1 Policy Gradient简介
1.1 基于策略和基于值的强化学习方法不同
强化学习是一个通过奖惩来学习正确行为的机制。家族中有很多种不一样的成员,有学习奖惩值,根据自己认为的高价值选行为,比如Q-Learning,Deep-Q-network,也有不通过分析奖惩值,直接输出行为的方法,这就是今天要说的Policy Gradient加上一个神经网络来输出预测的动作。对比起以值为基础的方法,Policy Gradient直接输出动作的最大好处就是,他能在一个连续区间内挑选动作,而基于值的,比如Q-Learning,它如果在无穷多得动作种计算价值,从而选择行为,这他可吃不消。
1.2 算法更新
有了神经网络当然方便,但是,我们怎么进行神经网络的误差反向传递呢?Policy Gradient的误差又是什么呢?答案是没有误差。但是他的确是在进行某一种的反向传递。这种反向传递的目的是让这次被选中的行为更有可能在下次发生。但是我们要怎么确定这个行为是不是应当被增加被选的概率呢?这时候,reward奖惩正可以在这个时候排上用场。
1.3 具体更新步骤
现在演示一遍,观测的信息通过神经网络分析,选出了左边的行为,我们直接进行反向传递,使之下次被选的可能性增加,但是奖惩信息却告诉我们,这次的行为是不好的,那我们的动作可能性增加的幅度随之被减低。这样就能靠奖励来左右我们的神经网络反向传递。我们再举一个例子,假如这次的观测信息让神经网络选择了右边的行为,右边的行为随之想要进行反向传递,使右边的行为下次被多选一点,这时,奖惩信息也来了,告诉我们这是好行为,那我们就在这次反向传递的时候加大力度,让他下次被多选的幅度更猛烈。这就是Policy Gradient的核心思想。
2 Policy Gradient算法更新
全部代码免费下载地址如下:
https://download.csdn.net/download/shoppingend/85194070
2.1 要点
Policy Gradient是RL中一个大家族,他不像Value-based方法(Q-Learning,Sarsa),但他也要接收环境信息(observation),不同的是他要输出不是action的value,而是具体的那一个action,这样Policy Gradient就跳过了value这个阶段。而且Policy Gradient最大的一个优势是:输出的这个action可以是一个连续的值,之前我们说到的value-based方法输出的都是不连续的值,然后再选择值最大的action。而Policy Gradient可以在一个连续分布上选取action。
2.2 算法
我们介绍最简单的Policy Gradient算法是一种基于整条回合数据的更新,也叫REINFORCE方法。这种方法是Policy Gradient的最基本方法,有了这个的基础,我们再来做更高级的。
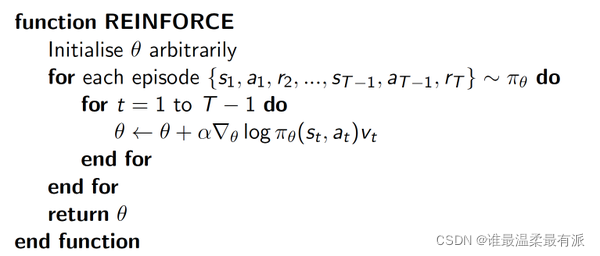
Δ(log(Policy(s,a))*V表示在状态s对所选动作a的吃惊度,如果Policy(s,a)概率越小,反向的log(Policy(s,a))(即-log§)反而越大。如果在Policy(s,a)很小的情况下,拿到了一个大的R,也就是大的V,那-Δ(log(Policy(s,a))*V就更大,表示更吃惊,(我选了一个不常选的动作,却发现原来它能得到了一个好的reward,那我就得对我这次的参数进行一个大幅修改)。这就是吃惊度的物理意义了。
2.3 算法代码形成
先定义主更新的循环:
import gym
from RL_brain import PolicyGradient
import matplotlib.pyplot as plt
RENDER = False # 在屏幕上显示模拟窗口会拖慢运行速度, 我们等计算机学得差不多了再显示模拟
DISPLAY_REWARD_THRESHOLD = 400 # 当 回合总 reward 大于 400 时显示模拟窗口
env = gym.make('CartPole-v0') # CartPole 这个模拟
env = env.unwrapped # 取消限制
env.seed(1) # 普通的 Policy gradient 方法, 使得回合的 variance 比较大, 所以我们选了一个好点的随机种子
print(env.action_space) # 显示可用 action
print(env.observation_space) # 显示可用 state 的 observation
print(env.observation_space.high) # 显示 observation 最高值
print(env.observation_space.low) # 显示 observation 最低值
# 定义
RL = PolicyGradient(
n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.02,
reward_decay=0.99, # gamma
# output_graph=True, # 输出 tensorboard 文件
)
主循环:
for i_episode in range(3000):
observation = env.reset()
while True:
if RENDER: env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
RL.store_transition(observation, action, reward) # 存储这一回合的 transition
if done:
ep_rs_sum = sum(RL.ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # 判断是否显示模拟
print("episode:", i_episode, " reward:", int(running_reward))
vt = RL.learn() # 学习, 输出 vt, 我们下节课讲这个 vt 的作用
if i_episode == 0:
plt.plot(vt) # plot 这个回合的 vt
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
break
observation = observation_
3 Policy Gradient思维决策
3.1 代码主结构
用基本的 Policy gradient 算法,和之前的 value-based 算法看上去很类似。
class PolicyGradient:
# 初始化 (有改变)
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False):
# 建立 policy gradient 神经网络 (有改变)
def _build_net(self):
# 选行为 (有改变)
def choose_action(self, observation):
# 存储回合 transition (有改变)
def store_transition(self, s, a, r):
# 学习更新参数 (有改变)
def learn(self, s, a, r, s_):
# 衰减回合的 reward (新内容)
def _discount_and_norm_rewards(self):
初始化:
class PolicyGradient:
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate # 学习率
self.gamma = reward_decay # reward 递减率
self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # 这是我们存储 回合信息的 list
self._build_net() # 建立 policy 神经网络
self.sess = tf.Session()
if output_graph: # 是否输出 tensorboard 文件
# $ tensorboard --logdir=logs
# http://0.0.0.0:6006/
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
3.2 建立Policy神经网络
这次我们要建立的神经网络是这样的:
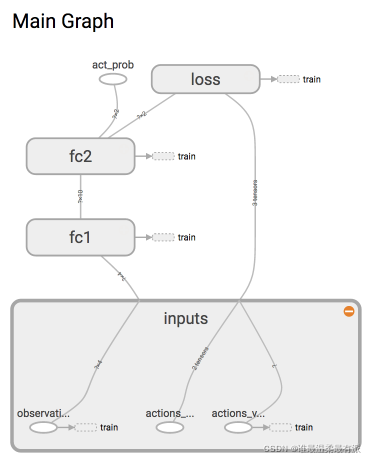
因为这是强化学习,所以神经网络中没有监督学习中的y label。取而代之的是我们选的action。
class PolicyGradient:
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False):
...
def _build_net(self):
with tf.name_scope('inputs'):
self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations") # 接收 observation
self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num") # 接收我们在这个回合中选过的 actions
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value") # 接收每个 state-action 所对应的 value (通过 reward 计算)
# fc1
layer = tf.layers.dense(
inputs=self.tf_obs,
units=10, # 输出个数
activation=tf.nn.tanh, # 激励函数
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc1'
)
# fc2
all_act = tf.layers.dense(
inputs=layer,
units=self.n_actions, # 输出个数
activation=None, # 之后再加 Softmax
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc2'
)
self.all_act_prob = tf.nn.softmax(all_act, name='act_prob') # 激励函数 softmax 出概率
with tf.name_scope('loss'):
# 最大化 总体 reward (log_p * R) 就是在最小化 -(log_p * R), 而 tf 的功能里只有最小化 loss
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # 所选 action 的概率 -log 值
# 下面的方式是一样的:
# neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # (vt = 本reward + 衰减的未来reward) 引导参数的梯度下降
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
为什么使用loss=-log(prob)*Vt当作loss。简单来说,上面提到了两种行式来计算neg_log_prob,这两种行式是一摸一样的,只是第二个是第一个的展开行式。如果仔细看第一个行式,就是在神经网络分类问题中的cross-entropy。使用softmax和神经网络的参数按照这个真实标签改进。这显然和一个分类问题没有太多的区别,我们能将这个neg_log_prob理解成cross-entropy的分类误差。分类问题中的标签是真实x对应的y,而我们Policy Gradient中,x是state,y就是它按照这个x所做的动作号码。所以也可以理解成,它按照x做的动作永远是对的(出来的动作永远是正确标签,他也永远会按照这个正确标签修改自己的参数。可是事实并不是这样,他的动作不一定都是正确标签,这就是强化学习(Policy Gradient)和监督学习(classification)的区别。
为了确保这个动作是正确标签,我们的loss在原本的cross-entropy行式上乘以Vt,用Vt来告诉这个cross-entropy算出来的梯度是不是一个值得信赖的梯度。如果Vt小,或者是负的,就说明这个梯度下降是一个错误的方向,我们应该向着另一个方向更新参数,如果这个Vt是正的,或很大,Vt就会称赞cross-entropy出来的梯度,并朝着这个方向梯度下降。下面有一张图,也正是阐述的这个思想。
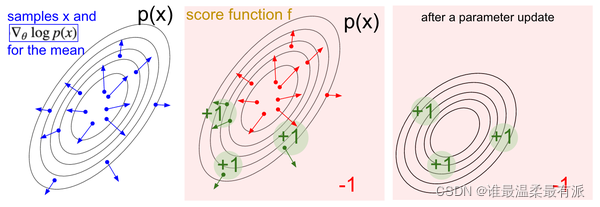
而为什么是loss=-log(prob)Vt而不是loss=-probVt。原因是这里的prob是从softmax出来的,而计算神经网络里的所有参数梯度,使用到的就是cross-entropy,然后将这个梯度乘以Vt来控制梯度下降的方向和力度。
3.3 选行为
这个行为不再是用Q-value来选定的,而是用概率来决定。即使不用epsilon-greedy,也具有一定的随机性。
class PolicyGradient:
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False):
...
def _build_net(self):
...
def choose_action(self, observation):
prob_weights = self.sess.run(self.all_act_prob, feed_dict={
self.tf_obs: observation[np.newaxis, :]}) # 所有 action 的概率
action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # 根据概率来选 action
return action
3.4 存储回合
这一部分就是将这一步的observation,action,reward加到列表中去。因为本回合完毕之后要清空列表,然后存储下一回合的数据,所以我们会在learn()当中进行清空列表的动作
class PolicyGradient:
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False):
...
def _build_net(self):
...
def choose_action(self, observation):
...
def store_transition(self, s, a, r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
3.5 学习
本节的learn()很简单首先我们要对这回合的所有的reawrd动动手脚,使得它变得更适合被学习。第一就是随着时间推进,用γ衰减未来的reward,然后为了一定程度上减小Policy Gradient回合variance。
class PolicyGradient:
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False):
...
def _build_net(self):
...
def choose_action(self, observation):
...
def store_transition(self, s, a, r):
...
def learn(self):
# 衰减, 并标准化这回合的 reward
discounted_ep_rs_norm = self._discount_and_norm_rewards() # 功能再面
# train on episode
self.sess.run(self.train_op, feed_dict={
self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs]
self.tf_acts: np.array(self.ep_as), # shape=[None, ]
self.tf_vt: discounted_ep_rs_norm, # shape=[None, ]
})
self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # 清空回合 data
return discounted_ep_rs_norm # 返回这一回合的 state-action value
再看discounted_ep_rs_norm
vt = RL.learn() # 学习, 输出 vt, 我们下节课讲这个 vt 的作用
if i_episode == 0:
plt.plot(vt) # plot 这个回合的 vt
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
最后使如何用算法实现对未来reward的衰减
class PolicyGradient:
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False):
...
def _build_net(self):
...
def choose_action(self, observation):
...
def store_transition(self, s, a, r):
...
def learn(self):
...
def _discount_and_norm_rewards(self):
# discount episode rewards
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discounted_ep_rs[t] = running_add
# normalize episode rewards
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs)
return discounted_ep_rs
文章来源:莫凡强化学习https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/