环境
python:3.7.4
python库:requests-html
IDE:pycharm2019.3版本
爬取网址: https://weibo.cn/pub/
教程
本次教程爬取的网页是微博移动端的界面,打开网页会显示如下图所示

其中除了两个明星每次加载会不一样以外,其他网页的内容是固定的,也就是说利用xpath只能提取网页的其他内容,但是不能提取显示的明星相关的内容
下面附上完整代码,但先不要复制运行,里面会有一个问题,请先把后面的内容看完
from requests_html import HTMLSession
def wei_bo():
session = HTMLSession() # 创建一个会话
url = 'https://weibo.cn/pub/' # 请求的网址
# 浏览器请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Connection': 'close'
}
r = session.get(url=url, headers=headers) # get请求
r.html.render() # 重点关注
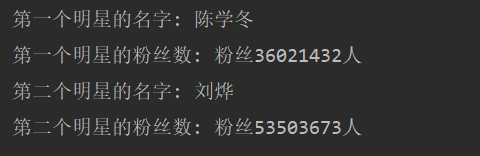
first_one_name = r.html.xpath('/html/body/table[1]/tbody/tr/td[2]/a[1]/text()')[0]
print('第一个明星的名字:', first_one_name)
first_one_fans = r.html.xpath('/html/body/table[1]/tbody/tr/td[2]/text()')[0]
print('第一个明星的粉丝数:', first_one_fans)
second_one_name = r.html.xpath('/html/body/table[2]/tbody/tr/td[2]/a[1]/text()')[0]
print('第二个明星的名字:', second_one_name)
second_one_fans = r.html.xpath('/html/body/table[2]/tbody/tr/td[2]/text()')[0]
print('第二个明星的粉丝数:', second_one_fans)
wei_bo() # 函数调用运行的结果
但是如果把 r.html.render()该行代码注释掉,运行结果会出现下列异常

原因是因为xpath不能提取到相关信息,返回的列表为空,所以[0]提取列表信息会出现异常,所以对于动态网页要先调用render函数去把完整的网页显示出来,render函数有很多功能,详细的教程可以参考下面的网站
https://www.cnblogs.com/pythonywy/p/11694967.html
最后讲解一下首次调用render函数会先下载chromium,国内的网速下载会很慢,所以上面提示先不要运行代码,为了应对这个问题我们采用手动安装chromium的方式,方法如下:
参考教程: https://www.cnblogs.com/xiaoaiyiwan/p/10776493.html
1.找到python的安装目录,注意默认安装到C盘是隐藏目录,需要设置显示
我的目录是 C:\Users\admin\AppData\Local\Programs\Python\Python37\Lib\site-packages\pyppeteer
2.找到 chromium_downloader.py文件 打开
在以下代码处修改
DOWNLOADS_FOLDER = Path(__pyppeteer_home__) / 'local-chromium'
DEFAULT_DOWNLOAD_HOST = 'https://storage.googleapis.com'
DOWNLOAD_HOST = os.environ.get(
'PYPPETEER_DOWNLOAD_HOST', DEFAULT_DOWNLOAD_HOST)
BASE_URL = f'{DOWNLOAD_HOST}/chromium-browser-snapshots'
REVISION = os.environ.get(
'PYPPETEER_CHROMIUM_REVISION', __chromium_revision__)
# 添加两个输出
print(DOWNLOADS_FOLDER)
print(REVISION)我的输出结果是
C:\Users\admin\AppData\Local\pyppeteer\pyppeteer\local-chromium
575458第一行表示安装的目录,第二行表示需要下载的chromium版本
chromium压缩包下载地址: https://npm.taobao.org/mirrors/chromium-browser-snapshots/Win_x64/575458/
可以把py文件的输出删掉复原了
下载完压缩文件解压的目录是
C:\Users\admin\AppData\Local\Programs\Python\Python37\Lib\site-packages\pyppeteer\575458
注: 575458这个目录本身不存在 需要自己创建
chrome.exe最后在目录 C:\Users\admin\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458\chrome-win32下
至此就可以正常的使用render功能了
