order by
order by 会对数据进行全局排序,和oracle和mysql等数据库中的order by 效果一样,
它只在一个reduce中进行所以数据量特别大的时候效率非常低。
而且当设置 :set hive.mapred.mode=strict的时候不指定limit,执行select会报错,如下:
LIMIT must also be specified.
sort by
sort by 是单独在各自的reduce中进行排序,所以并不能保证全局有序,一般和distribute by 一起执行,而且distribute by 要写在sort by前面
如果mapred.reduce.tasks=1和order by效果一样,如果大于1会分成几个文件输出每个文件会按照指定的字段排序,而不保证全局有序。
sort by 不受 hive.mapred.mode 是否为strict ,nostrict 的影响
distribute by
用distribute by 会对指定的字段按照hashCode值对reduce的个数取模,然后将任务分配到对应的reduce中去执行
就是在mapreduce程序中的patition分区过程,默认根据指定key.hashCode()&Integer.MAX_VALUE%numReduce 确定处理该任务的reduce
示例如下:
public class myPartitioner extends Partitioner<TextPair, Text>{
@Override
public int getPartition(TextPair key, Text value, int num) {
// TODO Auto-generated method stub
if(num == 0 ){
return 0;
}
int a = (key.getFirst().hashCode()&Integer.MAX_VALUE)%num;
return a;
}
}Cluster By
distribute by 和 sort by 合用就相当于cluster by,但是cluster by 不能指定排序为asc或 desc 的规则,只能是desc倒序排列。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Hive基于HADOOP来执行分布式程序的,和普通单机程序不同的一个特点就是最终的数据会产生多个子文件,每个reducer节点都会处理partition给自己的那份数据产生结果文件,这导致了在HADOOP环境下很难对数据进行全局排序,如果在HADOOP上进行order by全排序,会导致所有的数据集中在一台reducer节点上,然后进行排序,这样很可能会超过单个节点的磁盘和内存存储能力导致任务失败。
一种替代的方案则是放弃全局有序,而是分组有序,比如不求全百度最高的点击词排序,而是求每种产品线的最高点击词排序。
使用order by会引发全局排序
| select * from baidu_click order by click desc; |
使用distribute和sort进行分组排序
| select * from baidu_click distribute by product_line sort by click desc; |
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
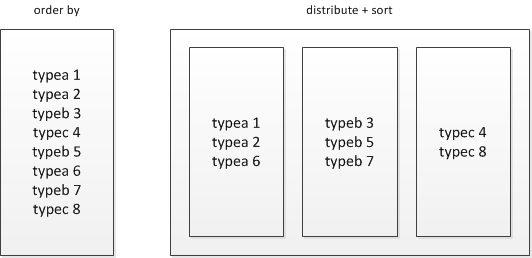
order by是全局有序而distribute+sort是分组有序
distribute+sort的结果是按组有序而全局无序的,输入数据经过了以下两个步骤的处理:
1) 根据KEY字段被HASH,相同组的数据被分发到相同的reducer节点;
2) 对每个组内部做排序
由于每组数据是按KEY进行HASH后的存储并且组内有序,其还可以有两种用途:
1) 直接作为HBASE的输入源,导入到HBASE;
2) 在distribute+sort后再进行orderby阶段,实现间接的全局排序;
不过即使是先distribute by然后sort by这样的操作,如果某个分组数据太大也会超出reduce节点的存储限制,常常会出现137内存溢出的错误,对大数据量的排序都是应该避免的。