前言:网上查了大量写梯度下降法的文章,但是总是发现文章中存在很多问题,所以这里总结一下,更正错误。不然理解起来真的很困难。
参考博文:https://blog.csdn.net/qiang_GG2017/article/details/72667596
针对问题:最优化问题,迭代求最小偏差模型。
例子:对线性模型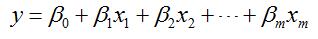
已知:大量的(X,y)样本数据,X为m阶向量。
求:系数β
思想:以梯度为方向,找到最优参数组合,使得损失函数下降到极小值。
解法步骤:
1.通常将模型写为下面的模型
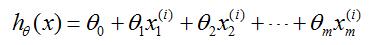
2.损失函数
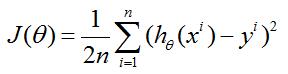
其中的1/2是为了使数据整齐加上的。因为后面要求导,2刚好抵消。
这个损失函数的意义就是,让得到的模型的预测值与真实值的误差平方和最小。
i为第几组样本值,共n组样本。
3.迭代公式
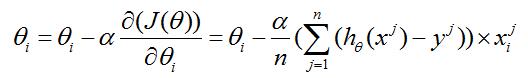
(i=0~m; j=1~n)
这里,偏导数为梯度值,决定迭代方向;
α为步长或称学习率,可以自己指定,但太大不收敛,太小收敛慢。推荐按照[0.001,0.003,0.01,0.03……]的顺序尝试设置。
PS:这个公式是参数更新公式,公式左边为当前代参数,公式右边为上一代的参数。
4.初值选取
初值可以任意指定,由于采用迭代方法,最终会收敛到一个极值点。但可能是局部极值。所以,有先验知识是最好,取在全局极值附近。
5.收敛条件
可以设定迭代代数,到这个代数就停止;
可以设定损失函数最小值,当损失函数到这个范围就停止迭代。
合理利用梯度下降法的经验:
1.随机的梯度下降(SGD):每次随机的挑一个样本学习,直到收敛才停止更新
2.小批量的梯度下降(Mini-batch):每次只学习一小部分,比如每次学习10个样本再更新
3.梯度下降(GD):全部样本学习一次,然后更新下(少用,效率低)
4.也可以设置最大迭代次数,比如设为100,若在100次内收敛了,则收敛时停止,若100次还未收敛那么就停止迭代