版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wds2006sdo/article/details/53156589
相关文章:
- 李航《统计学习方法》第二章——用Python实现感知器模型(MNIST数据集)
- 李航《统计学习方法》第三章——用Python实现KNN算法(MNIST数据集)
- 李航《统计学习方法》第四章——用Python实现朴素贝叶斯分类器(MNIST数据集)
- 李航《统计学习方法》第五章——用Python实现决策树(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现逻辑斯谛回归(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现最大熵模型(MNIST数据集)
- 李航《统计学习方法》第八章——用Python+Cpp实现AdaBoost算法(MNIST数据集)
- 李航《统计学习方法》第十章——用Python实现隐马尔科夫模型
在我看来,SVM的基本思想其实就是找一个超平面,这个超平面能正确划分训练数据集并且几何间距最大!
必须承认,我的SVM效果不好,且训练速度很慢,以至于不能用MNIST数据集进行测试。
支持向量机
我实现的是SMO算法
这里先贴上书上的算法

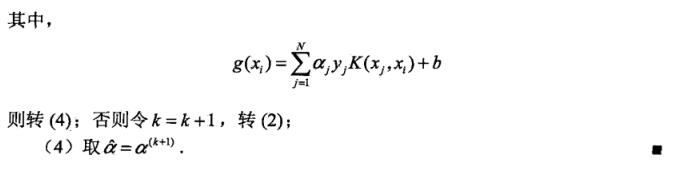
数据集
MNIST数据集特征太多,训练集也太大,导致SVM在计算初始E值得时候代价太高,运行时间太长,因此放弃使用MNIST数据集而选择使用伪造数据集。
数据集是伪造的二维的数据集,定义域为[0,1],值域为{-1,1},代码来自water1990一篇博客,稍微改了一下
代码
代码已放到Github上,这边也贴出来
# encoding=utf-8
# @Author: WenDesi
# @Date: 12-11-16
# @Email: [email protected]
# @Last modified by: WenDesi
# @Last modified time: 13-11-16
import time
import random
import logging
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from generate_dataset import *
class SVM(object):
def __init__(self, kernel='linear',epsilon = 0.001):
self.kernel = kernel
self.epsilon = epsilon
def _init_parameters(self, features, labels):
'''
初始化一些参数
'''
self.X = features
self.Y = labels
self.b = 0.0
self.n = len(features[0])
self.N = len(features)
self.alpha = [0.0] * self.N
self.E = [self._E_(i) for i in xrange(self.N)]
self.C = 1000
self.Max_Interation = 5000
def _satisfy_KKT(self, i):
ygx = self.Y[i] * self._g_(i)
if abs(self.alpha[i])<self.epsilon:
return ygx > 1 or ygx == 1
elif abs(self.alpha[i]-self.C)<self.epsilon:
return ygx < 1 or ygx == 1
else:
return abs(ygx-1) < self.epsilon
def is_stop(self):
for i in xrange(self.N):
satisfy = self._satisfy_KKT(i)
if not satisfy:
return False
return True
def _select_two_parameters(self):
'''
按照书上7.4.2选择两个变量
'''
index_list = [i for i in xrange(self.N)]
i1_list_1 = filter(lambda i: self.alpha[i] > 0 and self.alpha[i] < self.C, index_list)
i1_list_2 = list(set(index_list) - set(i1_list_1))
i1_list = i1_list_1
i1_list.extend(i1_list_2)
for i in i1_list:
if self._satisfy_KKT(i):
continue
E1 = self.E[i]
max_ = (0, 0)
for j in index_list:
if i == j:
continue
E2 = self.E[j]
if abs(E1 - E2) > max_[0]:
max_ = (abs(E1 - E2), j)
return i, max_[1]
def _K_(self, x1, x2):
'''
核函数
'''
if self.kernel == 'linear':
return sum([x1[k] * x2[k] for k in xrange(self.n)])
if self.kernel == 'poly':
return (sum([x1[k] * x2[k] for k in xrange(self.n)])+1)**3
print '没有定义核函数'
return 0
def _g_(self, i):
'''
公式(7.104)
'''
result = self.b
for j in xrange(self.N):
result += self.alpha[j] * self.Y[j] * self._K_(self.X[i], self.X[j])
return result
def _E_(self, i):
'''
公式(7.105)
'''
return self._g_(i) - self.Y[i]
def try_E(self,i):
result = self.b-self.Y[i]
for j in xrange(self.N):
if self.alpha[j]<0 or self.alpha[j]>self.C:
continue
result += self.Y[j]*self.alpha[j]*self._K_(self.X[i],self.X[j])
return result
def train(self, features, labels):
self._init_parameters(features, labels)
for times in xrange(self.Max_Interation):
# if self.is_stop():
# return
logging.debug('iterater %d' % times)
i1, i2 = self._select_two_parameters()
L = max(0, self.alpha[i2] - self.alpha[i1])
H = min(self.C, self.C + self.alpha[i2] - self.alpha[i1])
if self.Y[i1] == self.Y[i2]:
L = max(0, self.alpha[i2] + self.alpha[i1] - self.C)
H = min(self.C, self.alpha[i2] + self.alpha[i1])
E1 = self.E[i1]
E2 = self.E[i2]
eta = self._K_(self.X[i1], self.X[i1]) + self._K_(self.X[i2], self.X[i2]) - 2 * self._K_(self.X[i1], self.X[i2]) # 公式(7.107)
alpha2_new_unc = self.alpha[i2] + self.Y[i2] * (E1 - E2) / eta # 公式(7.106)
# 公式(7.108)
alph2_new = 0
if alpha2_new_unc > H:
alph2_new = H
elif alpha2_new_unc < L:
alph2_new = L
else:
alph2_new = alpha2_new_unc
# 公式(7.109)
alph1_new = self.alpha[i1] + self.Y[i1] * \
self.Y[i2] * (self.alpha[i2] - alph2_new)
# 公式(7.115) 及 公式(7.116)
b_new = 0
b1_new = -E1 - self.Y[i1] * self._K_(self.X[i1], self.X[i1]) * (alph1_new - self.alpha[i1]) - self.Y[i2] * self._K_(self.X[i2], self.X[i1]) * (alph2_new - self.alpha[i2]) + self.b
b2_new = -E2 - self.Y[i1] * self._K_(self.X[i1], self.X[i2]) * (alph1_new - self.alpha[i1]) - self.Y[i2] * self._K_(self.X[i2], self.X[i2]) * (alph2_new - self.alpha[i2]) + self.b
if alph1_new > 0 and alph1_new < self.C:
b_new = b1_new
elif alph2_new > 0 and alph2_new < self.C:
b_new = b2_new
else:
b_new = (b1_new + b2_new) / 2
self.alpha[i1] = alph1_new
self.alpha[i2] = alph2_new
self.b = b_new
self.E[i1] = self._E_(i1)
self.E[i2] = self._E_(i2)
def _predict_(self,feature):
result = self.b
for i in xrange(self.N):
result += self.alpha[i]*self.Y[i]*self._K_(feature,self.X[i])
if result > 0:
return 1
return -1
def predict(self,features):
results = []
for feature in features:
results.append(self._predict_(feature))
return results
if __name__ == "__main__":
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
print 'Start read data'
time_1 = time.time()
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
train_features, train_labels, test_features, test_labels = generate_dataset(2000,visualization=False)
time_2 = time.time()
print 'read data cost ',time_2 - time_1,' second','\n'
print 'Start training'
svm = SVM()
svm.train(train_features, train_labels)
time_3 = time.time()
print 'training cost ',time_3 - time_2,' second','\n'
print 'Start predicting'
test_predict = svm.predict(test_features)
time_4 = time.time()
print 'predicting cost ',time_4 - time_3,' second','\n'
score = accuracy_score(test_labels,test_predict)
print "svm1 the accruacy socre is ", score运行结果
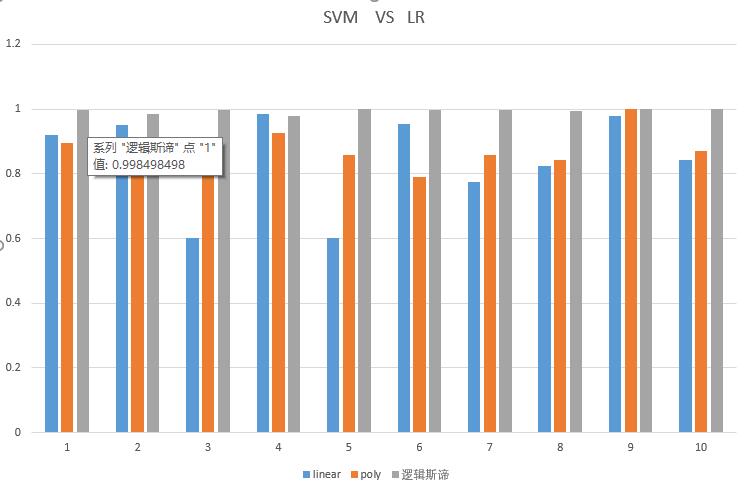
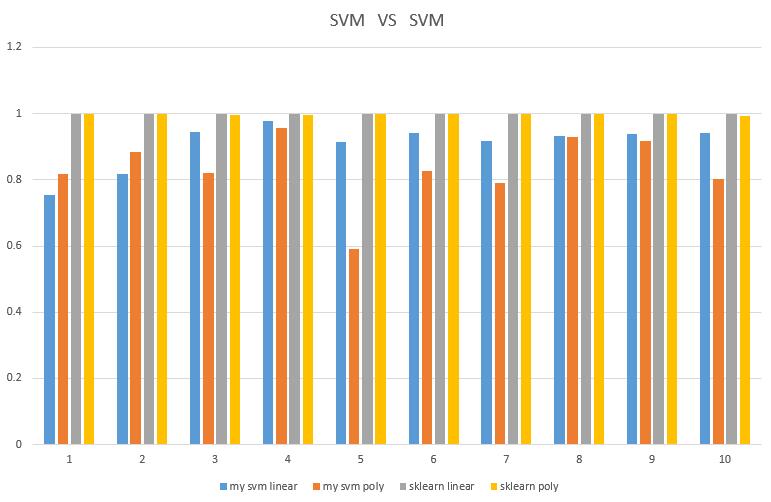
咱这SVM正确率确实一般,但丑媳妇总要见公婆,那么我们就拿我们的SVM与sklearn的SVM比较,再拿我们的SVM与我们自己的逻辑斯谛模型比较
我的SVM 与 sklearn 的SVM
这边对比线性内核linear与多项式内核poly,什么叫完爆啊,心酸!sklearn svm 的训练速度还比我的svm快很多,再次心酸!
我的SVM 与 我的逻辑斯谛模型
使用linear内核与poly内核对阵逻辑斯谛模型,再次被完爆,心酸!