Order By语法
colOrder: ( ASC | DESC )
colNullOrder: (NULLS FIRST | NULLS LAST) -- (Note: Available in Hive 2.1.0 and later)
orderBy: ORDER BY colName colOrder? colNullOrder? (',' colName colOrder? colNullOrder?)*
query: SELECT expression (',' expression)* FROM src orderBy
对全局数据的排序,只有一个reduce
Sort By语法
The SORT BY syntax is similar to the syntax of ORDER BY in SQL language.
colOrder: ( ASC | DESC )
sortBy: SORT BY colName colOrder? (
','
colName colOrder?)*
query: SELECT expression (
','
expression)* FROM src sortBy
|
对每一个Reduce内部进行排序,对全局结果集来说不是排序的
设置 reduce 执行的个数
set mapreduce.job.reduces=<number>
sort by样例
set mapreduce.job.reduces=3 insert overwrite local directory '/opt/datas/hive_exp_emp0308' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '\n' select * from emp sort by empno asc

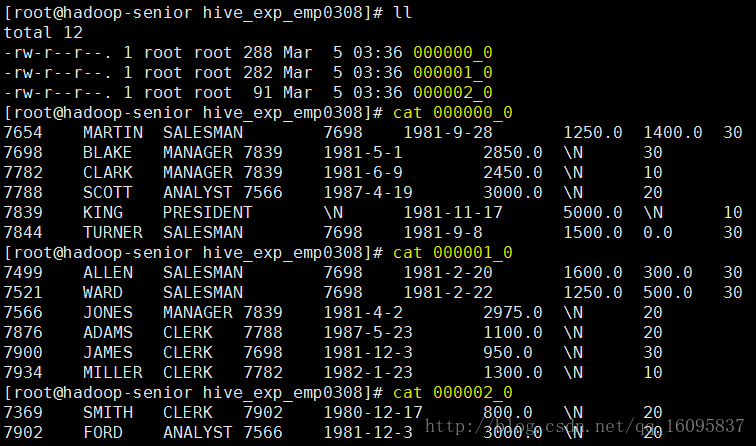
Distribute By
也就是分区partition,类似MapReduce中分区partition,对数据进行分区后,结合sort by 进行排序使用。
insert overwrite local directory '/opt/datas/hive_exp_distribute_emp0308' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '\n' select * from emp distribute by deptno sort by empno asc

第一个分区数据000000_0

第二个分区000001_0
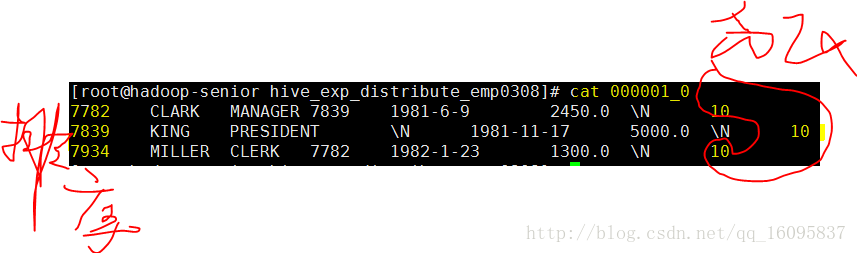
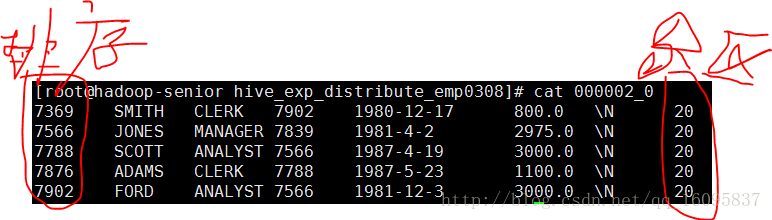
第三个分区
000002_0
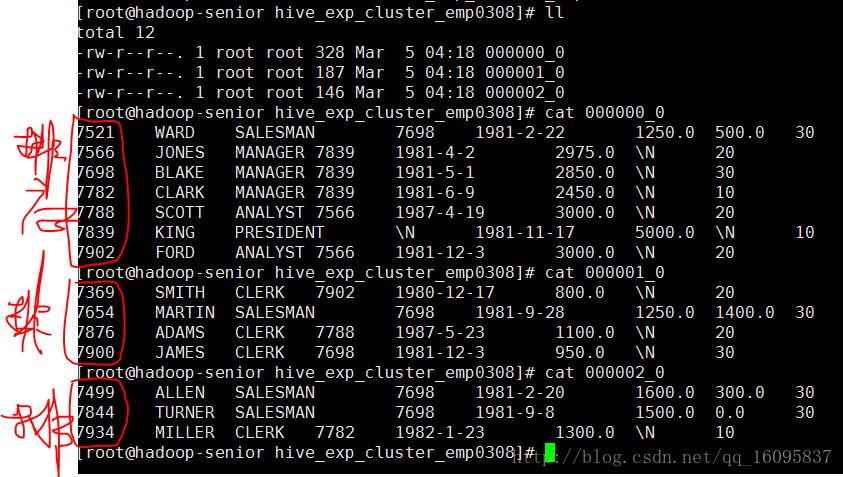
Cluster By
当sort by 和 distribute by的字段相同时,就可以使用Cluster By替换。
insert overwrite local directory '/opt/datas/hive_exp_cluster_emp0308' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '\n' select * from emp cluster by empno
总结
Hive中select新特性
Order By全局排序,一个Reduce
Sort By
每个reduce内部进行排序,全局不是排序
Distribute By
类似MR中partition,进行分区,结合sort by使用
Cluster By
当distribute和sort字段相同时,使用方式