声明:
主要代码和部分算法说明参考自算法(第四版),这里将代码列出,是想和大家交流一些学习心得。
1.前言
先不多说上图,请大家仔细观察下面的图片(有玄机),看完之后我有非常深奥的问题想要问大家。
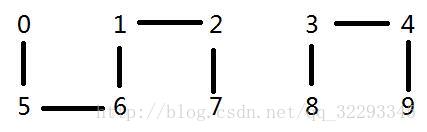
问题1:
数字0和数字1相连吗?
问题2:
数字2和数字3相连吗?
看到这里可能有人要在下面留言喷我,先等等,上面的图片大家一眼就会看出答案,但是那只是因为上面图片只有10个数字,但是如果有上百万,乃至上千万个数字呢?到那时,任意两个数字之间的关系都是错综复杂的,凭借肉眼是无法做出判断的。
那么今天的主角,也就是union-find算法就可以完美解决这个问题。
2.算法用途
2.1网络
可以把这些整数看成网络中的计算机,而有无链接可以判断是否需要在两个计算机之间架设连接。
2.2变量名等价性
当有多个引用指向同一对象时,系统需要能够判断两个给定的变量名是否等价。
2.3数学集合
可以将输入的所有整数看做属于不同的数学集合,在处理一个整数对时,判断他们是否属于相同集合。
2.4人际关系
用于判断两个人是否直接或间接(通过他们的朋友)认识。
3.名词介绍
触点:
上面数字0-9每个数字称作一个触点。
连通分量:
每个相连触点的连接集合称作一个连通分量,上面有两个连通分量一个是0、1、2、6、7,另外一个连通分量是3、4、8、9。
4.实现思路
模拟数据:
用程序读取文件tinyUF.txt,文件中有成对出现的数字,每对数字看做一个连接。
文件:

实现每个连通分量内部的逻辑连接:
在计算机中,我们当然不能像在纸上一样,用笔将各个数字连接起来。所以这里我们采用一种逻辑连接的方式,即给每个触点一个标识符(以下统称为分量值),直接或间接相连的触点间具有相同的分量值,并因为触点和连通标识都是数字,所以我们采用int数组来完成这个操作。
数组的角标为0-9,分别对应着上面各个数字i(触点),然后以此数字为角标的数组中的值为分量值,
例:触点3的标识值=数组[3]
5.算法API

除此之外UF类的有两个成员变量如下:

6.算法实现
6.1实现UF(int N)
目标:
初始化count值;
初始化id[],角标为各个触点0-9,数组中的值(分量值),我们不妨先设为0-9。即开始时触点0所在的连通分量(其实只有它自己)的分量值为0.
代码实现:
//构造方法
public UF(int N){
count = N; //开始时,有N个分量,每个触点都构成了只含它自己的分量
//初始化分量数组
id = new int[N];
for(int i=0;i<N;i++) id[i] = i;
}6.2实现count()
目标:
返回count值
代码实现:
//连通分量的数量
public int count(){
return count;
}6.3实现find(int p)
目标:
用于返回该触点的分量值
代码:
//查找p或q所在分量的标识量
public int find(int p){
return id[p];
}6.4实现connected(int p,int q)
目标:判断p、q是否直接或间接相连
判断依据:根据二者的分量值是否相等
代码:
//判断p和q是否已连接
public boolean connected(int p,int q){
return find(p) == find(q); //依据:判断二者标识量是否相等
}6.5实现union(int p,int q)
目标:
首先判断两个触点是否已经连接,如果没有连接,我们将p所在分量的分量值改为q所在分量的分量值。(当然用p代替q也可以)
代码:
//连接p和(将p和q归并到相同分量中)
public void union(int p,int q){
int pID = id[p]; //找到p的分量值
int qID = id[q]; //找到q的分量值
//二者已经连通,则结束这个方法
if(pID == qID) return;
//前提:当p和q连接时,我们不妨让p的值都改为q的值(当然q改为p的值也可以)
for(int i=0;i<id.length;i++){
//找到所有和p相连的触点,然后把这些触点的分量值都改为q的分量值
//即:将这些触点和p所在分量连接
if(id[i] == pID) id[i] = qID;
}
count--; //每进行一次连接,则分量数减1
}6.6测试代码
//测试
public static void main(String[] args) {
int N = StdIn.readInt(); //读取触点数
UF uf = new UF(N);
while(!StdIn.isEmpty()){
int p = StdIn.readInt(); //读取前一个数
int q = StdIn.readInt(); //读取后一个数
if(uf.connected(p, q)) continue; //如果已经连接,则继续向下读取
uf.union(p, q); //连接p、q
StdOut.println(p + " " + q); //打印刚刚建立的连接
}
StdOut.println(uf.count + " components"); //打印连通分量的数量
}最后输出结果:

7.测试步骤
用debug跟踪程序:
并把上面的文件tinyUF.txt作为main方法的参数输入。
原始数组:0 1 2 3 4 5 6 7 8 9
p:4 q:3
数组:0 1 2 3 3 5 6 7 8 9

p:3 q:8
数组:0 1 2 8 8 5 6 7 8 9

p:6 q:5
数组:0 1 2 8 8 5 5 7 8 9

p:9 q:4
数组:0 1 2 8 8 5 5 7 8 8

p:2 q:1
数组:0 1 1 8 8 5 5 7 8 8

p:8 q:9
数组:0 1 1 8 8 5 5 7 8 8(无变化,因为已经连接)

p:5 q:0
数组:0 1 1 8 8 0 0 7 8 8
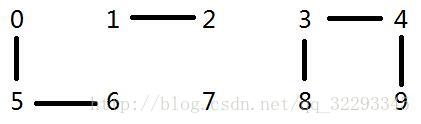
p:7 q:2
数组:0 1 1 8 8 0 0 1 8 8
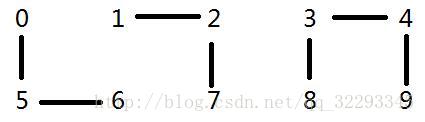
p:6 q:1
数组:1 1 1 8 8 1 1 1 8 8
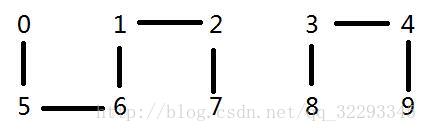
p:1 q:0
数组:1 1 1 8 8 1 1 1 8 8(无变化,因为已经连接)
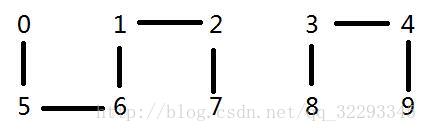
p:6 q:7
数组:1 1 1 8 8 1 1 1 8 8(无变化,因为已经连接)
总之我们可以根据connected(int p,int q)方法判断出两个触点是否连接,但是此算法却有个缺陷,即在每次调用union(int p,int q)方法时,都需要遍历整个数组。所以quick-find只适合处理小规模的数据。所以我们需要优化union方法,具体见中篇:
http://blog.csdn.net/qq_32293345/article/details/78825280
8.完整代码
import edu.princeton.cs.algs4.StdIn;
import edu.princeton.cs.algs4.StdOut;
//p138 union-find算法
public class UF {
private int[] id; //存储分量的数组,以触点作为索引
private int count; //分量数量
//构造方法
public UF(int N){
count = N; //开始时,有N个分量,每个触点都构成了只含它自己的分量
//初始化分量数组
id = new int[N];
for(int i=0;i<N;i++) id[i] = i;
}
//连接p和(将p和q归并到相同分量中)
public void union(int p,int q){
int pID = id[p]; //找到p的分量值
int qID = id[q]; //找到q的分量值
//二者已经连通,则结束这个方法
if(pID == qID) return;
//前提:当p和q连接时,我们不妨让p的值都改为q的值(当然q改为p的值也可以)
for(int i=0;i<id.length;i++){
//找到所有和p相连的触点,然后把这些触点的分量值都改为q的分量值
//即:将这些触点和p所在分量连接
if(id[i] == pID) id[i] = qID;
}
count--; //每进行一次连接,则分量数减1
}
//查找p或q所在分量的标识量
public int find(int p){
return id[p];
}
//判断p和q是否已连接
public boolean connected(int p,int q){
return find(p) == find(q); //依据:判断二者标识量是否相等
}
//连通分量的数量
public int count(){
return count;
}
//测试
public static void main(String[] args) {
int N = StdIn.readInt(); //读取触点数
UF uf = new UF(N);
while(!StdIn.isEmpty()){
int p = StdIn.readInt(); //读取前一个数
int q = StdIn.readInt(); //读取后一个数
if(uf.connected(p, q)) continue; //如果已经连接,则继续向下读取
uf.union(p, q); //连接p、q
StdOut.println(p + " " + q); //打印刚刚建立的连接
}
StdOut.println(uf.count + " components"); //打印连通分量的数量
}
}