版权声明:本文为博主原创文章,如需转载请注明出处。因博主水平有限,如有疏忽遗漏,敬请指出。 https://blog.csdn.net/ShadowN1ght/article/details/77746314
在传统人工神经网络ANN的训练过程中,每次迭代的目的就是不断地调整权值w1,w2,w3,...,wn,使训练样本经过神经网络的实际输出值与目标输出尽可能地接近。
实际输出和目标输出之间的误差度量通常采用如下平方误差准则:
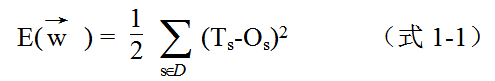
(注:word的向量表达式占多了一个空格的空间,如对排版不满,请多多包涵)
其中,D是训练样本集合(dataset),s是训练样本,T s是s的目标输出(即s的类别),O s是s经过神经网络的实际输出。常数因子是为了与推导过程中产生的因子1/2抵消。现在我们探讨如何使训练误差E最小化。
观察式1-1,对于特定问题,训练集合D是固定的,即Ts是固定的,而Os只依赖于权值向量w,故训练误差E是权值向量w的函数。
在网络训练过程中,为得到使训练误差E最小化的权值向量w,从任意的权向量w 0开始,以很小步长反复修改这个权向量,每一步修改都使误差E减小,直到找到使E合理最小化的权向量w *。假设输入点数目为n,则可以将最小化误差E的操作,视为等同于在(n+1)维空间(w0~wn构成n维,E构成最后一维)中找到使误差超抛物面E在第n+1轴上值最小的点。那么,训练过程就相当于寻找误差超抛物面E的最低点或可以接受的合理低值点(因超抛物面可能有多个极小值点)。
为使误差E减小的速度尽可能快,一个合理的选择就是找到超抛物面当前最陡峭的方向。而曲面下降最快的方向,也就是方向导数——梯度最大的方向。
误差超抛物面的梯度是一个向量,可表示为:
梯度向量中的每一个值是E对w(向量,符号打不出来)中每个权值的偏导数。
由于梯度是上升最快的方向,而我们寻找的是下降最快的方向,故对于权值的更新规则:
其中η是一个正的常数,称为学习速率,决定了下降步长。是w(向量,符号打不出来)当前的权值向量,▽w(向量,符号打不出来)代表向当前下降最快方向下降的一小段位移。
权值的更新规则可以表示成权值分量的形式:

在上式中,对于既定的训练样本S∈D,Ts、Os和xis在一次迭代里面的值都是固定的,而η则是人为预先设定的常数值,按照该式计算权值更新是非常方便的,也是非常便于编程实现的。由于难度较低,具体的实现代码在此就不予给出了。