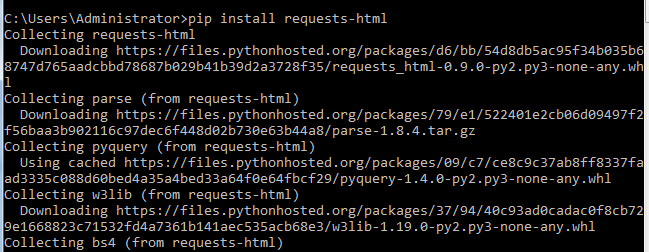
1.安装,在命令行输入:pip install requests-html,安装成功后,在Pycharm引入即可。
2.代码如下所示:
from requests_html import HTMLSession
import requests
session = HTMLSession()
r = session.get('http://www.win4000.com/wallpaper_2358_0_10_1.html')
images = r.html.find('ul.clearfix > li > a') #获取到网页上所有a标签url
def save_Image(url,title): #定义一个函数,用于保存图片到指定目录下(E盘下需手动新建bg文件夹)
html_response = requests.get(url)
with open('E:/bg/'+title+'.jpg','wb') as file:
file.write(html_response.content)
#查找页面中背景图,找到链接,访问查看大图,并获取大图地址
for image in images:
image_url = image.attrs['href'] #获取到每张图片属性值为href的url
if '/wallpaper_detail' in image_url:
r = session.get(image_url)
item_url = r.html.find('img.pic-large',first=True) #获取到href下的src的url
url = item_url.attrs['src']
title = item_url.attrs['title']
print(url+title)
save_Image(url,title)
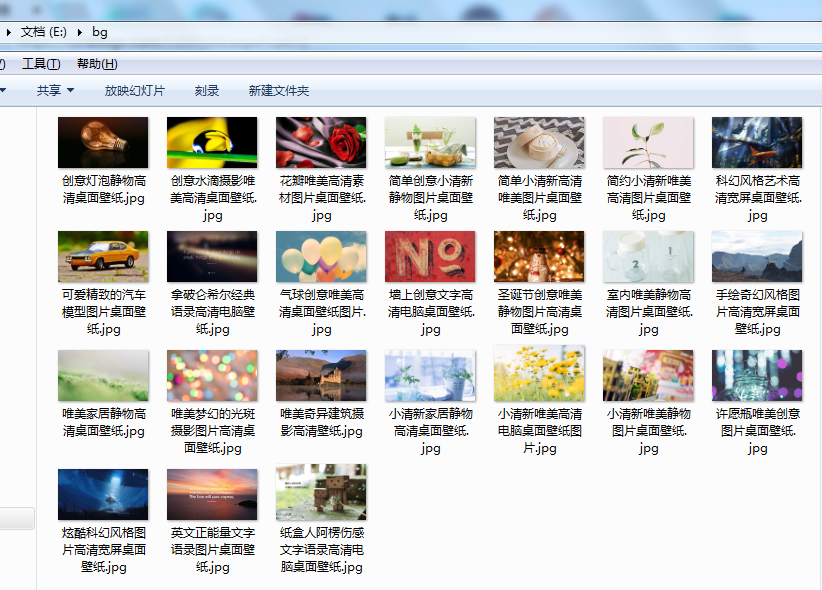
3.在指定目录即可查看到爬下来的图片