版权声明:本文为博主原创文章,转载请附上链接出处。 https://blog.csdn.net/allen_li123/article/details/83796906
以前的博文介绍了Q-learning与DQN的相关知识与实例( https://blog.csdn.net/allen_li123/article/details/83621804)
Q-learning与DQN都属于基于值函数的深度强化学习,因为其输出都是关于动作的值,然后再根据 贪婪策略进行动作采取
但是如果动作是一个连续性动作,他的值函数不可能完全计算出来,而策略梯度可以很好的解决动作连续性问题(我也还没弄懂为什么可以解决,想明白了再更新)
策略梯度网络结构
输入结点为观测到的特征数与特征值
隐藏层根据实际情况进行更改
输出层为动作的数量,其值再经过softmax函数处理变为采取的概率值
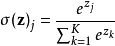
策略梯度网络权重的更新
神经网络都是根据误差函数来进行更新,而从严格意义上来讲,策略梯度算法是没有误差的,因为其输出只是选择的概率值,为了进行权重更新,我们将选取的动作的概率乘以一个变量作为损失函数,而该变量的取值取决于该动作的奖励收益
训练目标为损失函数最大化,这样就可以学习使奖励收益越来越大,而选取该奖励的概率也越来越大
策略梯度网络更新的时机
与基于值函数的深度强化学习算法不同,基于值函数的算法每一步都可以作为数据集进行学习,而策略梯度因为严格意义没有误差,所选取的误差函数必须在一回合结束后才能获得奖励值。
故策略梯度只能在回合结束时更新策略梯度网络。而每一步的选择都对网络有影响,故还需要用数组将所出现的状态,选取的动作,获得的奖励用数组储存起来,在回合结束时一并作为数据集经行网络更新
策略梯度动作的选择
与 贪婪策略不同,策略梯度输出的是动作采取的概率,故直接根据该概率对动作进行选取即可
action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel())
策略梯度概率更新幅度
代码如下:
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discounted_ep_rs[t] = running_add
# normalize episode rewards
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs)
return discounted_ep_rs
其中ep_rs代表每一步获得奖励,discounted_ep_rs代表每一步概率更新的幅度
最后
刚看完策略梯度,该算法因为没有采用 故极其容易陷入最优解。给我的感觉该算法有点像去除掉 的DQN。若有表述不对的地方再进行更正。
如有错误,敬请指正
.