版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wds2006sdo/article/details/52849400
相关文章:
- 李航《统计学习方法》第二章——用Python实现感知器模型(MNIST数据集)
- 李航《统计学习方法》第三章——用Python实现KNN算法(MNIST数据集)
- 李航《统计学习方法》第四章——用Python实现朴素贝叶斯分类器(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现逻辑斯谛回归(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现最大熵模型(MNIST数据集)
- 李航《统计学习方法》第七章——用Python实现支持向量机模型(伪造数据集)
- 李航《统计学习方法》第八章——用Python+Cpp实现AdaBoost算法(MNIST数据集)
- 李航《统计学习方法》第十章——用Python实现隐马尔科夫模型
看了决策树啊,就有那么几个疑问:
- 决策树是否只能处理特征值可数的情况
- 决策树是否无法处理不在训练集中出现的特征值
这几个疑问等以后有空的时候在慢慢探索吧!
决策树
按照传统不详述该算法,具体内容可以看《统计学习方法》第五章。
我实现的是ID3算法
这里只将书中算法贴出来


数据集
数据集没什么可以说的,和KNN那个博文用的是同样的数据集。
数据地址:https://github.com/WenDesi/lihang_book_algorithm/blob/master/data/train.csv
特征
将整个图作为特征,但需要二值化处理。
代码
计算信息增益的代码参考的是Avalon的博客
代码已放到Github上,代码注释中标识了书中伪代码的各步骤,因此还算易懂(吐槽一下,这代码相较之前的代码还真不太好写)
#encoding=utf-8
import cv2
import time
import logging
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
total_class = 10
def log(func):
def wrapper(*args, **kwargs):
start_time = time.time()
logging.debug('start %s()' % func.__name__)
ret = func(*args, **kwargs)
end_time = time.time()
logging.debug('end %s(), cost %s seconds' % (func.__name__,end_time-start_time))
return ret
return wrapper
# 二值化
def binaryzation(img):
cv_img = img.astype(np.uint8)
cv2.threshold(cv_img,50,1,cv2.cv.CV_THRESH_BINARY_INV,cv_img)
return cv_img
@log
def binaryzation_features(trainset):
features = []
for img in trainset:
img = np.reshape(img,(28,28))
cv_img = img.astype(np.uint8)
img_b = binaryzation(cv_img)
# hog_feature = np.transpose(hog_feature)
features.append(img_b)
features = np.array(features)
features = np.reshape(features,(-1,784))
return features
class Tree(object):
def __init__(self,node_type,Class = None, feature = None):
self.node_type = node_type
self.dict = {}
self.Class = Class
self.feature = feature
def add_tree(self,val,tree):
self.dict[val] = tree
def predict(self,features):
if self.node_type == 'leaf':
return self.Class
tree = self.dict[features[self.feature]]
return tree.predict(features)
def calc_ent(x):
"""
calculate shanno ent of x
"""
x_value_list = set([x[i] for i in range(x.shape[0])])
ent = 0.0
for x_value in x_value_list:
p = float(x[x == x_value].shape[0]) / x.shape[0]
logp = np.log2(p)
ent -= p * logp
return ent
def calc_condition_ent(x, y):
"""
calculate ent H(y|x)
"""
# calc ent(y|x)
x_value_list = set([x[i] for i in range(x.shape[0])])
ent = 0.0
for x_value in x_value_list:
sub_y = y[x == x_value]
temp_ent = calc_ent(sub_y)
ent += (float(sub_y.shape[0]) / y.shape[0]) * temp_ent
return ent
def calc_ent_grap(x,y):
"""
calculate ent grap
"""
base_ent = calc_ent(y)
condition_ent = calc_condition_ent(x, y)
ent_grap = base_ent - condition_ent
return ent_grap
def recurse_train(train_set,train_label,features,epsilon):
global total_class
LEAF = 'leaf'
INTERNAL = 'internal'
# 步骤1——如果train_set中的所有实例都属于同一类Ck
label_set = set(train_label)
if len(label_set) == 1:
return Tree(LEAF,Class = label_set.pop())
# 步骤2——如果features为空
(max_class,max_len) = max([(i,len(filter(lambda x:x==i,train_label))) for i in xrange(total_class)],key = lambda x:x[1])
if len(features) == 0:
return Tree(LEAF,Class = max_class)
# 步骤3——计算信息增益
max_feature = 0
max_gda = 0
D = train_label
HD = calc_ent(D)
for feature in features:
A = np.array(train_set[:,feature].flat)
gda = HD - calc_condition_ent(A,D)
if gda > max_gda:
max_gda,max_feature = gda,feature
# 步骤4——小于阈值
if max_gda < epsilon:
return Tree(LEAF,Class = max_class)
# 步骤5——构建非空子集
sub_features = filter(lambda x:x!=max_feature,features)
tree = Tree(INTERNAL,feature=max_feature)
feature_col = np.array(train_set[:,max_feature].flat)
feature_value_list = set([feature_col[i] for i in range(feature_col.shape[0])])
for feature_value in feature_value_list:
index = []
for i in xrange(len(train_label)):
if train_set[i][max_feature] == feature_value:
index.append(i)
sub_train_set = train_set[index]
sub_train_label = train_label[index]
sub_tree = recurse_train(sub_train_set,sub_train_label,sub_features,epsilon)
tree.add_tree(feature_value,sub_tree)
return tree
@log
def train(train_set,train_label,features,epsilon):
return recurse_train(train_set,train_label,features,epsilon)
@log
def predict(test_set,tree):
result = []
for features in test_set:
tmp_predict = tree.predict(features)
result.append(tmp_predict)
return np.array(result)
if __name__ == '__main__':
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
raw_data = pd.read_csv('../data/train.csv',header=0)
data = raw_data.values
imgs = data[0::,1::]
labels = data[::,0]
# 图片二值化
features = binaryzation_features(imgs)
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=23323)
tree = train(train_features,train_labels,[i for i in range(784)],0.1)
test_predict = predict(test_features,tree)
score = accuracy_score(test_labels,test_predict)
print "The accruacy socre is ", score
运行结果
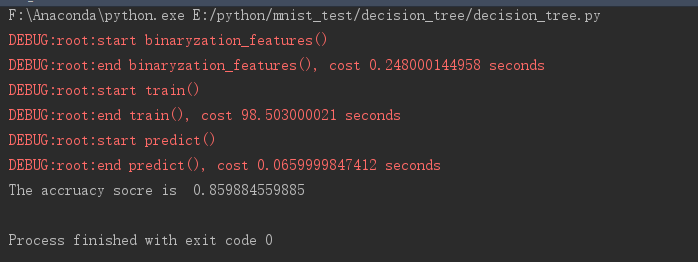
准确率一般,预测速度到挺快的。