
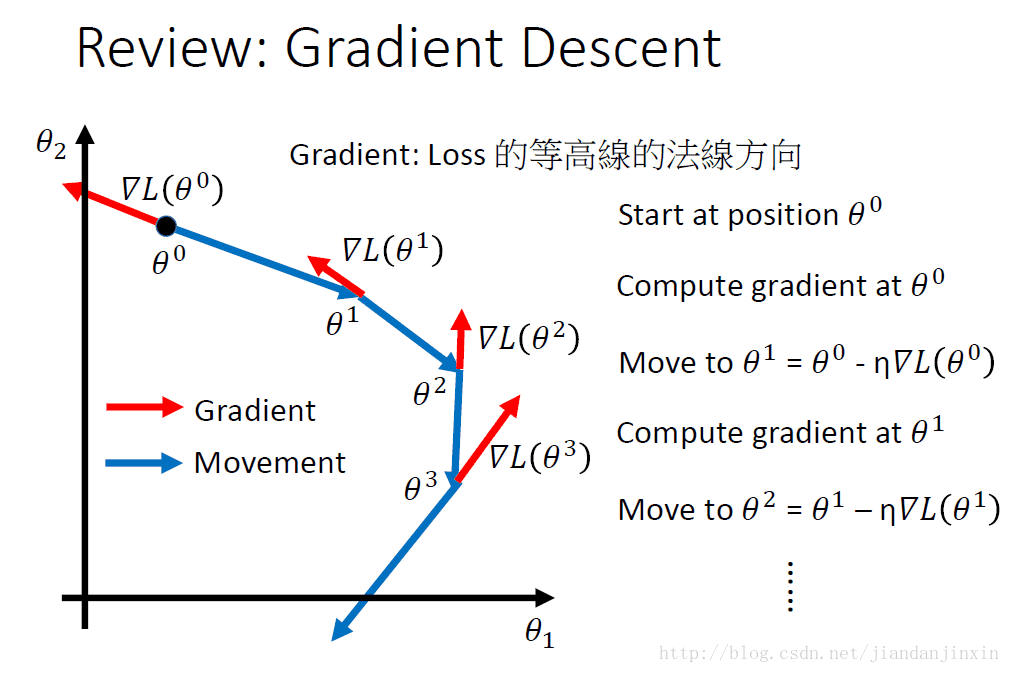
梯度下降法是为了找到最优的目标函数,寻找的过程就是沿着损失函数下降的方向来确定参数变化的方向。参数更新的过程就是一个不断迭代的过程,每次更新参数学到的函数都会使得误差损失越来越小,也就是说学习到的参数函数越来越逼近最优函数。
参数的更新是按照损失函数的等高线的方向进行的。
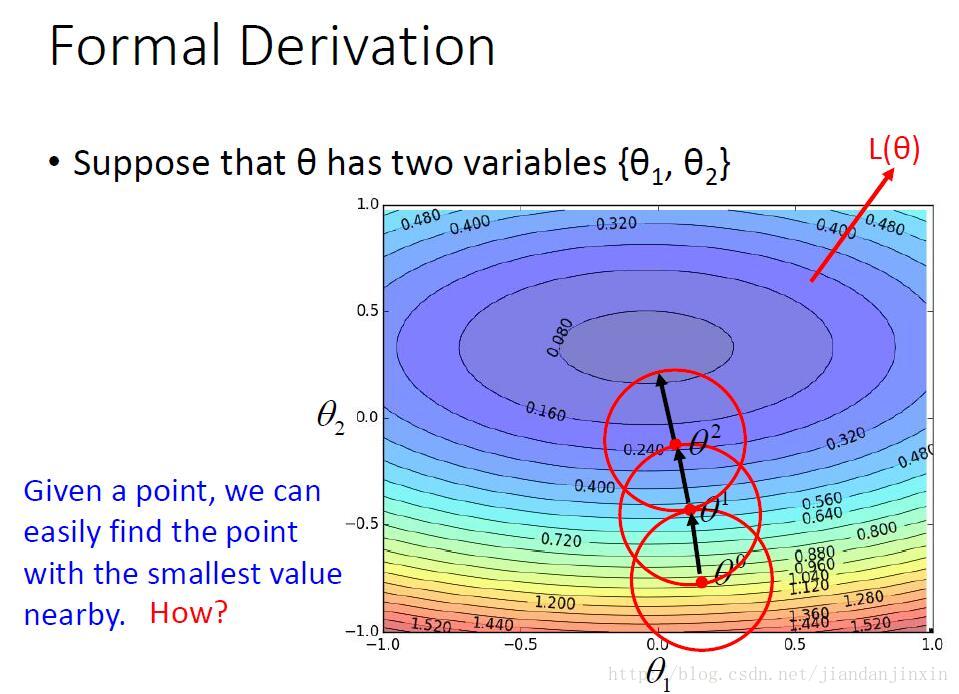
梯度下降是一阶导数,梯度下降是用平面来逼近局部。
牛顿法是二阶导数,牛顿法是用曲面逼近局部。
梯度下降法调整学习速率
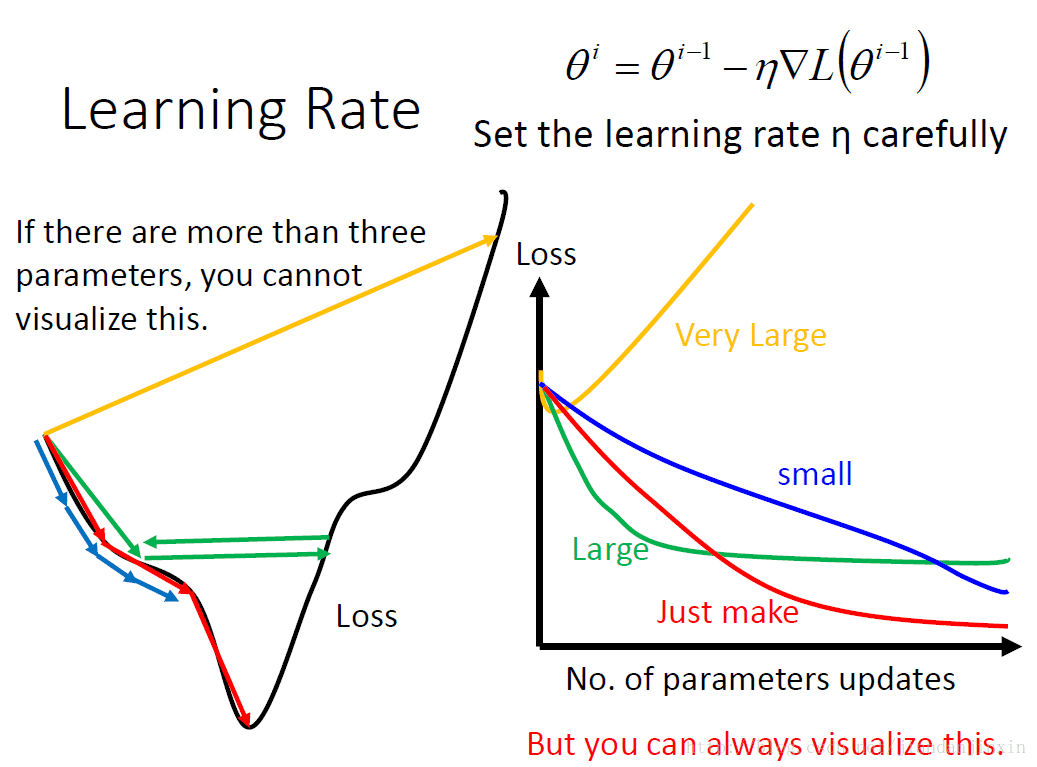
可视化:参数更新的变化与损失的变化情况。蓝色线表示的是学习率太小,导致损失下降太慢。绿色线表示的是学习速率变大,损失很快就变小,但是后面有卡住了,损失不在变化。黄色线表示的是学习速率太大,直接导致损失爆炸。红色的线是理想的学习速率。

一般情况,在刚开始的时候,可以设置比较大的学习速率,这样可以快速接近最优的函数。经过几epochs后,我们会接近最优的函数,这时可以降低学习速率,来确定最终的参数。
不同的参数不同的学习速率。
梯度下降法Adagrad调整学习速率
调节学习率方法一,Adagrad


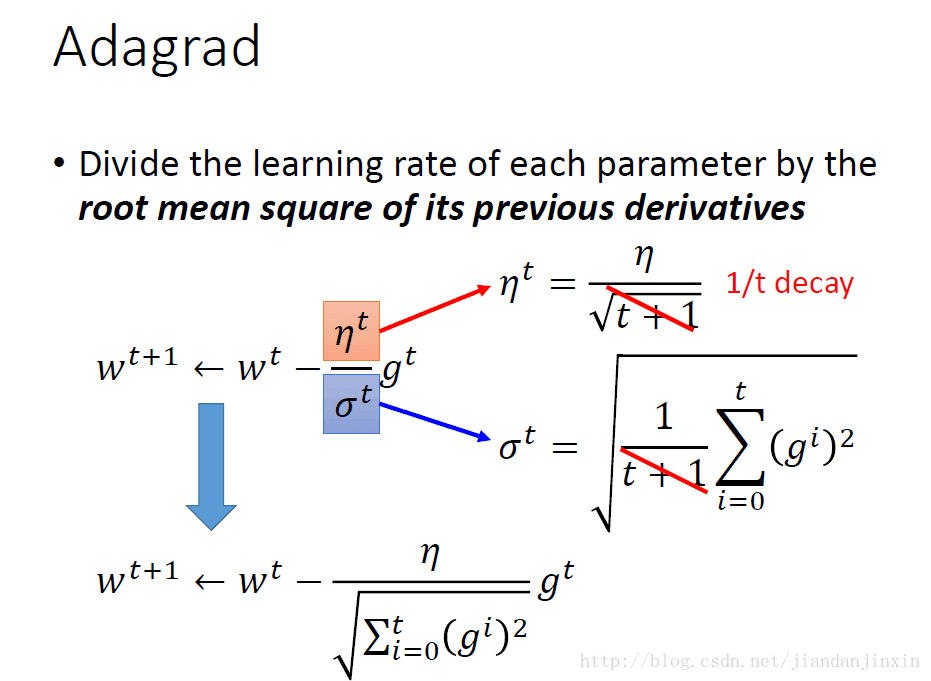
Adagrade的具体实现过程,学习率的变化与之前微分平方和的均方根有关。Adagrad 可以给不同参数给予不同的学习速率Learning Rate.根据计算公式可以看出,学习速率与前面所有梯度都有关系,是一个梯度平方和的均方根。
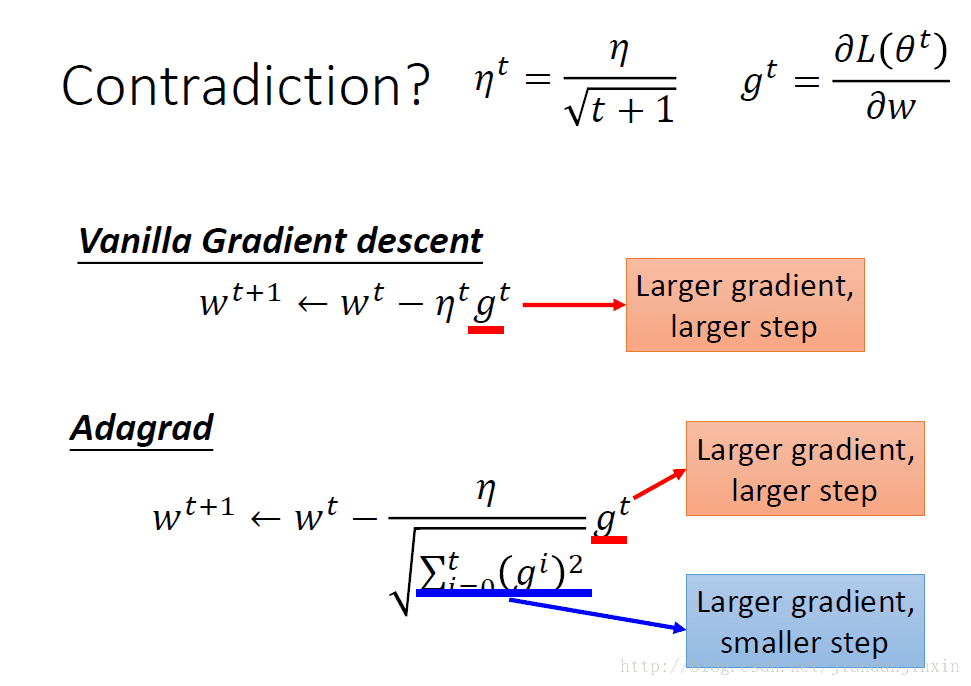
Adagrade矛盾的地方是分子是较大的梯度会有较大的step,而分母是较大的梯度反而会有较小的step。这个合理的解释是每次梯度变化的反差。(现在的梯度与过去梯度之间的反差,见下图)
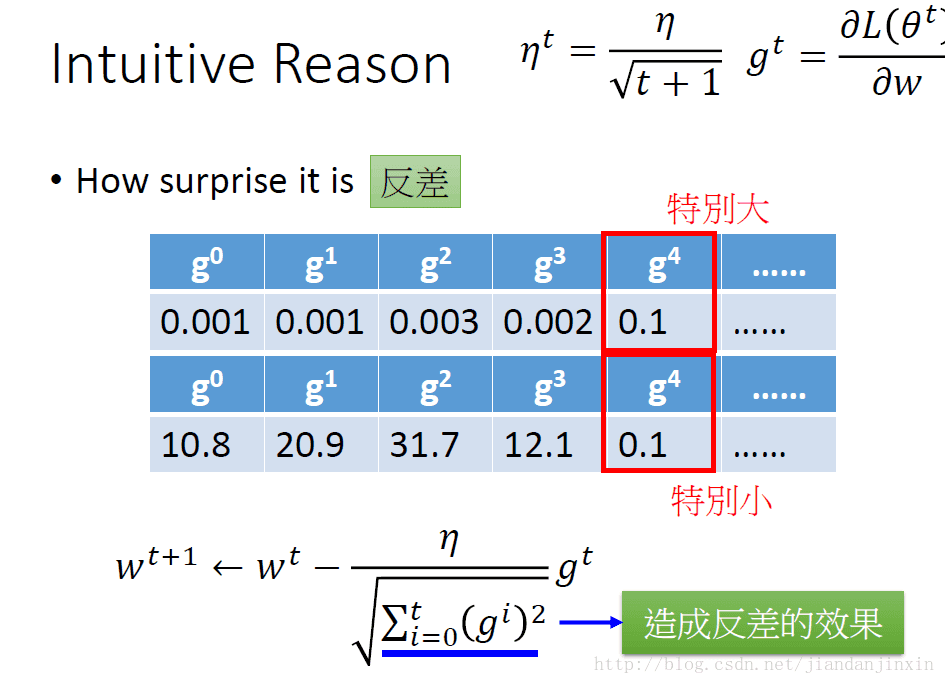
Adagrade的第二种合理解释
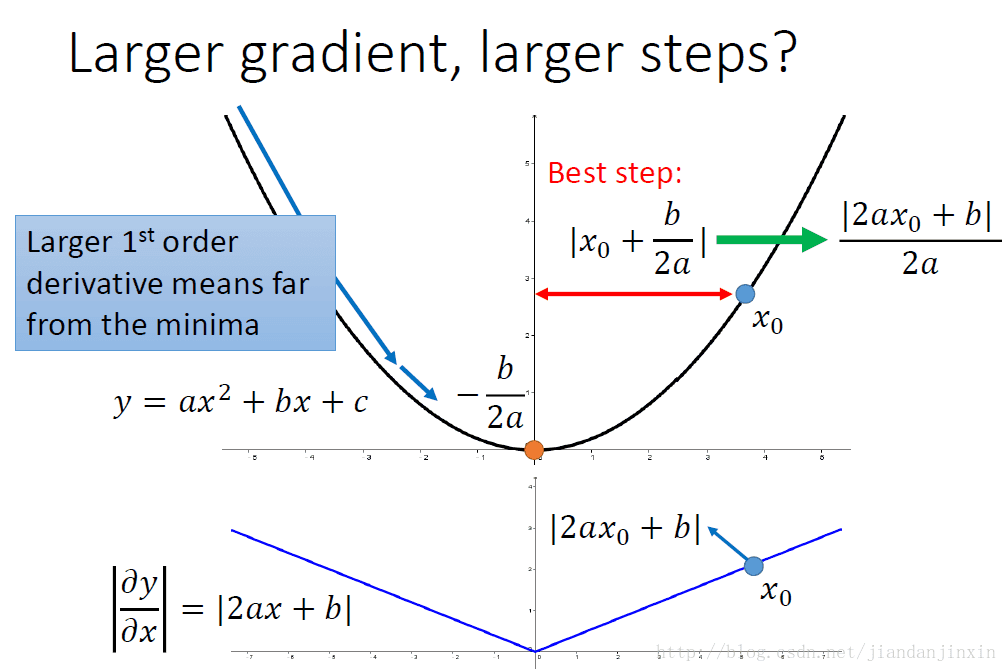
一个参数的一阶微分,比较合理的步伐应该是与梯度成正比的。因为这样的步伐才能快速的接近最优点位置,如图中的极值点。初始点x0与极值点的距离为|2ax0+b|/|2a|,所以最佳的步伐就是|2ax0+b|/|2a|,这个步伐与在x0的一阶微分值(|2ax+b|)成正比。
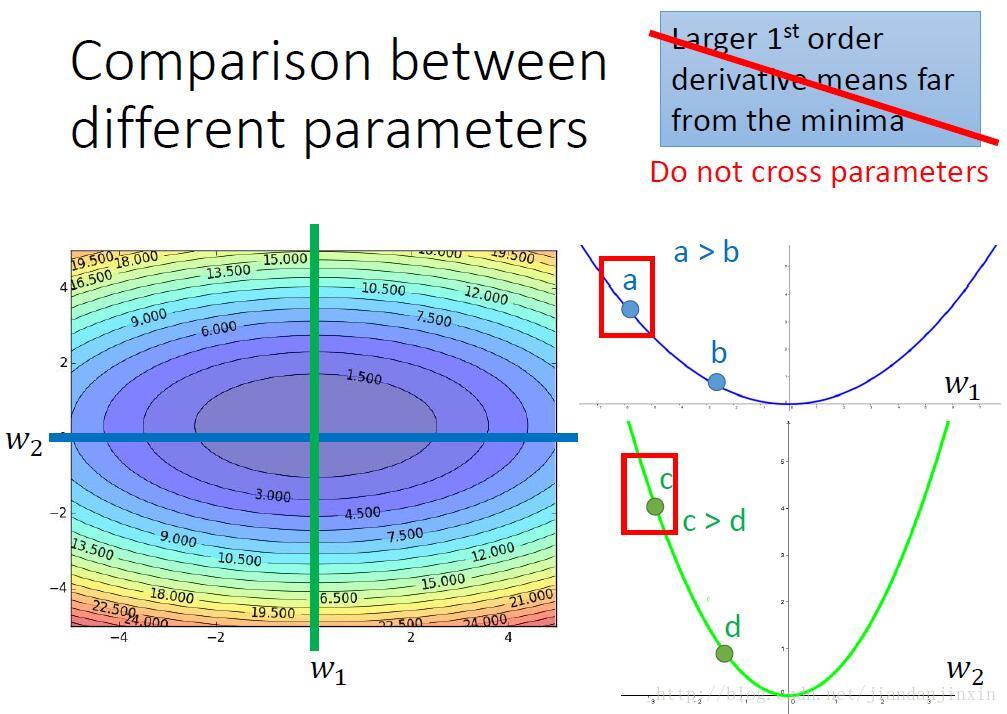
多个参数的一阶微分。从图中可以看出,对于参数w1来说,a点的微分值大于b点的微分值,所以a点的步伐选择应该大于b点的步伐选择。同样参数w2,也是c点的微分值大于d点的微分值,所以c点的步伐值的选择应该比d点的步伐值要大。
但是我们比较a点和c点的步伐值的选择。综合比较发现c点的微分值大于a点的微分值,但实际上是a点离最优点的位置比c点离最优点的位置要大。
所以对于多参数的情况,仅仅根据微分值的大小来确定最终的学习速率(步伐)是不合理的。
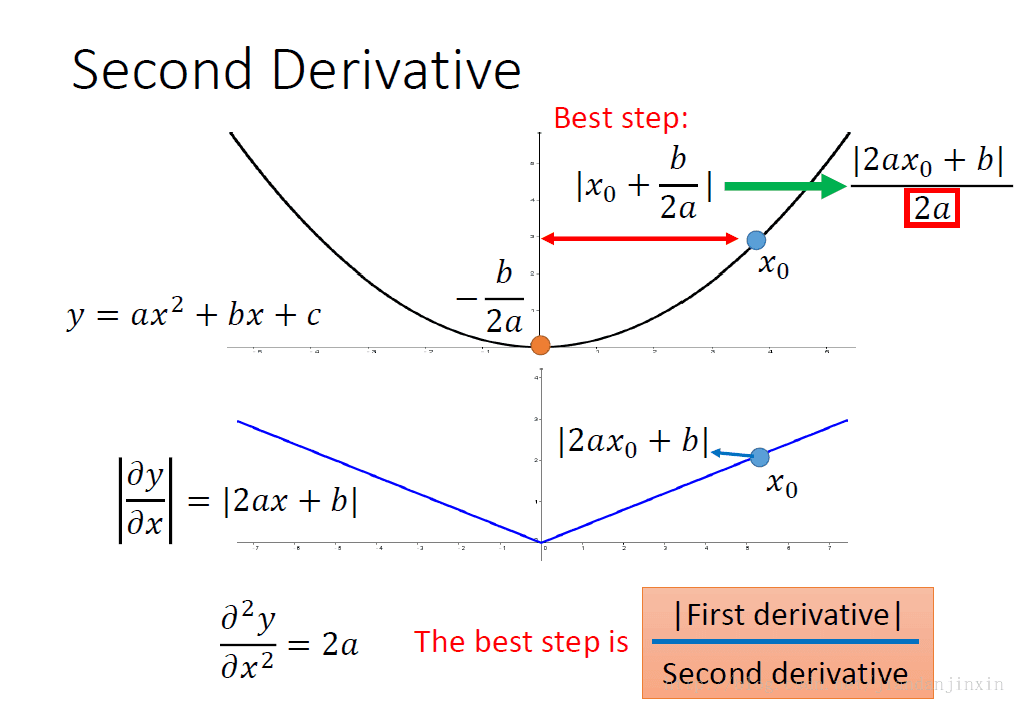
对于一个参数的一阶微分,我们发现最优步伐是|2ax0+b|/|2a|,分母实际上二阶微分,所以最优的步伐选择应该是 |First derivative|/|Second derivative|
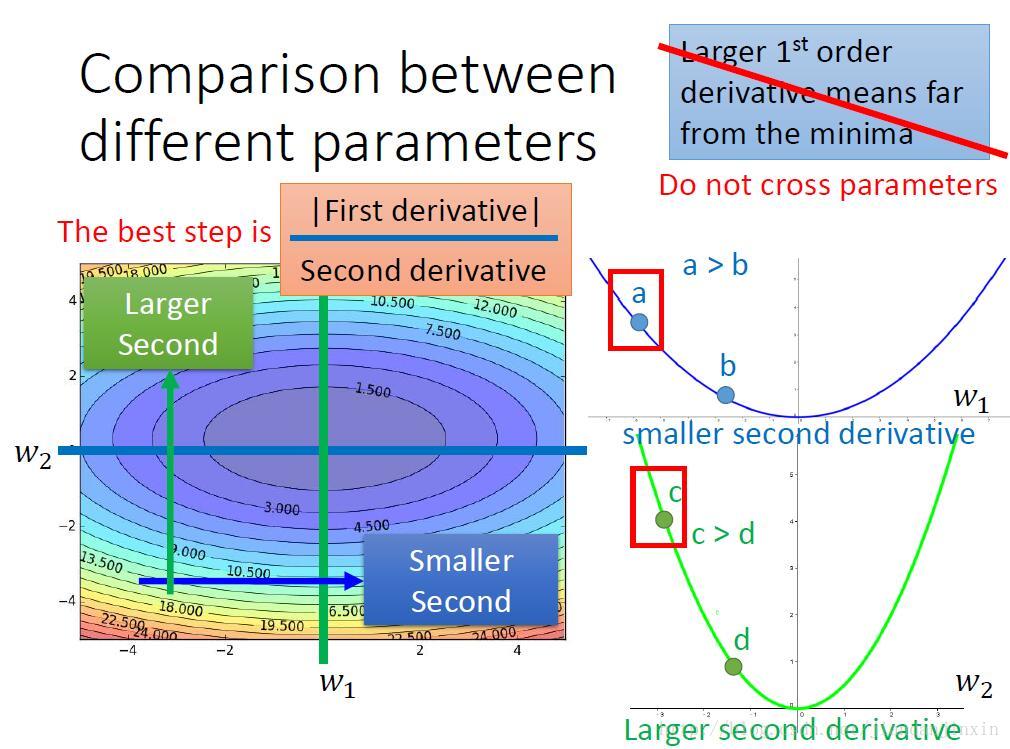
同样对于多个参数的情况,也需要考虑二阶微分,最优的步伐选择应该是 |First derivative|/|Second derivative|。a点的一阶微分较小,a点的二阶微分也较小。c点一阶微分较大,二阶微分也较大。
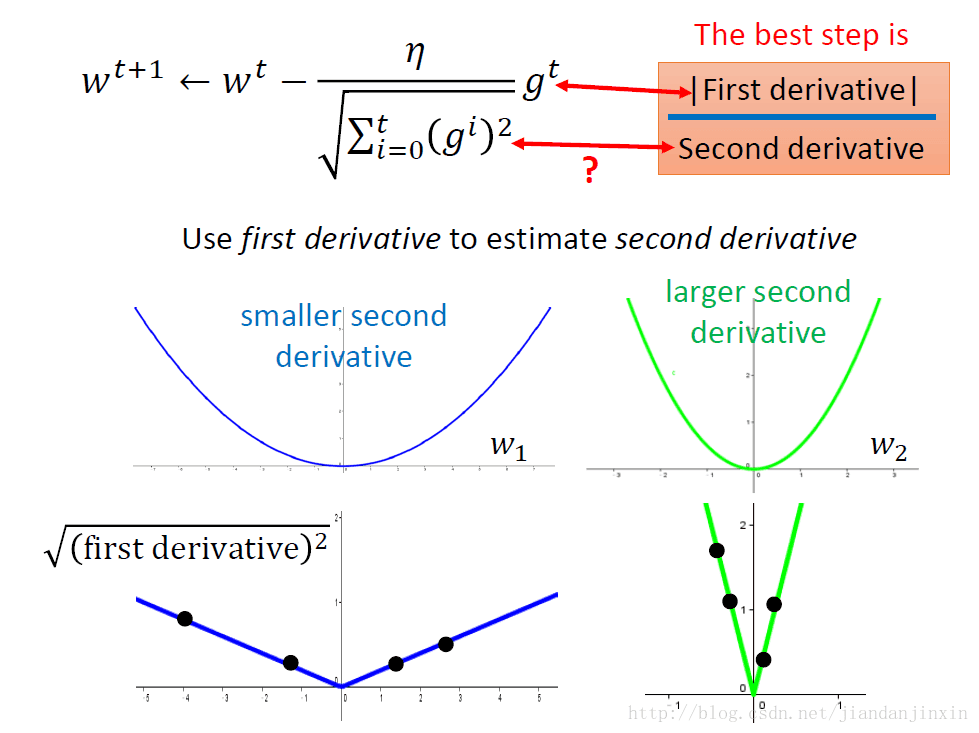
Adagrade可以类比于这种形式|First derivative|/|Second derivative|。那为什么Adagrade不直接算二阶微分,而分母使用的是一次微分呢?这是因为算二次微分会增加计算量,效果不一定比Adagrade现在的效果好。Adagrad在没有增加计算量的情形下,直接使用一阶微分的均方和根,有时候效果比|First derivative|/|Second derivative|不差。
调节学习率方法二,RMSProp。
RMSProp也可以给予不同参数给予不同的学习速率 Learning Rate,即不同参数方向有不同的学习速率。 此外,针对同一方向,可以动态调整学习速率,比如说,在某个区域较为平坦,则需要较小的Learning Rate, 在另外一个区域突然很陡峭,则需要大的学习速率。
根据计算公式可以看出,学习速率与前面所有梯度都有关系,只是给出了新的梯度和旧的梯度给予不同的权重,当相信新的梯度时,给予新的梯度更大的权重,当相信旧的梯度给予旧的梯度更大的权重。
解决局部极值,鞍点的问题,Momentum
惯性的计算可以发现惯性与之前所有的梯度是有关的。通俗的理解为对梯度的平均,使得纵向的摆动变小了,横向的运动更快了。可加快梯度下降。
Adam: RMSProp 和 Momentum的结合体。
RMSProp + Momentum
梯度下降法Stochastic Gradient Descent调整学习速率

随机梯度下降法每次只考虑一个样本,可以重复取一个样本,也可以按次序取一个样本。而梯度下降法考虑的是整体所有的样本。
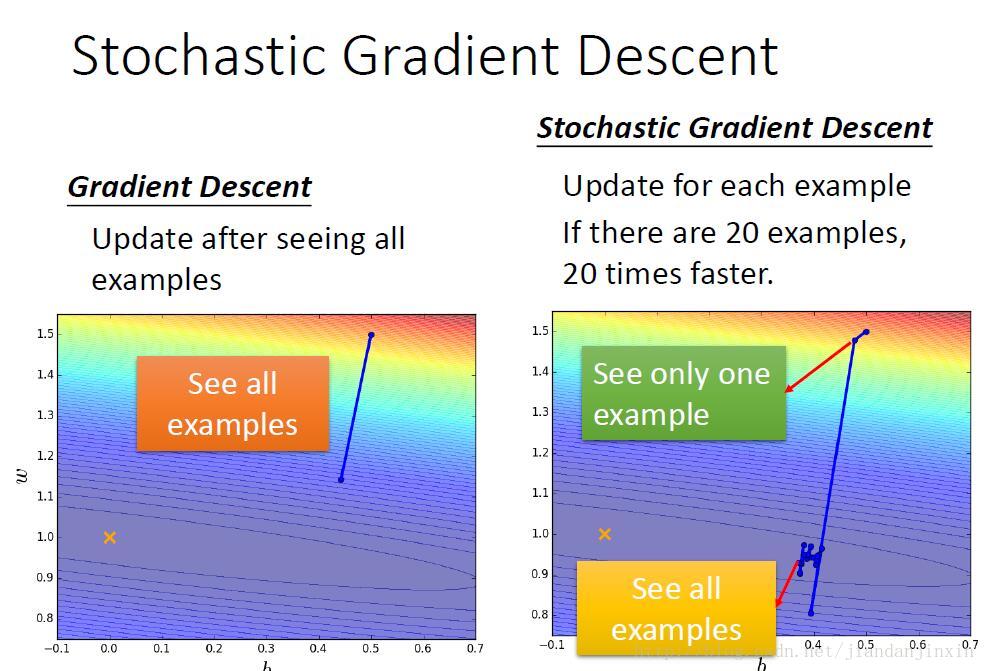
随机梯度下降法的学习速率更新了20次(每次只看一个样本),而梯度下降法的速率只更新了一次(每次看所有的20个样本)。所以随机梯度下降法的速率更新速度比较快。
Feature Scaling
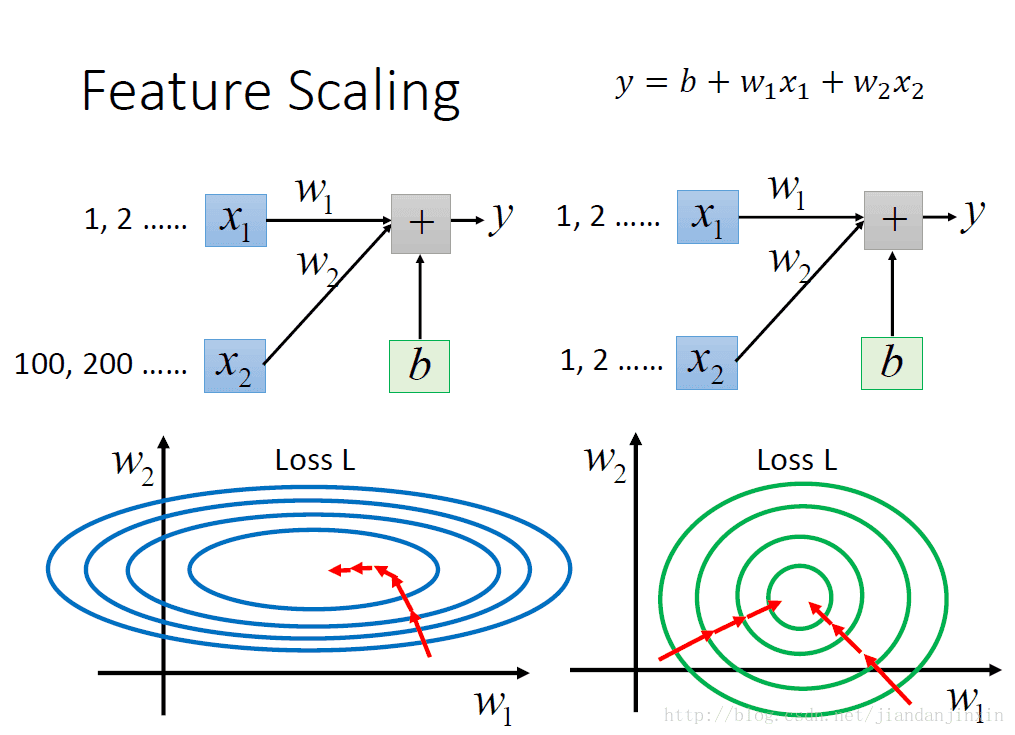
不同尺度的特征值,会导致每种特征对损失函数的影响不同。通常情况下,较大尺度的特征对损失函数的影响较大,而那些尺度较小的其他特征对损失函数的影响较小。这就会使得那些尺度较小的特征失去意义。
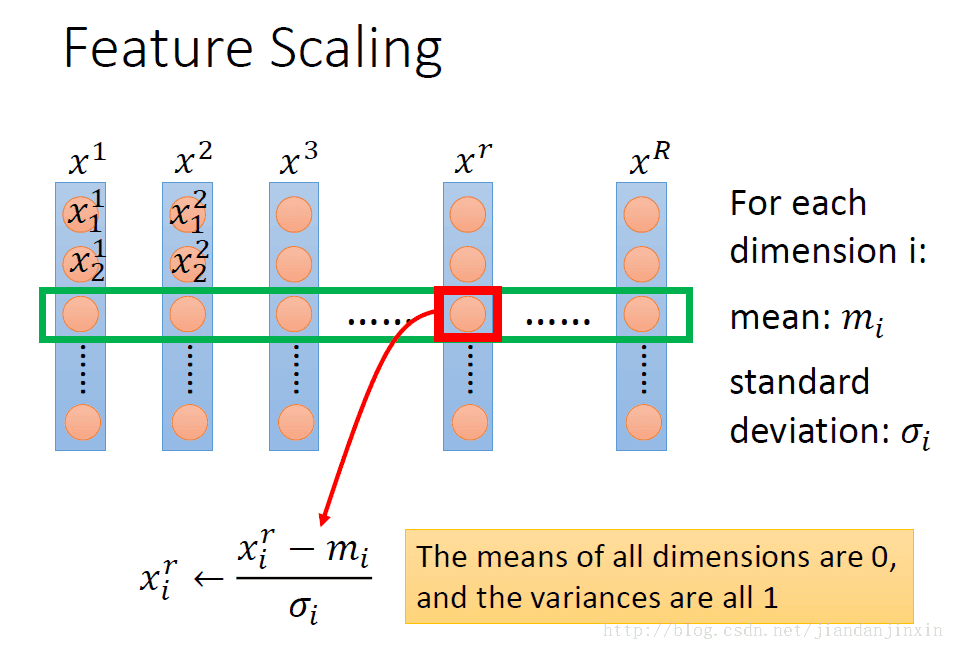
特征尺度归一化的原理,最终导致每种特征都是0均值,方差为1的特征。
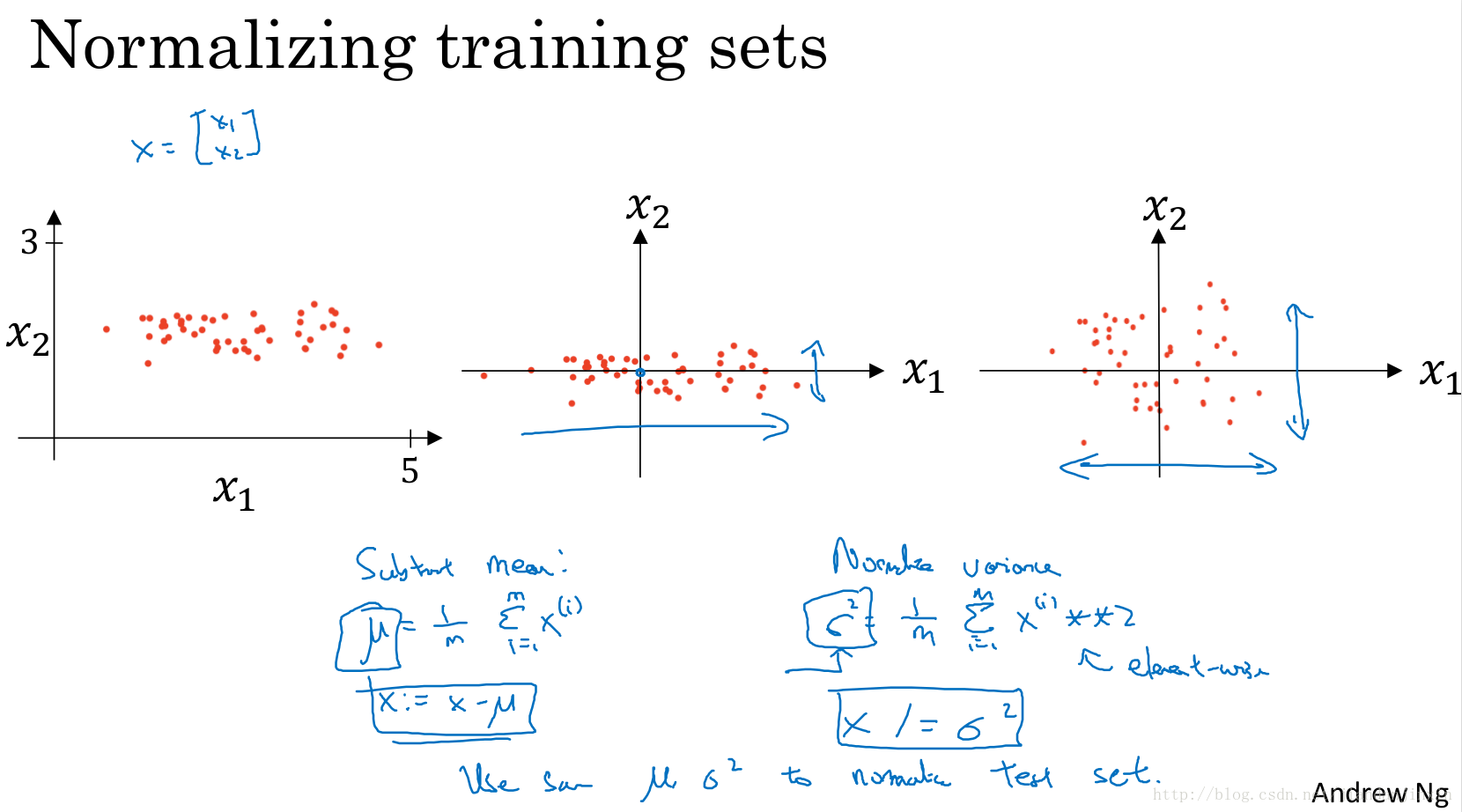
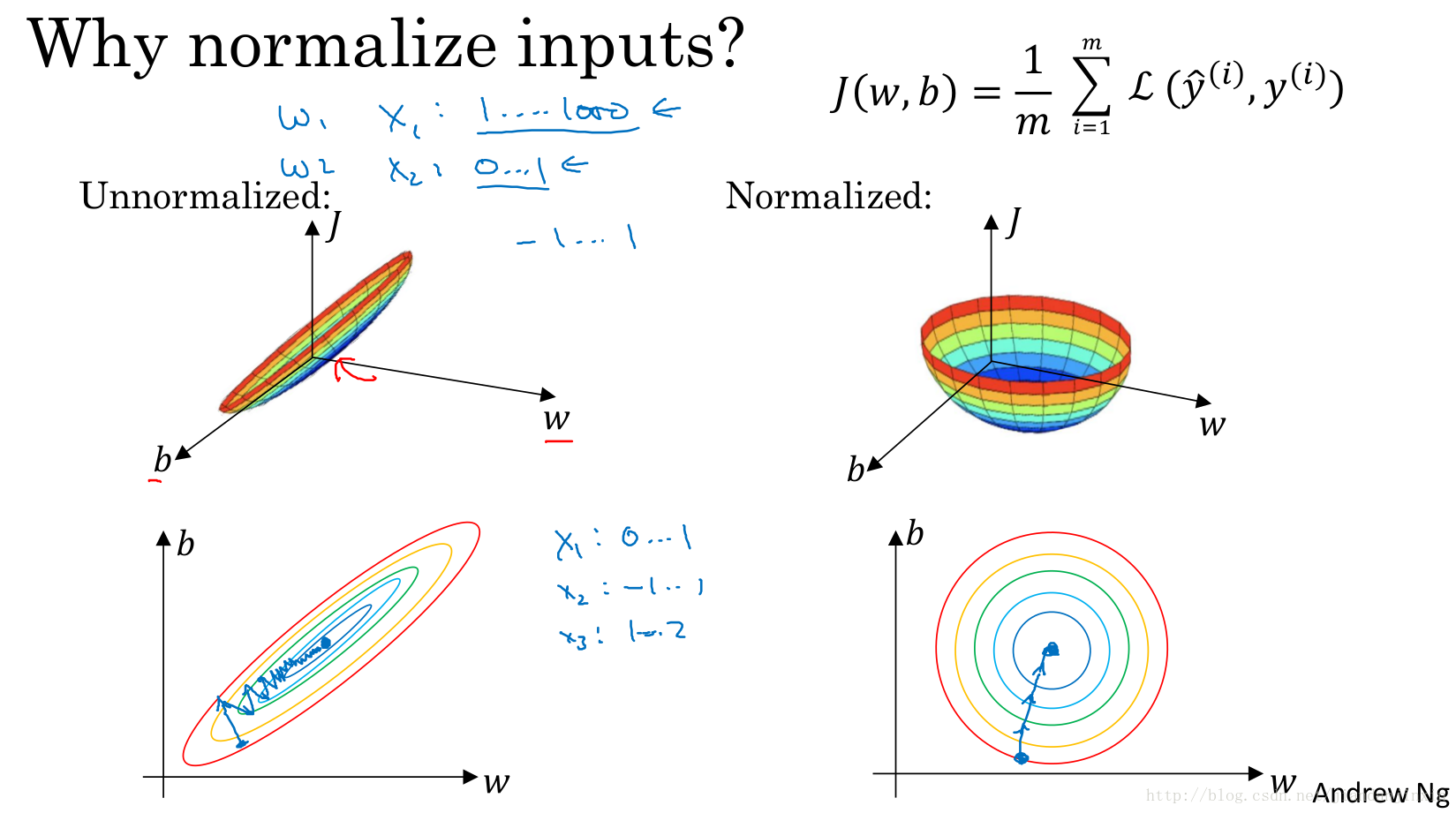
正则化输入,可加速训练。二维示例图非常有参考价值,可总结借鉴该图。为何归一化,可加速训练,见可参看图。
不做归一化,则需要选择较小的学习速率,较小的步长。而归一化后的数据,则可选择较大的步长,这样学习速率就比较快了。
Gradient Descent Theory

当x接近x0时,泰勒展开可以缩简为如上形式,后面的高阶可以忽略不计。

同理,多参数泰勒展开也可以有类似缩简。
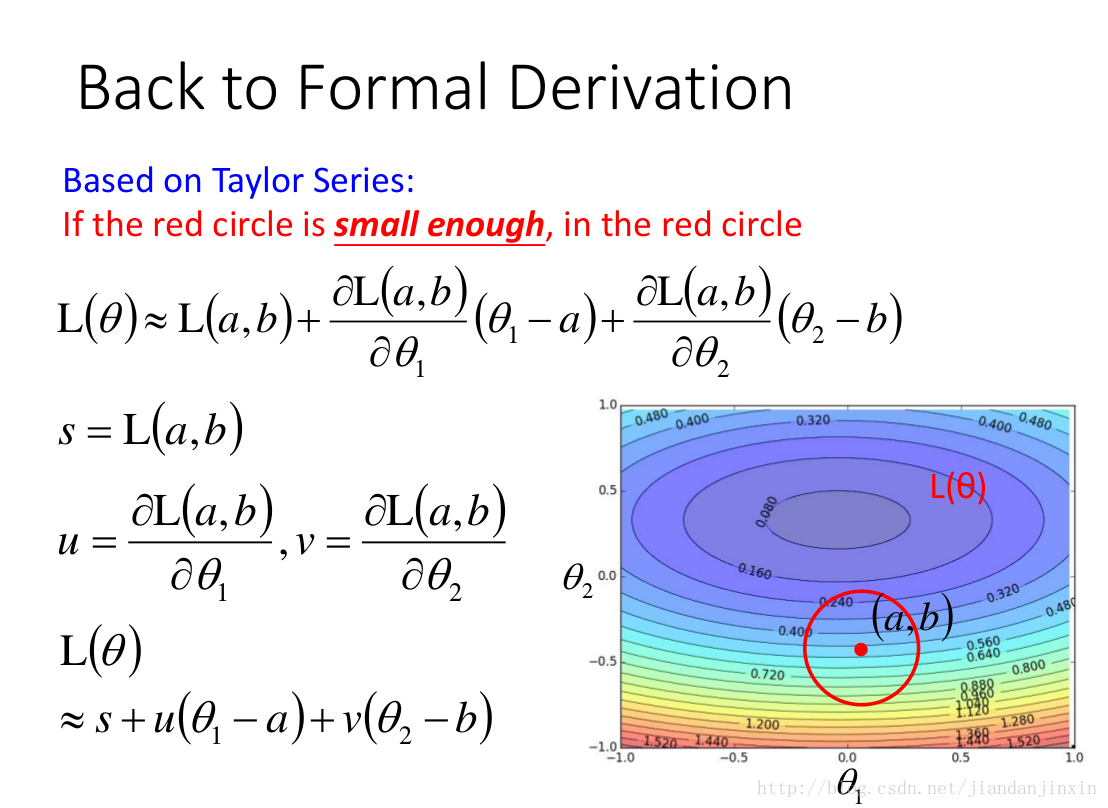
当红圈足够小时,损失函数可以缩简为如上形式。
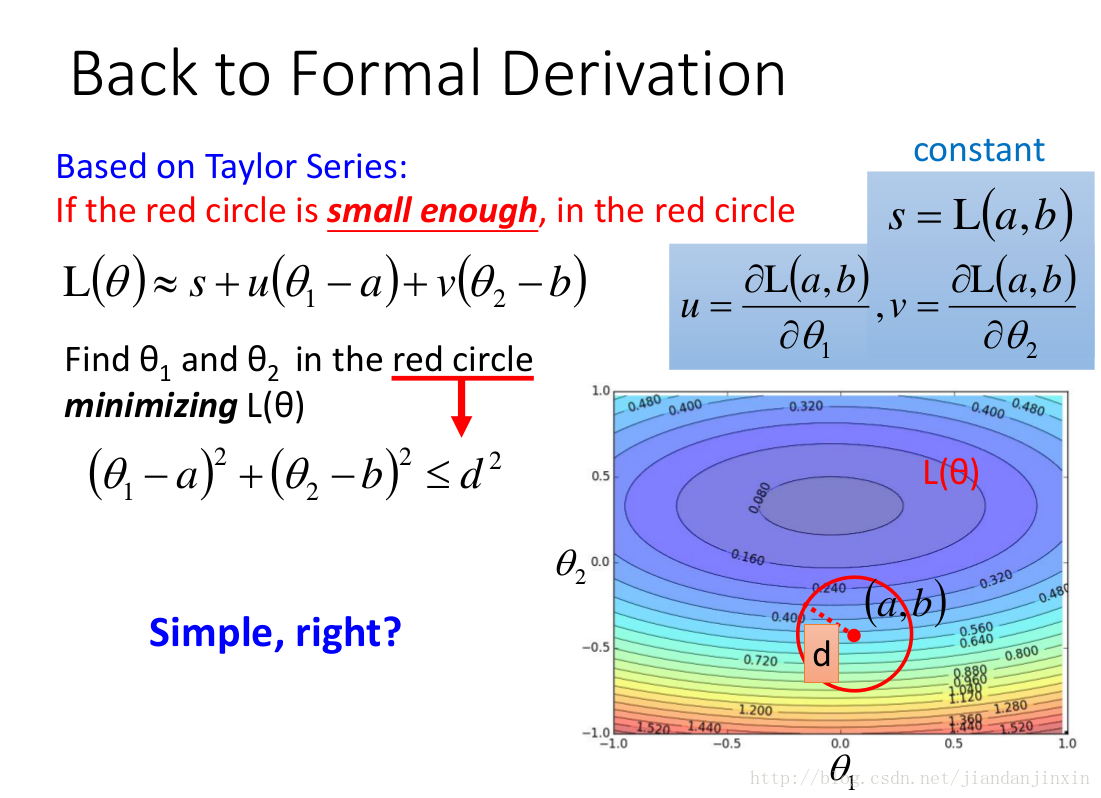

当红圈足够小,也就是半径足够小,也就是学习速率足够小时,可以很容易得到theata与u,v反向,足够长到半径尺度时,才能使得损失函数最小。那么最后给出的学习速率是与梯度成正比的。

上式成立的前提是学习速率足够小,当选择的学习速率不恰当时,就会出现损失函数来回波动,并不是一直变小。

梯度下降法的局限性
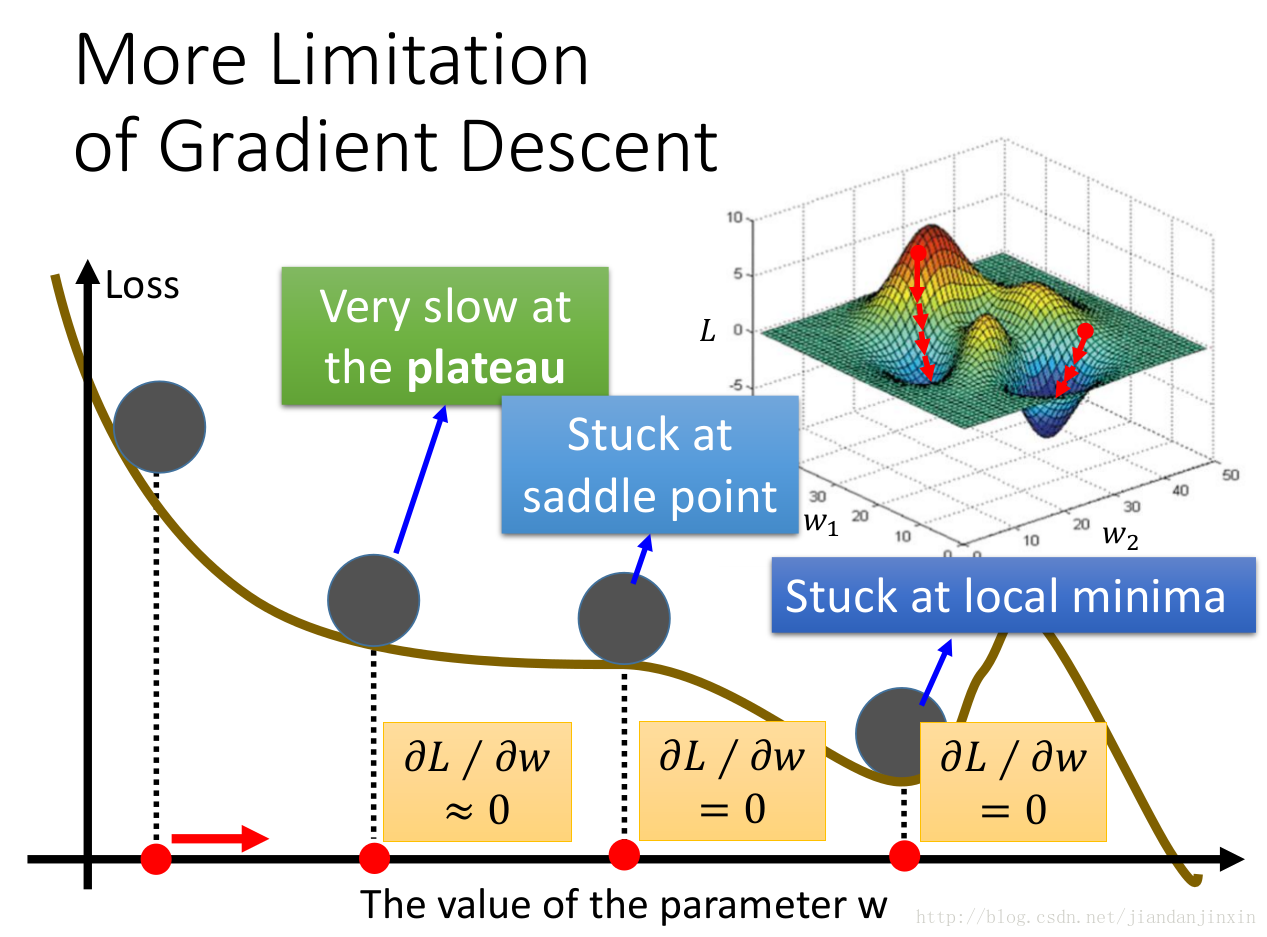
梯度下降法是找损失函数的局部极值点,也就是梯度为零的点。有时候,梯度为零的点并不总是局部极值点,还有可能是鞍点。实际上,我们往往会选择梯度比较小的点,来停止我们的参数更新,这时认为我们找到了局部极值点。如上图所示,梯度比较小的点,有可能是高原平稳点。
Deep Learning会陷入局部最优解的问题
本部分内容转自:https://www.zhihu.com/question/38549801
对于deep learning,我们是在一个非常高维的世界里做梯度下降。这时的 local minimum 很难形成,因为局部最小值要求函数在所有维度上都是局部最小。更实际得情况是,函数会落到一个saddle-point上,如下图
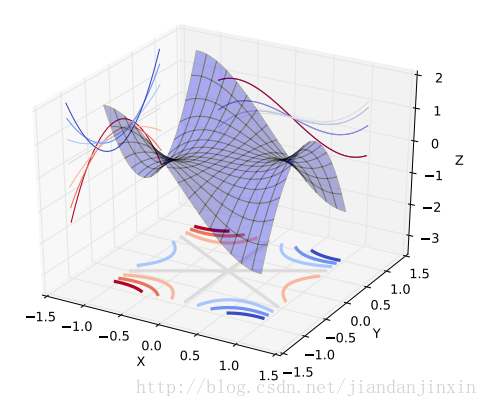
在saddle-point上会有一大片很平坦的平原,让梯度几乎为0,导致无法继续下降。反倒是local/global minimum的问题,大家发现其实不同的local minimum其实差不多(反正都是over-fitting training data),一般难找到local minimum,找到的一般是saddle point.
对于saddle point, 可以使用momentum技术。