Hadoop-序列化
序列化:
对象的序列化用于将一个对象编码成字节流,以及从字节流中重新构建对象。
将一个对象编码成一个字节流称为序列化该对象。
序列化三种主要的用途:
1.作为一种持久化格式。
2.作为一种通信的数据格式。
3.作为一种拷贝、克隆机制。
Hadoop序列化机制:
Hadoop序列化机制是调用的write方法将对象序列化到流中,调用readFiles方法进行反序列化。
java序列化机制与Hadoop序列化机制区别:
java:反序列化过程中不断的创建新对象。
Hadoop:反序列化的工程中,可以服用对象,也就是说在同一个对象上得到多个反序列化的结果。
减少了java对象的分配和回收,提高了应用的效率。
Hadoop序列化机制的特征
1.紧凑:Hadoop中最稀缺的资源是宽带,所以紧凑的序列化机制可以充分的利用宽带。
2.快速:通信时大量使用序列化机制,因此,需要减少序列化和反序列化的开销。
3.可扩展:随着通信协议的升级而可升级。
4.互操作:支持不同开发语言的通信。
Hadoop Writable机制
Hadoop通过Writable接口实现的序列化机制。
接口提供连个方法,write和readFiles。
Hadoop还包含另外几个重要的序列化接口,WritableCompareable、RawComparator、WritableComparator。
Writable接口大家可能都知道,它是一个实现了序列化协议的序列化对象。在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。
下面是Hadoop实现的序列化类型:
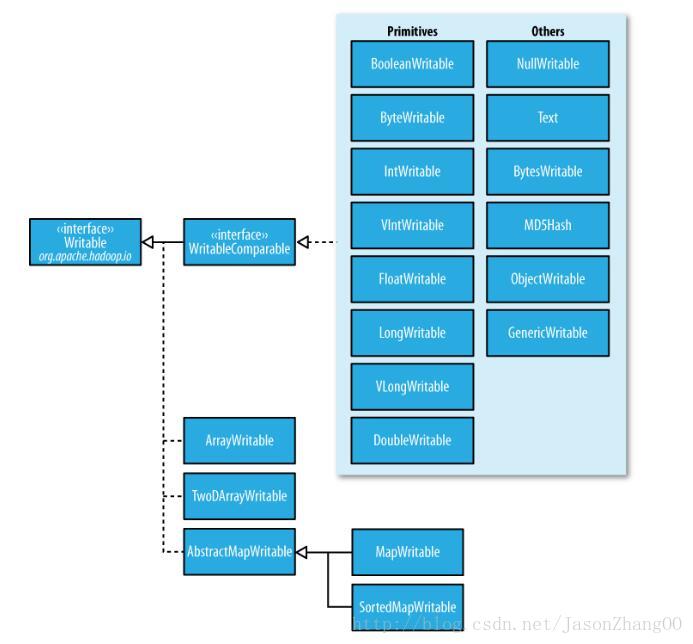
WritableComparable 和comparators
WritableComparable接口是Writable和java.lang.Comparable接口的子接口。
源码:
package org.apache.hadoop.io;
public interface WritableComparable extends Writable, Comparable {
}
WritableComparable接口是可序列化并且可比较的接口。MapReduce中所有的key值类型都必须实现这个接口,需要实现readFiels()和write()这两个反序列化和序列化函数,可比较通过实现compareTo()函数,该函数是比较和排序规则的实现。
下面剖析一下rawComparator:

类型的比较对MapReduce而言至关重要的,键和键之间的比较是在排序阶段完成。Hadoop提供的一个优化方法是从
Java Comparator的RawComparator扩展,IntWritable和LongWritable都含有相应的comparator内部类:
package org.apache.hadoop.io;
import java.util.Comparator;
public interface RawComparator extends Comparator {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
这个接口允许执行者比较从流中读取的未被反序列化为对象的记录,从而省去了创建对象的所有开销。例如,IntWritables的comparator使用原始的compare()方法从每个字节数组的指定开始位置(S1和S2)和长度(L1和L2)读取整数b1和b2然后直接进行比较。
WritableComparator是RawComparator对WritableComparable类的一个通用实现。它提供两个主要功能。首先,它提供了一个默认的对原始compare()函数的调用,对从数据流对要比较的对象进行反序列化,然后调用对象的compare()方法。其次,它充当的是RawComparator实例的一个工厂方法(Writable方法已经注册)。例如,为获得IntWritable的comparator,我们只需使用:
RawComparator comparator = WritableComparator.get(IntWritable.class);
comparator可以用来比较两个IntWritable:
IntWritable w1 = new IntWritable(163);
IntWritable w2 = new IntWritable(67);
assertThat(comparator.compare(w1, w2), greaterThan(0));
或者它们的序列化描述:
byte[] b1 = serialize(w1);
byte[] b2 = serialize(w2);
assertThat(comparator.compare(b1, 0, b1.length, b2, 0, b2.length), greaterThan(0));
IntWritable代码中的static块调用WritableComparator的static方法define()用来注册上面这个Comparator,就是将其加入WritableComparator的comparators成员中,comparators是HashMap类型且是static的。这样,就告诉WritableComparator,当我使用WritableComparator.get(IntWritable.class)方法的时候,你返回我注册的这个Comparator给我[对IntWritable来说就是IntWritable.Comparator],然后我就可以使用comparator.compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)来比较b1和b2,而不需要将它们反序列化成对象[像下面代码中]。comparator.compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)中的readInt()是从WritableComparator继承来的,它将IntWritable的value从byte数组中通过移位转换出来。
//params byte[] b1, byte[] b2
RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);
comparator.compare(b1,0,b1.length,b2,0,b2.length);
注意,当comparators中没有注册要比较的类的Comparator,则会返回一个默认的Comparator,然后使用这个默认Comparator的compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)方法比较b1、b2的时候还是要序列化成对象的。
参考:《Hadoop权威指南》
http://www.cnblogs.com/lucius/p/3449944.html