贝叶斯决策理论是朴素贝叶斯分类、贝叶斯信念网络、EM算法的基础。
特点:(1)每个观测值都可以提高/降低估计值
(2)先验知识可以和观测数据共同决定最终的假设概率
(3)概率预测,可以提供假设好坏的度量
(4)新实例可以结合多个假设的预测值,依概率加权
1.贝叶斯定理
目的:学习到最优假设,即概率最大可能性最高的假设,这就是我们所说的最大后验假设(MAP)。
那么概率如何计算?可以通过假设的先验概率P(h),已知假设观察数据的概率P(D|h),观察数据本身的概率P(D),则通过观察实验后假设的后验概率P(h|D)可以通过下面式子计算得到。
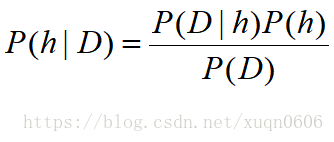
那么得到的最优假设是
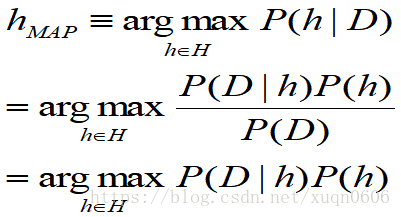
注:(1)后验概率还可以理解为经过数据观测后对假设概率的修正
(2)对比极大似然估计(ML)
例:两个假设:患者得癌症,患者没有得癌症;两个测试结果:阳性,阴性;先验知识如下:

已知一名患者的测试结果为阳性,那么应该如何诊断?
答案
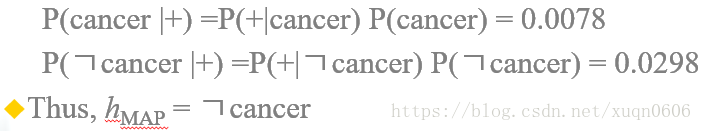
2.最小描述长度准则 Minimum Description Length Principle(也叫奥卡姆剃刀)
给定一组假设与数据集,我们需要努力找到能最大化压缩数据集的假设。这个想法可以应用于所有归纳推理问题,特别在模型选择时,解决过拟合问题。

其中第一项是假设的编码长度,可以理解为模型复杂度;第二项可以理解为给定假设的前提下数据的编码长度,可以理解为误差。因为监督学习其实就是在假设空间中寻找最能代表数据特征的假设,如果假设过于复杂(涉及多个属性的析取或者合取)那么描述假设的编码长度就会很长;如果给定假设能对数据进行有效的压缩,即数据的编码长度小,则说明假设更适合该数据,误差小。总结MDL就是寻找一条或多条误差小且准确的假设。
3.贝叶斯最优分类
如果有多个假设,如何进行分类?还是选择概率最大的类别,但是需要考虑多个假设结果,这样得到的结果更具有可信度。但是还存在一个问题就是假设空间很大的时候,计算代价很高,解决方法——抽样(Gibbs算法)
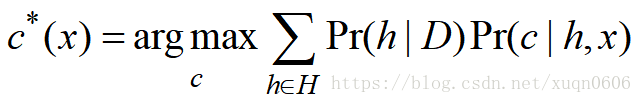
Gibbs算法 ,就是随机地在假设空间中选一个假设h,用h对对新实例进行分类,经人统计发现使用Gibbs采样得到的分类误差小于贝叶斯最优化误差的二倍,但是计算量大大地降低了。除此之外还有一些其他的采样方法,例如Markov chain Monte Carlo(MCMC)采样
4.Bais-Variance权衡
这个是机器学习中重要问题,一般认为Error=Bias+Variance。那么这两个量指的是什么呢?举个课上老师讲的射击的例子,Bias相当于人在瞄准目标的时候就瞄错了,即模型偏差(与真实值相比);Variance相当于实际射击中由于手抖等因素结果偏离瞄准的方向,即模型期望与模型实际的差距(方差),列出式子如下:
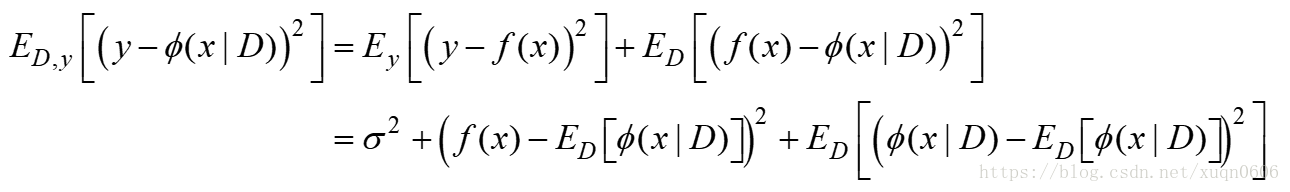
其中y为真实的函数y=f(x),给定的数据集{(x1,y1),(x2,y2)…},y=f(x)+
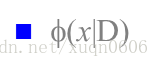
5.朴素贝叶斯分类器Naive Bayes Classify
可以考虑如果一个数据集中实例的属性有n个((a1,a2,a3…an)y)则计算最优的后验概率需要统计每一种可能属性的组合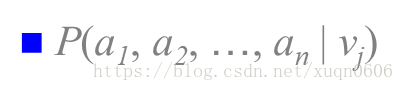


例:

求一条实例{Outlook=sunny,Temperature=cool,Humidity=high,Wind=strong}将其预测为yes还是no?
答案:
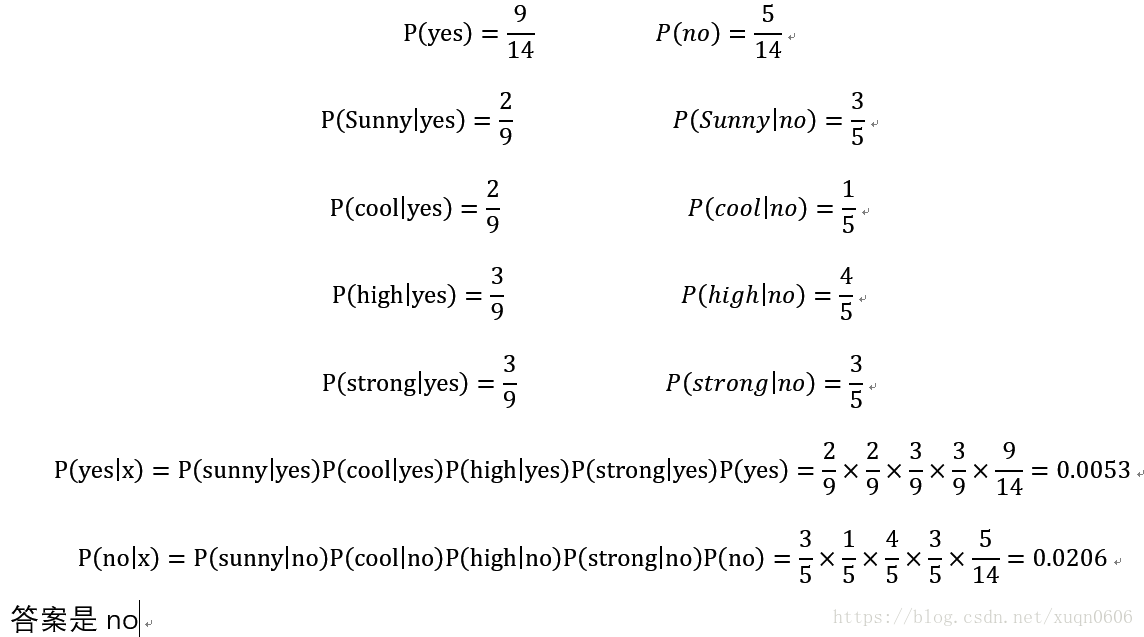
但是NB有一个很大的问题,就是其中独立性条件不容易满足,并非所有的属性均独立,可能存在部分独立,朴素贝叶斯使用范围小,因此引入表达能力更强的贝叶斯信念网络
6.贝叶斯信念网络
贝叶斯信念网络是有向无环图,结点代表属性变量(包括可测或者隐含未知的属性),边代表条件独立,另外每个结点还有一个概率表。如下图所示

该网络中三大条件独立
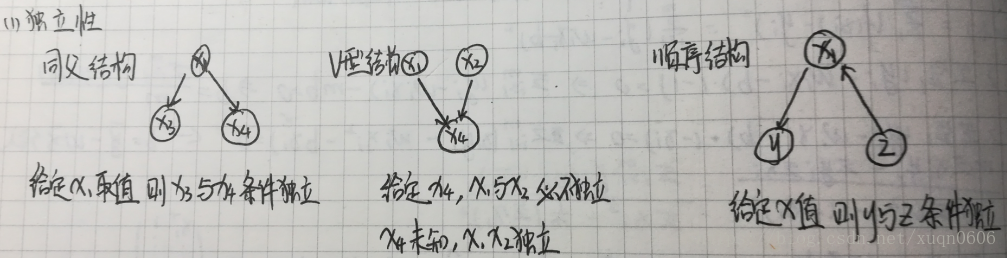
6.1.构建贝叶斯信念网络

例
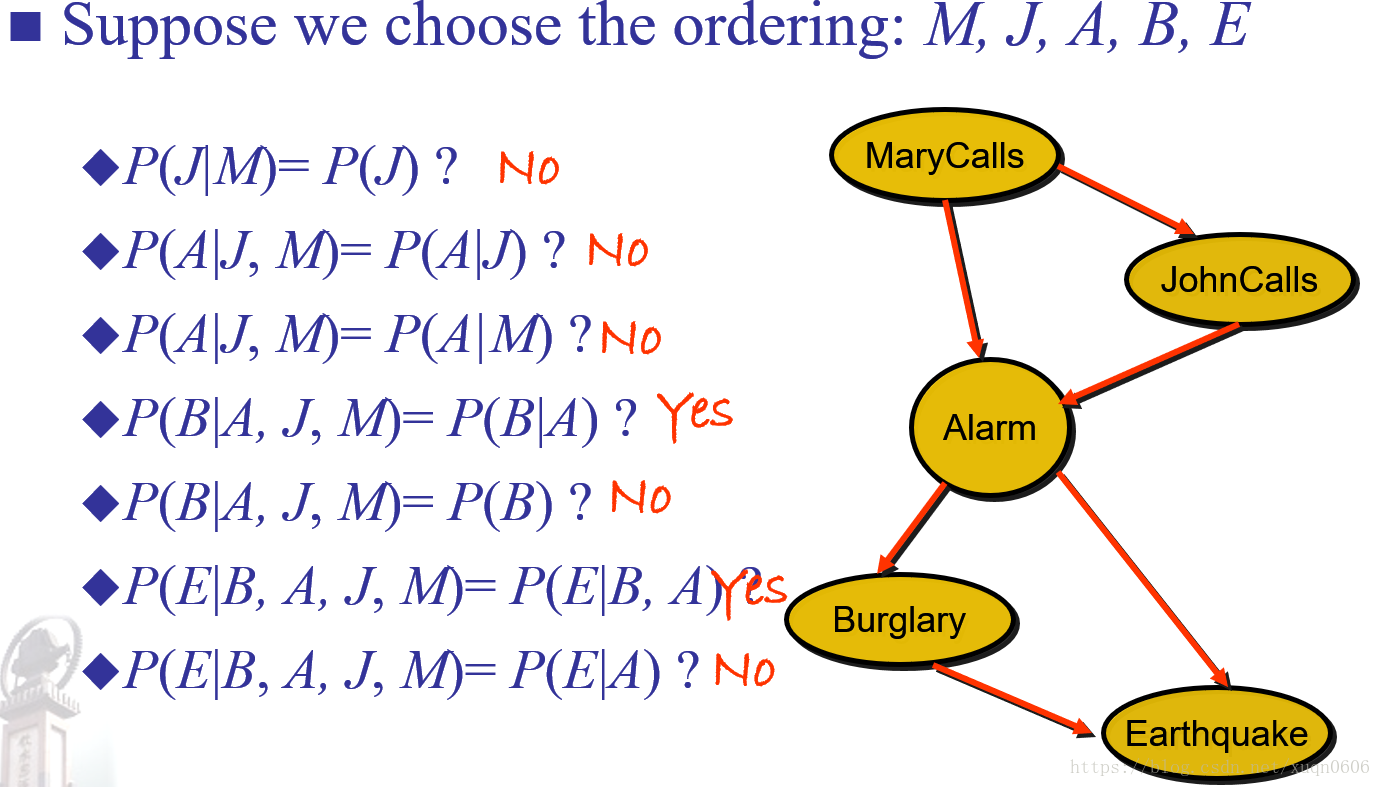
该例题的解释是,若P(J|M)=P(J)不成立,则J与M不独立,因此存在一条从M指向J的有向线;第四行P(B|A,J,M)=P(B|A)成立,那么说明B与J、M独立,因此不存在从M/J指向B的有向线。