的点变成错误点,这是可能发生的。但是没关系,不断迭代,不断修正,最终会将所有点完全正确分类(PLA前提是线性可分的)。这种做法的思想是“知错能改”。
实际操作中,可以一个点一个点地遍历,发现分类错误的点就进行修正,直到所有点全部分类正确。
3、两个感知器学习算法实例
3.1、这个代码没用包
这个例子是之前我在网上找的,现在忘了在哪个网上找的了,如果侵权请告知删除谢谢!不过(划重点了),在贴出代码之前先说明一下,这个代码的原始程序是错误的(在做预测的时候),就是classify()这个函数(下面贴的是我修改过的正确的)。
下面是代码:
from numpy import *
import matplotlib.pyplot as plt
import operator
import time
def createTrainDataSet(): # 训练样本,第一个1为阈值对应的w,下同
trainData = [[1, 1, 4],
[1, 2, 3],
[1, -2, 3],
[1, -2, 2],
[1, 0, 1],
[1, 1, 2]]
label = [1, 1, 1, -1, -1, -1]
return trainData, label
def createTestDataSet(): # 数据样本
testData = [[1, 1, 1],
[1, 2, 0],
[1, 2, 4],
[1, 1, 3]]
return testData
def sigmoid(X):
X = float(X)
if X > 0:
return 1
elif X < 0:
return -1
else:
return 0
def pla(traindataIn, trainlabelIn):
traindata = mat(traindataIn) # 将列表转换成矩阵http://www.cnblogs.com/itdyb/p/5773404.html
trainlabel = mat(trainlabelIn).transpose() # 矩阵的转置中
m, n = shape(traindata)
w = ones((n, 1)) # ones函数是用于生成一个全1的数组,eye函数用户生成指定行数的单位矩阵,.T作用于矩阵,用作球矩阵的转置
while True:
iscompleted = True
for i in range(m):
if (sigmoid(dot(traindata[i], w)) == trainlabel[
i]): # 同线性代数中矩阵乘法的定义: np.dot(),http://blog.csdn.net/u012609509/article/details/70230204
continue
else:
iscompleted = False
w += (trainlabel[i] * traindata[i]).transpose()
if iscompleted:
break
return w
def classify(inX, w):
result = sigmoid(dot(mat(inX), w))
if result > 0:
return 1
else:
return -1
def plotBestFit(w):
traindata, label = createTrainDataSet()
dataArr = array(traindata)
n = shape(dataArr)[0]
xcord1 = [];
ycord1 = []
xcord2 = [];
ycord2 = []
for i in range(n):
if int(label[i]) == 1:
xcord1.append(
dataArr[i, 1]) # 关于array: line 52,http://www.zmonster.me/2016/03/09/numpy-slicing-and-indexing.html
ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1])
ycord2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111) # 这些是编码为单个整数的子图栅格参数。例如,”111″表示“1×1网格,第一子图”,”234″表示“2×3网格,第4子图”。
# https://gxnotes.com/article/19844.html
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-w[0] - w[1] * x) / w[2]
ax.plot(x, y)
plt.xlabel('X1');
plt.ylabel('X2')
plt.show()
def classifyall(datatest, w):
predict = []
for data in datatest:
result = classify(data, w)
predict.append(result)
return predict
def main():
trainData, label = createTrainDataSet()
testdata = createTestDataSet()
w = pla(trainData, label)
result = classifyall(testdata, w)
plotBestFit(w)
print(w)
print(result)
if __name__ == '__main__':
start = time.clock()
main()
end = time.clock()
print('finish all in %s' % str(end - start))
这里就不贴运行结果,感兴趣的可以试试。
3.1、这个代码用到了sklearn包(传送门)
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2, 3)] # 花瓣长度,宽度
y = (iris.target == 0).astype(np.int)
per_clf = Perceptron(random_state=42)
per_clf.fit(X, y)
y_pred = per_clf.predict([[2, 0.5]])
print(y_pred)这个代码我没试过,如果有误请留言。
4、感知器的一些其它问题
原始感知器学习算法(PLA)只是针对线性可分的数据有效果,如果用线性不可分的数据测试,可能你的程序会停不下来,这就需要pocket了,原理是选出分类错误最少的线,就是每条分类线都要跑完所有数据,逐步选出犯错最少的分类线作为结果,不难发现,这种方法有很大的时间开销,这里不详细说了。