Requests-HTML是在Requests的基础上进一步封装,两者都是由同一个开发者开发。Requests-HTML除了包含Requests的所有功能外,还新增了数据清洗和Ajax数据动态渲染。
数据清洗时是由lxml和PyQuery提供的。
数据清洗
from requests_html import HTMLSession
session = HTMLSession()
url = "https://movie.douban.com/"
r = session.get(url)
print(r.html) #输出网页的url
print(len(r.html.links)) # 网页里的全部的url
print(len(r.html.absolute_links)) # 输出网页里精准的url地址
print(r.text) #输出网页的html信息
print(r.html.text) # 输出网页的全部文本信息 去除html代码
精确定位
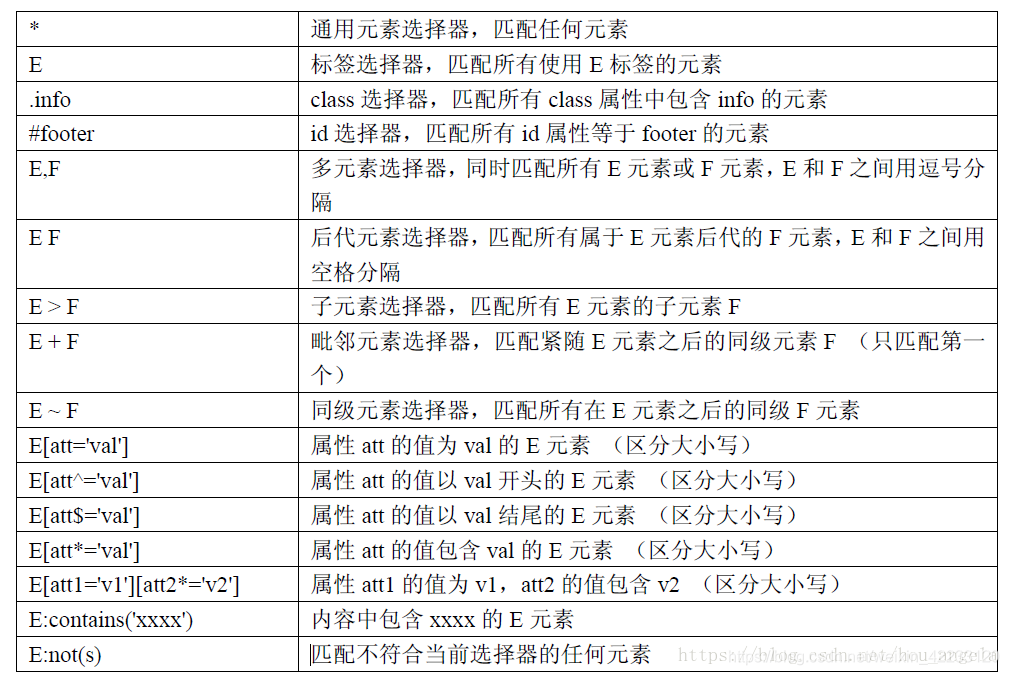
通过CSS Selector定位:
<li class="title">
<a class="" href="https://movie.douban.com/subject/32659890 /?from=showing" onclick="moreurl(this, {from:'mv_a_tl'})">我和我的祖国...</a>
</li>
from requests_html import HTMLSession
# 定义会话
session = HTMLSession()
url = "https://movie.douban.com/"
# 发送get请求
r = session.get(url)
#通过CSS Selector定位li标签
print(r.html.find("li.title>a",first=True).html)
print(r.html.find("li.title",first=True).html)
print(r.html.find("li.title",first=True).text)
print(r.html.find("li.title",first=True).attrs)
输出所示
我和我的祖国...
{'class': ('title',)}
查找特定文本的元素:
寻找名字里面含有“我”的电影:
e = r.html.find("li.title",containing="我")
for item in e:
print(item.text)
送我上青云
我和我的祖国...
通过Xpath定位:
输出所有电影的名字
x = r.html.xpath('//*[@id="screening"]/div[2]/ul')
for name in x:
a = name.find("li.title")#screening > div.screening-bd > ul > li:nth-child(1) > ul > li.title
for item in a :
print(item.text)
###########################
# 稍微改动一下,效果完全不变,只是体会一下“>"的用法
a = name.find("li>ul>li.title")
