在Hive中,可以像SQL一样对数据进行全局或局部排序,这里利用orders表来测试order by、sorty by、distribute by和cluster by的排序结果。
数据准备
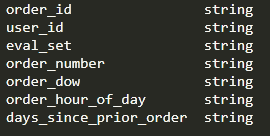
orders表的字段如下:利用order_dow(其取值范围是0-6)字段来测试
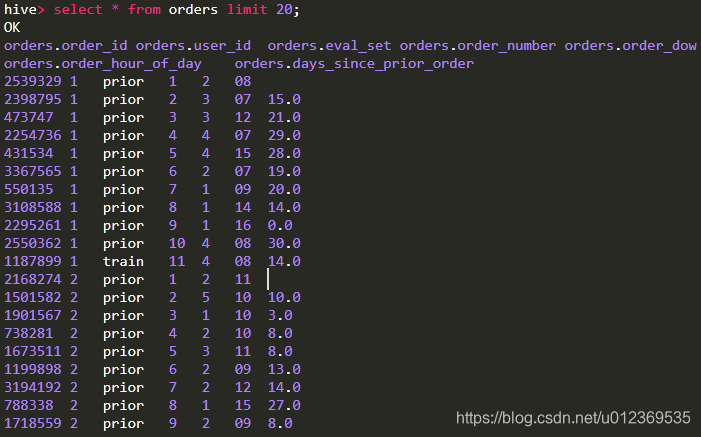
orders表的数据如下(limit 20):
在以下测试中我设置reduce数为3,便于观察不同排序的效果
set mapreduce.job.reduces=3;
set hive.cli.print.header=true;
Order by
SELECT t.order_id, t.user_id, t.order_dow
FROM orders t
ORDER BY cast(t.order_dow as int);
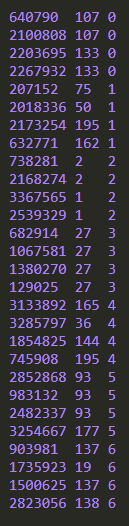
虽然我设置了reduces的数目,但是运行中ORDER BY仍然只会有一个reduce产生,其结果按照指定的order_dow全局排序
结果:
Sort by
sort by不像order by,它不能保证全局排序,在多个reduce输出的情况下,它只能保证每个reduce的输出结果有序
SELECT t.order_id, t.user_id, t.order_dow
FROM orders t
SORT BY cast(t.order_dow as int);
结果:
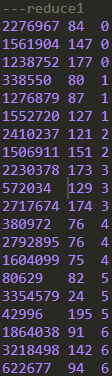
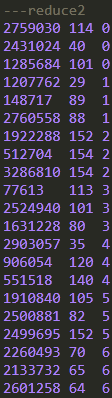
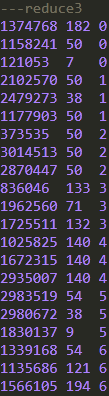
可以看到,在3个reduce的结果里,每个reduce的数据都会按照order_dow字段的数值升序,但是reduce与reduce之间并不是全局有序的
Distribute by
distribute by会根据指定字段的值,将记录分发到不同的reduce中,默认是对指定列的值取hash值,然后hash值对reduce的个数取模,每个模数都对应着一个reduce,这样含有相同字段值的记录会进入同一个reduce中,但是每个reduce中的数据并不是有序的,它只是负责将不同的记录分发到指定的reduce中,无法保证有序排列
SELECT t.order_id, t.user_id, t.order_dow
FROM orders t
DISTRIBUTE BY t.order_dow ;
结果:
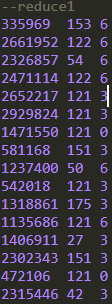
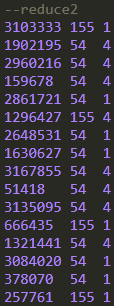
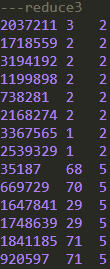
可以看到,order_dow值为0,3,6的记录都进入到reduce1中,order_dow值为1,4的记录都进入到reduce2中,值为2,5的记录进入到reduce3中,但是每个reduce内部并没有根据order_dow的值来排序
通常,将distribute by和sort by连用,这样在将指定字段的记录分发到不同的reduce中,并且每个reduce内部会根据指定字段值来排序
SELECT t.order_id, t.user_id, t.order_dow
FROM orders t
DISTRIBUTE BY t.order_dow
SORT BY cast(t.order_dow as int);
结果:
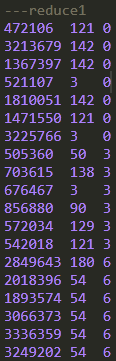
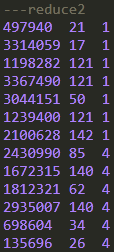
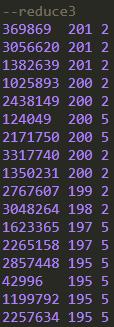
可以看到,与单独使用distribute by不同的是,字段值为0,3,6的记录在同一个reduce输出中并且是有序排列;另两个reduce的结果也是有序排列的
Cluster by
CLUSTER BY与DISTRIBUTE BY和SORT BY连用的执行结果是相同的
SELECT t.order_id, t.user_id, t.order_dow
FROM orders t
CLUSTER BY cast(t.order_dow as int);