我们先来看一段代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@File : gradient_descent_question.py
@Author : jeffsheng
@Date : 2019/11/29
@Desc : 梯度下降存在的问题
"""
import pystudy.d2lzh as d2l
from mxnet import nd
eta = 0.4
def f_2d(x1, x2):
return 0.1 * x1 ** 2 + 2 * x2 ** 2
def gd_2d(x1, x2, s1, s2):
return (x1 - eta * 0.2 * x1, x2 - eta * 4 * x2, 0, 0)
# 需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。
# 然而,这会造成自变量在水平方向上朝最优解移动变慢
d2l.show_trace_2d(f_2d, d2l.train_2d(gd_2d))
# 试着将学习率调得稍大一点,此时自变量在竖直方向不断越过最优解并逐渐发散
eta = 0.6
d2l.show_trace_2d(f_2d, d2l.train_2d(gd_2d))
def train_2d(trainer):
"""Optimize the objective function of 2d variables with a customized trainer."""
x1, x2 = -5, -2
s_x1, s_x2 = 0, 0
res = [(x1, x2)]
for i in range(20):
x1, x2, s_x1, s_x2 = trainer(x1, x2, s_x1, s_x2)
res.append((x1, x2))
print('epoch %d, x1 %f, x2 %f' % (i+1, x1, x2))
return res
def show_trace_2d(f, res):
"""Show the trace of 2d variables during optimization."""
x1, x2 = zip(*res)
set_figsize()
plt.plot(x1, x2, '-o', color='#ff7f0e')
x1 = np.arange(-5.5, 1.0, 0.1)
x2 = np.arange(min(-3.0, min(x2) - 1), max(1.0, max(x2) + 1), 0.1)
x1, x2 = np.meshgrid(x1, x2)
plt.contour(x1, x2, f(x1, x2), colors='#1f77b4')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
运行代码可以得到当学习率分别是0.4和0.6时的两种图像:
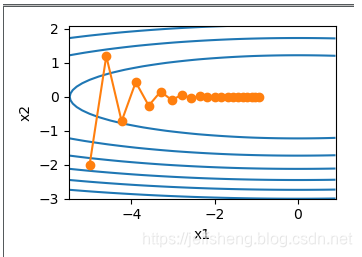
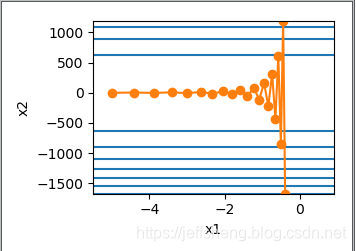
可以发现当学习率为0.4的时候开始纵轴x2比较震荡,后期逐渐收敛。而当学习率为0.6的时候,纵轴x2的震荡幅度相当的夸张,也就是说学习率稍微增大时,对于梯度下降在自变量x2上相当不稳定。我们的目标是让目标函数的值变得尽量小,而达到的手段就是本文的对(x1,x2)自变量进行梯度下降,这里的(x1,x2)就相当于是输入层的两个神经元,通过降低x1或者x2的值使得如下目标函数值达到最小值:
def f_2d(x1, x2):
return 0.1 * x1 ** 2 + 2 * x2 ** 2
这里我们通过高数知识可以看出当x1和x2都取0时目标函数有最小值,那么最终x1和x2通过梯度下降为0的时候目标函数达到最小值,很明显当学习率为0.6的时候,函数值明显增大了许多!因为在x1逼近0的时候,x2发散了。
接下来我们分析下代码:
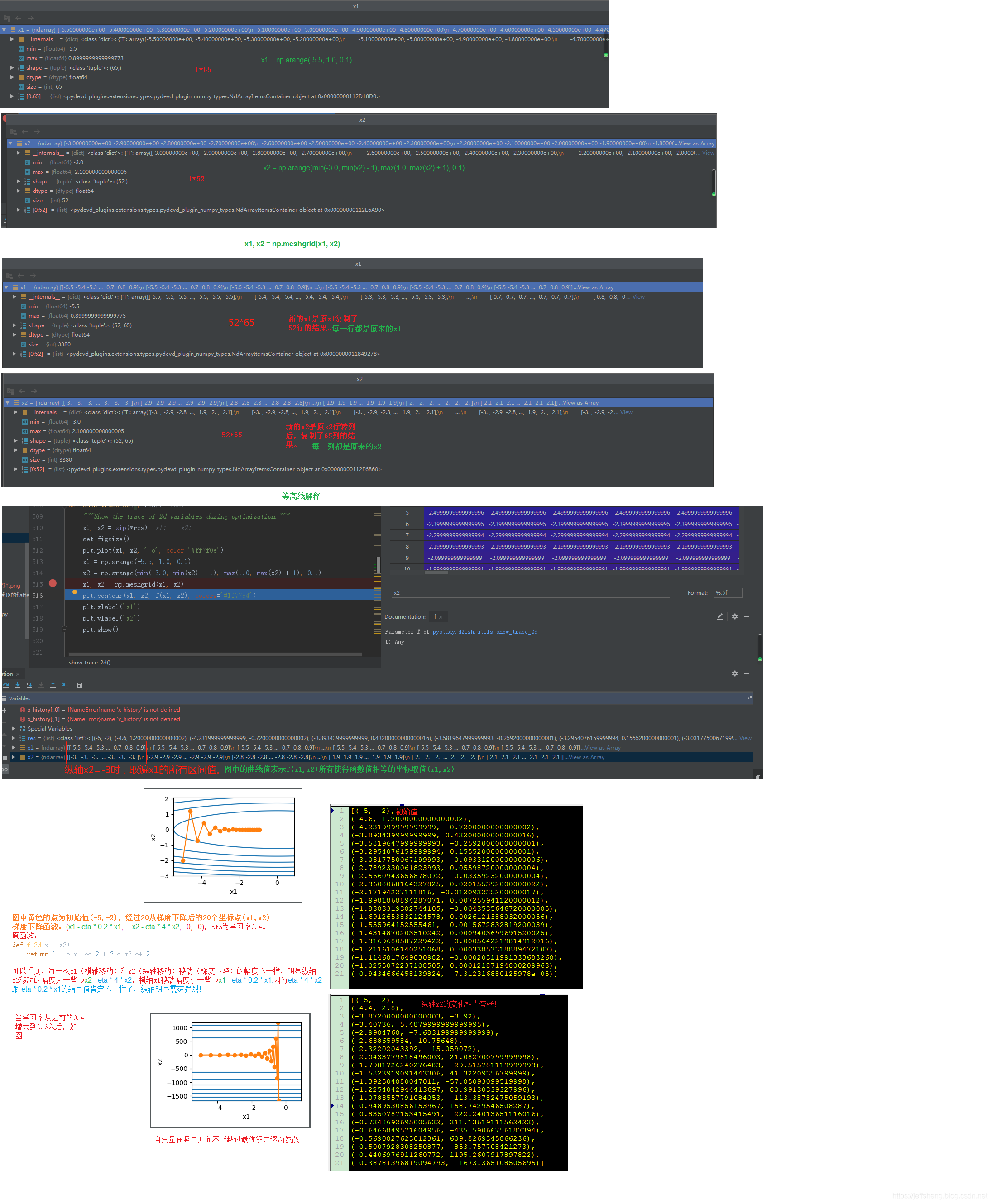
我都画到了图上,有不明白的,可以留言一起探讨~
