版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wds2006sdo/article/details/53195725
相关文章:
- 李航《统计学习方法》第二章——用Python实现感知器模型(MNIST数据集)
- 李航《统计学习方法》第三章——用Python实现KNN算法(MNIST数据集)
- 李航《统计学习方法》第四章——用Python实现朴素贝叶斯分类器(MNIST数据集)
- 李航《统计学习方法》第五章——用Python实现决策树(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现逻辑斯谛回归(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现最大熵模型(MNIST数据集)
- 李航《统计学习方法》第七章——用Python实现支持向量机模型(伪造数据集)
- 李航《统计学习方法》第十章——用Python实现隐马尔科夫模型
第八章我打算就实现一个AdaBoost算法了。
AdaBoost看起来就是将一堆弱分类器的线性组合。
知乎上说AdaBoost分类器不适合上强分类器,且直接上强分类器也体现不出AdaBoost的效果,因此打算在MNIST数据集上使用例8.1的分类器,即阈值分类器。
AdaBoost算法
这里先贴上书上的算法
算法


细节处理
我们使用的弱分类器是例8.1的阈值分类器,但阈值分类器只能分类单一维度的特征,而通常情况下我们的特征都是多维的,这时就需要我们使用一些trick。
假设特征有n维,我们针对每一维特征求一个分类器,选取这些分类器中分类误差率最低的分类器作为本轮的分类器,将其特征坐标与分类器一起存入G(x)中。
当分类时,获取当前分类器Gm(x)及其特征坐标i,选取测试数据X的第i个特征X[i],放入分类器中分类,即Gm(X[i])。
如此一来,就能解决阈值分类器在多维特征下的情况了!
数据集
数据集和感知器那个博文用的是同样的数据集。
数据地址:https://github.com/WenDesi/lihang_book_algorithm/blob/master/data/train_binary.csv
特征
将整个图作为特征,但需要先经过二值化处理
代码
因为纯python的代码运行速度有些慢,所以我又写了一个版本,将计算阈值分类器那段写成了C++版本,编译成dll,加快运行速度。
纯python
代码已放到Github上,这边也贴出来
# encoding=utf-8
# @Author: wendesi
# @Date: 15-11-16
# @Email: [email protected]
# @Last modified by: wendesi
# @Last modified time: 17-11-16
import cv2
import time
import math
import logging
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
sign_time_count = 0
class Sign(object):
'''
阈值分类器
有两种方向,
1)x<v y=1
2) x>v y=1
v 是阈值轴
因为是针对已经二值化后的MNIST数据集,所以v的取值只有3个 {0,1,2}
'''
def __init__(self,features,labels,w):
self.X = features # 训练数据特征
self.Y = labels # 训练数据的标签
self.N = len(labels) # 训练数据大小
self.w = w # 训练数据权值分布
self.indexes = [0,1,2] # 阈值轴可选范围
def _train_less_than_(self):
'''
寻找(x<v y=1)情况下的最优v
'''
index = -1
error_score = 1000000
for i in self.indexes:
score = 0
for j in xrange(self.N):
val = -1
if self.X[j]<i:
val = 1
if val*self.Y[j]<0:
score += self.w[j]
if score < error_score:
index = i
error_score = score
return index,error_score
def _train_more_than_(self):
'''
寻找(x>v y=1)情况下的最优v
'''
index = -1
error_score = 1000000
for i in self.indexes:
score = 0
for j in xrange(self.N):
val = 1
if self.X[j]<i:
val = -1
if val*self.Y[j]<0:
score += self.w[j]
if score < error_score:
index = i
error_score = score
return index,error_score
def train(self):
global sign_time_count
time1 = time.time()
less_index,less_score = self._train_less_than_()
more_index,more_score = self._train_more_than_()
time2 = time.time()
sign_time_count += time2-time1
if less_score < more_score:
self.is_less = True
self.index = less_index
return less_score
else:
self.is_less = False
self.index = more_index
return more_score
def predict(self,feature):
if self.is_less>0:
if feature<self.index:
return 1.0
else:
return -1.0
else:
if feature<self.index:
return -1.0
else:
return 1.0
class AdaBoost(object):
def __init__(self):
pass
def _init_parameters_(self,features,labels):
self.X = features # 训练集特征
self.Y = labels # 训练集标签
self.n = len(features[0]) # 特征维度
self.N = len(features) # 训练集大小
self.M = 10 # 分类器数目
self.w = [1.0/self.N]*self.N # 训练集的权值分布
self.alpha = [] # 分类器系数 公式8.2
self.classifier = [] # (维度,分类器),针对当前维度的分类器
def _w_(self,index,classifier,i):
'''
公式8.4不算Zm
'''
return self.w[i]*math.exp(-self.alpha[-1]*self.Y[i]*classifier.predict(self.X[i][index]))
def _Z_(self,index,classifier):
'''
公式8.5
'''
Z = 0
for i in xrange(self.N):
Z += self._w_(index,classifier,i)
return Z
def train(self,features,labels):
self._init_parameters_(features,labels)
for times in xrange(self.M):
logging.debug('iterater %d' % times)
time1 = time.time()
map_time = 0
best_classifier = (100000,None,None) #(误差率,针对的特征,分类器)
for i in xrange(self.n):
map_time -= time.time()
features = map(lambda x:x[i],self.X)
map_time += time.time()
classifier = Sign(features,self.Y,self.w)
error_score = classifier.train()
if error_score < best_classifier[0]:
best_classifier = (error_score,i,classifier)
em = best_classifier[0]
# 分析用,之后删除 开始
print 'em is %s, index is %d' % (str(em),best_classifier[1])
time2 = time.time()
global sign_time_count
print '总运行时间:%s, 那两段关键代码运行时间:%s, map的时间是:%s' % (str(time2-time1),str(sign_time_count),str(map_time))
sign_time_count = 0
# 分析用,之后删除 结束
if em==0:
self.alpha.append(100)
else:
self.alpha.append(0.5*math.log((1-em)/em))
self.classifier.append(best_classifier[1:])
Z = self._Z_(best_classifier[1],best_classifier[2])
# 计算训练集权值分布 8.4
for i in xrange(self.N):
self.w[i] = self._w_(best_classifier[1],best_classifier[2],i)/Z
def _predict_(self,feature):
result = 0.0
for i in xrange(self.M):
index = self.classifier[i][0]
classifier = self.classifier[i][1]
result += self.alpha[i]*classifier.predict(feature[index])
if result>0:
return 1
return -1
def predict(self,features):
results = []
for feature in features:
results.append(self._predict_(feature))
return results
# 二值化
def binaryzation(img):
cv_img = img.astype(np.uint8)
cv2.threshold(cv_img,50,1,cv2.cv.CV_THRESH_BINARY_INV,cv_img)
return cv_img
def binaryzation_features(trainset):
features = []
for img in trainset:
img = np.reshape(img,(28,28))
cv_img = img.astype(np.uint8)
img_b = binaryzation(cv_img)
# hog_feature = np.transpose(hog_feature)
features.append(img_b)
features = np.array(features)
features = np.reshape(features,(-1,784))
return features
if __name__ == '__main__':
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
print 'Start read data'
time_1 = time.time()
raw_data = pd.read_csv('../data/train_binary.csv',header=0)
data = raw_data.values
imgs = data[0::,1::]
labels = data[::,0]
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
features = binaryzation_features(imgs)
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.5, random_state=0)
time_2 = time.time()
print 'read data cost ',time_2 - time_1,' second','\n'
print 'Start training'
train_labels = map(lambda x:2*x-1,train_labels)
ada = AdaBoost()
ada.train(train_features, train_labels)
time_3 = time.time()
print 'training cost ',time_3 - time_2,' second','\n'
print 'Start predicting'
test_predict = ada.predict(test_features)
time_4 = time.time()
print 'predicting cost ',time_4 - time_3,' second','\n'
test_labels = map(lambda x:2*x-1,test_labels)
score = accuracy_score(test_labels,test_predict)
print "The accruacy socre is ", scorepython+cpp
因为大体思路同纯python版,所以懒得写注释了
adaboost_cpp.py Github
# encoding=utf-8
# @Author: wendesi
# @Date: 15-11-16
# @Email: [email protected]
# @Last modified by: wendesi
# @Last modified time: 15-11-16
import cv2
import time
import math
import ctypes
import logging
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
sign_time_count = 0
class Sign(object):
def __init__(self,is_less,index):
self.is_less = is_less
self.index = index
def predict(self,feature):
if self.is_less>0:
if feature<self.index:
return 1.0
else:
return -1.0
else:
if feature<self.index:
return -1.0
else:
return 1.0
class AdaBoost(object):
def __init__(self):
ll = ctypes.cdll.LoadLibrary
self.lib = ll("Sign/x64/Release/Sign.dll")
def rebuild_X(self,X):
length = self.n*self.N
self.X_matrix = (ctypes.c_int * length)()
for i in xrange(self.n):
for j in xrange(self.N):
self.X_matrix[i*self.N+j] = X[j][i]
def rebuild_Y(self,Y):
self.C_Y = (ctypes.c_int * self.N)()
for i in xrange(self.N):
self.C_Y[i] = Y[i]
def _init_parameters_(self,features,labels):
self.Y = labels
self.n = len(features[0])
self.N = len(features)
self.M = 100 # 分类器数目
self.w = [1.0/self.N]*self.N
self.alpha = []
self.classifier = []
self.rebuild_X(features)
self.rebuild_Y(labels)
def _w_(self,index,classifier,i):
feature = self.X_matrix[index*self.N+i]
return self.w[i]*math.exp(-self.alpha[-1]*self.Y[i]*classifier.predict(feature))
def _Z_(self,index,classifier):
Z = 0
for i in xrange(self.N):
Z += self._w_(index,classifier,i)
return Z
def build_c_w(self):
C_w = (ctypes.c_double * self.N)()
for i in xrange(self.N):
C_w[i] = ctypes.c_double(self.w[i])
return C_w
def train(self,features,labels):
self._init_parameters_(features,labels)
for times in xrange(self.M):
logging.debug('iterater %d' % times)
C_w = self.build_c_w()
min_error = ctypes.c_double(100000)
is_less = ctypes.c_int(-1)
feature_index = ctypes.c_int(-1)
index = self.lib.find_min_error(self.X_matrix,self.n,self.N,self.C_Y,C_w,ctypes.byref(min_error),ctypes.byref(is_less),ctypes.byref(feature_index))
em = min_error.value
best_classifier = (em,feature_index.value,Sign(is_less.value,index)) #(误差率,针对的特征,分类器)
print 'em is %s, index is %s' % (str(em),str(feature_index.value))
if em==0:
self.alpha.append(100)
else:
self.alpha.append(0.5*math.log((1-em)/em))
self.classifier.append(best_classifier[1:])
Z = self._Z_(best_classifier[1],best_classifier[2])
for i in xrange(self.N):
self.w[i] = self._w_(best_classifier[1],best_classifier[2],i)/Z
def _predict_(self,feature):
result = 0.0
for i in xrange(self.M):
index = self.classifier[i][0]
classifier = self.classifier[i][1]
result += self.alpha[i]*classifier.predict(feature[index])
if result>0:
return 1
return -1
def predict(self,features):
results = []
for feature in features:
results.append(self._predict_(feature))
return results
# 二值化
def binaryzation(img):
cv_img = img.astype(np.uint8)
cv2.threshold(cv_img,50,1,cv2.cv.CV_THRESH_BINARY_INV,cv_img)
return cv_img
def binaryzation_features(trainset):
features = []
for img in trainset:
img = np.reshape(img,(28,28))
cv_img = img.astype(np.uint8)
img_b = binaryzation(cv_img)
# hog_feature = np.transpose(hog_feature)
features.append(img_b)
features = np.array(features)
features = np.reshape(features,(-1,784))
return features
if __name__ == '__main__':
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
print 'Start read data'
time_1 = time.time()
raw_data = pd.read_csv('../data/train_binary.csv',header=0)
data = raw_data.values
imgs = data[0::,1::]
labels = data[::,0]
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
features = binaryzation_features(imgs)
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=23323)
time_2 = time.time()
print 'read data cost ',time_2 - time_1,' second','\n'
print 'Start training'
train_labels = map(lambda x:2*x-1,train_labels)
ada = AdaBoost()
ada.train(train_features, train_labels)
time_3 = time.time()
print 'training cost ',time_3 - time_2,' second','\n'
print 'Start predicting'
test_predict = ada.predict(test_features)
time_4 = time.time()
print 'predicting cost ',time_4 - time_3,' second','\n'
test_labels = map(lambda x:2*x-1,test_labels)
score = accuracy_score(test_labels,test_predict)
print "The accruacy socre is ", score
sign.h Github
#pragma once
extern "C" __declspec(dllexport) int find_min_error(int* X,int rows,int cols,int* y,double* w,double& min_error,int& is_less,int& feature_index);
sign.cpp Github
#include <iostream>
using namespace std;
#include "sign.h"
int find_min_error(int* X,int rows,int cols,int* y,double* w,double& min_error,int& is_less,int& feature_index)
{
int index = -1;
for(int row=0;row<rows;row++)
{
for(int i=0;i<3;i++)
{
double score = 0;
for(int j=0;j<cols;j++)
{
int val = -1;
if(X[row*cols+j]<i)
{
val = 1;
}
if(val*y[j]<0)
score += w[j];
}
if(score < min_error)
{
index = i;
is_less = 1;
min_error = score;
feature_index = row;
}
}
}
for(int row=0;row<rows;row++)
{
for(int i=0;i<3;i++)
{
double score = 0;
for(int j=0;j<cols;j++)
{
int val = 1;
if(X[row*cols+j]<i)
{
val = -1;
}
if(val*y[j]<0)
score += w[j];
}
if(score < min_error)
{
index = i;
is_less = 0;
min_error = score;
feature_index = row;
}
}
}
return index;
}运行结果
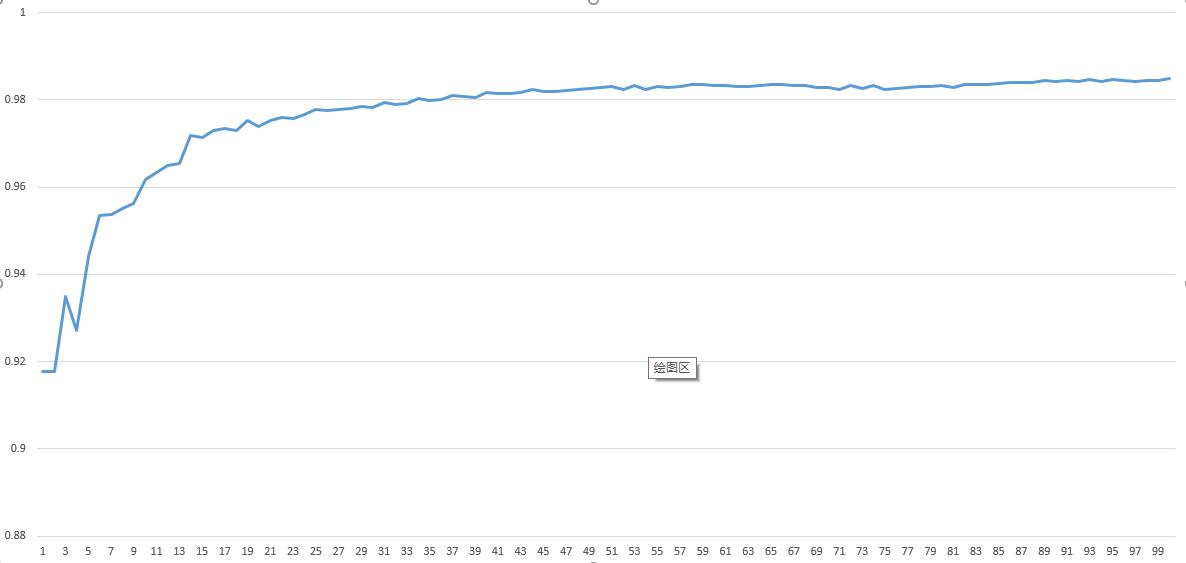
结果还是不错的嘛!
让我比较惊讶的是Python和C++运算速度差真的很大,网上说是大约30倍。但我这测试大约是200倍左右,可能也和这数据量大有些关系。