Python上有一个非常著名的HTTP库——requests
现在requests库的作者又发布了一个新库,叫做requests-html,看名字也能猜出来,这是一个解析HTML的库 (只支持python3.6及以上)
https://cncert.github.io/requests-html-doc-cn/#/?id=user_agent

安装很简单,直接pip install requests-html
完成之后可以查看一下。
基本使用
获取网页
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.baidu.com')
print(r.html.html)
获取链接
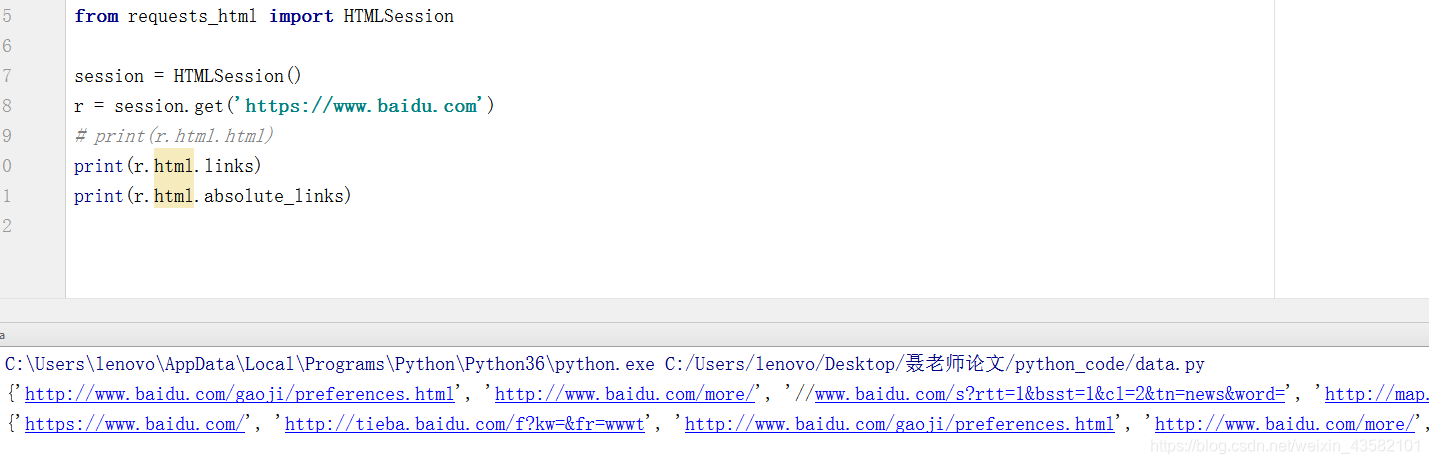
html.html 获取html页面
html.links、 absolute_links 获取html中所有的链接、绝对链接
我们做个测试。以糗事百科为例。
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.qiushibaike.com/text/')
获取元素
request-html支持CSS选择器和XPATH两种语法来选取HTML元素。
首先先来看看CSS选择器语法,它需要使用HTML的find函数,该函数有5个参数,作用如下:
- selector,要用的CSS选择器;
- clean,布尔值,如果为真会忽略HTML中style和script标签造成的影响(原文是sanitize,大概这么理解);
- containing,如果设置该属性,会返回包含该属性文本的标签;
- first,布尔值,如果为真会返回第一个元素,否则会返回满足条件的元素列表;
- _encoding,编码格式。
下面是几个简单例子:
print(r.html.find('div#menu', first=True).text)
# 首页菜单元素
print(r.html.find('div#menu a'))
# 段子内容
print(list(map(lambda x: x.text, r.html.find('div.content span'))))
结果如下:

然后是XPATH语法,这需要另一个函数xpath的支持,它有4个参数如下:

- selector,要用的XPATH选择器;
- clean,布尔值,如果为真会忽略HTML中style和script标签造成的影响(原文是sanitize,大概这么理解);
- first,布尔值,如果为真会返回第一个元素,否则会返回满足条件的元素列表;
- _encoding,编码格式。
跟上面差不多:
print(r.html.xpath("//div[@id='menu']", first=True).text)
print(r.html.xpath("//div[@id='menu']/a"))
print(r.html.xpath("//div[@class='content']/span/text()"))

元素内容
糗事百科首页LOGO的HTML代码如下所示:
<div class="logo" id="hd_logo">
<a href="/"><h1>糗事百科</h1></a>
</div>
我们来选取这个元素,然后用text输出:
e = r.html.find("div#hd_logo", first=True)
print(e.text)

要获取元素的attribute,用attr属性:
print(e.attrs)
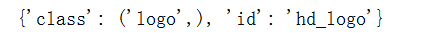
要获取元素的html,用html属性:
print(e.html)

进阶用法
JavaScript支持(重点之一!)
有些网站是使用JavaScript渲染的,这样的网站爬取到的结果只有一堆JS代码,这样的网站requests-html也可以处理,关键一步就是在HTML结果上调用一下render函数,它会在用户目录(默认是 ~/.pyppeteer/)中下载一个chromium,然后用它来执行JS代码。下载过程只在第一次执行,以后就可以直接使用chromium来执行了

such as:(给定script)
直接使用HTML,直接渲染JS代码
前面介绍的都是通过网络请求HTML内容,其实requests-html当然可以直接使用,只需要直接构造HTML对象即可:
from requests_html import HTML
doc = """<a href='https://httpbin.org'>"""
html = HTML(html=doc)
print(html.links)

直接渲染JS代码也可以:
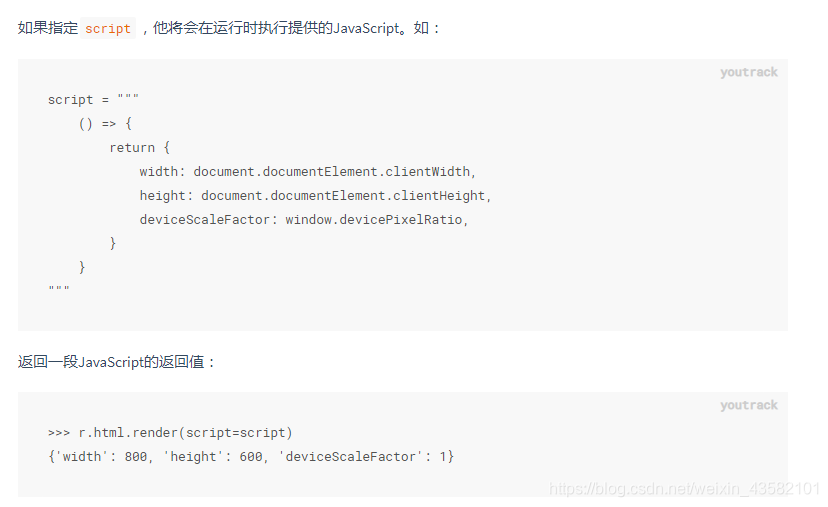
script =
"""
() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}
"""
val = html.render(script=script, reload=False)
print(val)
自定义请求
前面都是简单的用GET方法获取请求,如果需要登录等比较复杂的过程,就不能用get方法了。HTMLSession类包含了丰富的方法,可以帮助我们完成需求。下面介绍一下这些方法。
自定义用户代理
有些网站会使用UA来识别客户端类型,有时候需要伪造UA来实现某些操作。如果查看文档的话会发现 HTMLSession上的很多请求方法都有一个额外的参数 **kwargs,这个参数用来向底层的请求传递额外参数。我们先向网站发送一个请求,看看返回的网站信息。
import json
from pprint import pprint
r = session.get('http://httpbin.org/get')
pprint(json.loads(r.html.html))
print()和pprint()都是python的打印模块,功能基本一样,唯一的区别就是pprint()模块打印出来的数据结构更加完整,每行为一个数据结构,更加方便阅读打印输出结果。特别是对于特别长的数据打印,print()输出结果都在一行,不方便查看,而pprint()采用分行打印输出,所以对于数据结构比较复杂、数据长度较长的数据,适合采用pprint()打印方式。当然,一般情况多数采用print()。
可以看到UA是requests-html自带的UA,下面换一个UA:
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0'
r = session.get('http://httpbin.org/get', headers={'user-agent': ua})
pprint(json.loads(r.html.html))

可以看到UA确实发生了变化
模拟表单登录
HTMLSession带了一整套的HTTP方法,包括get、post、delete等,对应HTTP中各个方法。比如下面我们就来模拟一下表单登录:
r = session.post('http://httpbin.org/post', data={'username': 'yitian', 'passwd': 123456})
pprint(json.loads(r.html.html))
结果如下,可以看到forms中确实收到了提交的表单值:
{'args': {},
'data': '',
'files': {},
'form': {'passwd': '123456', 'username': 'yitian'},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'close',
'Content-Length': '29',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'httpbin.org',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) '
'AppleWebKit/603.3.8 (KHTML, like Gecko) '
'Version/10.1.2 Safari/603.3.8'},
'json': None,
'origin': '110.18.237.233',
'url': 'http://httpbin.org/post'}
如果有上传文件的需要,做法也是类似的。如果了解过requests库的同学可能对这里的做法比较熟悉,没有错,这其实就是requests的用法。requests-html通过暴露 **kwargs的方法,让我们可以对请求进行定制,将额外参数直接传递给底层的requests方法。所以如果有什么疑问的话,直接去看requests文档就好了。
爬虫例子
文章写完了感觉有点空洞,所以补充了几个小例子。不得不说requests-html用起来还是挺爽的,一些小爬虫例子用scrapy感觉有点大材小用,用requests和BeautifulSoup又感觉有点啰嗦,requests-html的出现正好弥补了这个空白。大家学习一下这个库,好处还是很多的。
爬取简书用户文章
简书用户页面的文章列表就是一个典型的异步加载例子,用requests-html的话可以轻松搞定,如下所示,仅仅5行代码。
r = session.get('https://www.jianshu.com/u/7753478e1554')
r.html.render(scrolldown=50, sleep=.2)
titles = r.html.find('a.title')
for i, title in enumerate(titles):
print(f'{i+1} [{title.text}](https://www.jianshu.com{title.attrs["href"]})')
当然这个例子还有所不足,就是通用性稍差,因为文章列表没有分页机制,需要一直往下拉页面,考虑到不同的用户文章数不同,需要先获取用户总文章数,然后在计算一下应该下滑页面多少次,这样才能取得较好的效果。
