本文内容源自百度强化学习 7 日入门课程学习整理
感谢百度 PARL 团队李科浇老师的课程讲解
强化学习算法 DQN 解决 CartPole 问题,移动小车使得车上的摆杆保持直立。
-
这个游戏环境可以说是强化学习中的 “Hello World”
-
大部分的算法都可以先利用这个环境来测试下是否可以收敛
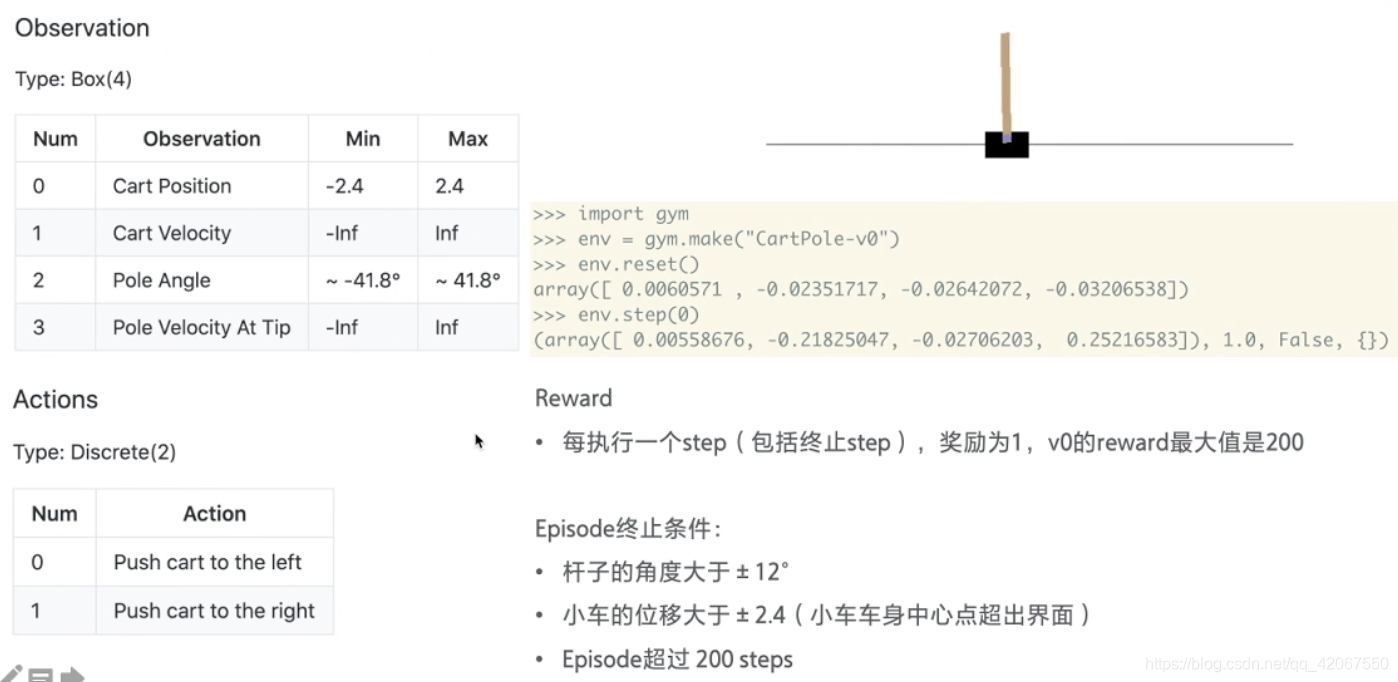
环境介绍:
小车在一个导轨上,无摩擦地来回移动,车上有一根杆子,可以绕着小车上的一个点旋转,所以我们要做的是,通过推动小车往左或者往右,来确保杆子不倒
终止条件:
- 杆子角度大于 +/-12度
- 车子位移大于 +/-2.4(车子移出了界面外)
- Episode 超出 200 steps
奖励:
- 每执行一个 step 拿到 1分
- 所以最高是 200 分
环境重置 env.reset()
- 返回状态值:[小车的位置,小车的速度,杆子的角度,杆子顶端的速度]
每走一步 env.step(0)
- 返回:[当前状态,奖励,是否结束]
一、安装依赖
!pip install gym
!pip install paddlepaddle==1.6.3
!pip install parl==1.3.1
检查版本是否正确:
# 检查依赖包版本是否正确
!pip list | grep paddlepaddle
!pip list | grep parl
二、导入依赖
import os
import gym
import numpy as np
import paddle.fluid as fluid
import parl
from parl import layers
from parl.utils import logger
三、设置超参数
LEARNING_RATE = 1e-3 # 0.001
四、搭建Model、Algorithm、Agent架构
Agent把产生的数据传给algorithm,algorithm根据model的模型结构计算出Loss,使用SGD或者其他优化器不断的优化,PARL这种架构可以很方便的应用在各类深度强化学习问题中。
4.1 Model
Model用来定义前向(Forward)网络,用户可以自由的定制自己的网络结构。
class Model(parl.Model):
def __init__(self, act_dim):
act_dim = act_dim # 动作维度
hid1_size = act_dim * 10 # 节点数量设置为 动作维度 的 10 倍
self.fc1 = layers.fc(size=hid1_size, act='tanh') # 隐藏层用 “tanh” 作为激活(输出 -1~1)
self.fc2 = layers.fc(size=act_dim, act='softmax') # 输出层用 softmax,即不同动作的概率
def forward(self, obs): # 可直接用 model = Model(5); model(obs)调用
out = self.fc1(obs)
out = self.fc2(out)
return out
4.2 Algorithm
Algorithm 定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。
# from parl.algorithms import PolicyGradient # 也可以直接从parl库中导入PolicyGradient算法,无需重复写算法
class PolicyGradient(parl.Algorithm):
def __init__(self, model, lr=None):
""" Policy Gradient algorithm
Args:
model (parl.Model): policy的前向网络.
lr (float): 学习率.
"""
self.model = model # 传入模型
assert isinstance(lr, float) # 判定变量类型
self.lr = lr # 赋值
def predict(self, obs):
""" 使用policy model预测输出的动作概率
"""
return self.model(obs) # 输入状态,输出各种动作的执行概率
def learn(self, obs, action, reward):
""" 用policy gradient 算法更新policy model
"""
act_prob = self.model(obs) # 获取输出动作概率
# log_prob = layers.cross_entropy(act_prob, action) # 交叉熵
# 这里要用交叉熵作为损失函数
# 下面这个没有直接调用,而是用了原始的交叉熵的计算公式
log_prob = layers.reduce_sum(
-1.0 * layers.log(act_prob) * layers.one_hot( # 要转成 one-hot 向量
action, act_prob.shape[1]),
dim=1)
cost = log_prob * reward # 乘以 reward(未来总收益)
cost = layers.reduce_mean(cost) # 求每一步的均值
optimizer = fluid.optimizer.Adam(self.lr) # 使用 Adam 优化器
optimizer.minimize(cost) # 优化,最小化 cost,即让最优 action 选择的概率逼近 1
return cost
4.3 Agent
Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。
class Agent(parl.Agent):
def __init__(self, algorithm, obs_dim, act_dim):
self.obs_dim = obs_dim
self.act_dim = act_dim
super(Agent, self).__init__(algorithm)
def build_program(self):
self.pred_program = fluid.Program()
self.learn_program = fluid.Program()
with fluid.program_guard(self.pred_program): # 搭建计算图用于 预测动作,定义输入输出变量
# 这个计算图中,obs 为输入
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
# 动作的概率为输出
self.act_prob = self.alg.predict(obs)
with fluid.program_guard(
self.learn_program): # 搭建计算图用于 更新policy网络,定义输入输出变量
# 这个计算图中,当前状态 obs ,选择的动作 action,获得的奖励 reward 为输入
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
act = layers.data(name='act', shape=[1], dtype='int64')
reward = layers.data(name='reward', shape=[], dtype='float32')
# 代价函数计算的损失 为输出
self.cost = self.alg.learn(obs, act, reward)
def sample(self, obs):
obs = np.expand_dims(obs, axis=0) # 增加一维维度,这是由于这里程序以 batch 输入,单条数据需要增加一个维度
# 执行计算图,获得动作概率
act_prob = self.fluid_executor.run(
self.pred_program, # 输入搭建的计算图
feed={'obs': obs.astype('float32')}, # 输入的数据
fetch_list=[self.act_prob])[0] # 最后的取值
act_prob = np.squeeze(act_prob, axis=0) # 同样,程序的输出数据格式,也需要减少一维维度
act = np.random.choice(range(self.act_dim), p=act_prob) # 根据动作概率选取动作
return act # 概率越高的动作越可能被选到
def predict(self, obs):
obs = np.expand_dims(obs, axis=0)
act_prob = self.fluid_executor.run(
self.pred_program,
feed={'obs': obs.astype('float32')},
fetch_list=[self.act_prob])[0]
act_prob = np.squeeze(act_prob, axis=0)
act = np.argmax(act_prob) # 根据动作概率选择概率最高的动作
# 这个要看具体问题,如果是确定性高的问题,比如这里的 CarPole问题,就可以选择确定性高的最高概率动作
return act # 只选择概率最高的动作
def learn(self, obs, act, reward):
act = np.expand_dims(act, axis=-1) #
# 指定输入数据及其类型
feed = {
'obs': obs.astype('float32'),
'act': act.astype('int64'),
'reward': reward.astype('float32')
}
# 运行学习程序,并获取 cost
cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.cost])[0]
return cost
五、Training && Test(训练&&测试)
def run_episode(env, agent):
obs_list, action_list, reward_list = [], [], [] # 初始化 3 个空的列表
obs = env.reset() # 重置环境,获得最初的状态 obs
while True:
obs_list.append(obs) # 为状态列表添加状态
action = agent.sample(obs) # 采样动作
action_list.append(action) # 为动作列表添加动作
obs, reward, done, info = env.step(action) # 执行一次交互
reward_list.append(reward) # 为奖励列表添加得到的奖励
if done:
break
return obs_list, action_list, reward_list
# 评估 agent, 跑 5 个episode,总reward求平均
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs) # 选取最优动作
obs, reward, isOver, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if isOver:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
六、创建环境和Agent,启动训练,保存模型
# 根据一个episode的每个step的reward列表,计算每一个Step的Gt
def calc_reward_to_go(reward_list, gamma=1.0):
for i in range(len(reward_list) - 2, -1, -1):
# G_t = r_t + γ·r_t+1 + ... = r_t + γ·G_t+1
reward_list[i] += gamma * reward_list[i + 1] # 逆向方式求每一步 step 的未来总收益
return np.array(reward_list)
# 创建环境
env = gym.make('CartPole-v0') # 使用 gym 库创建环境
obs_dim = env.observation_space.shape[0] # 获取环境状态维度
act_dim = env.action_space.n # 获取动作维度
logger.info('obs_dim {}, act_dim {}'.format(obs_dim, act_dim)) # 打印 log 信息
# 根据parl框架构建agent
model = Model(act_dim=act_dim) # model 实例化
alg = PolicyGradient(model, lr=LEARNING_RATE) # 算法实例化
agent = Agent(alg, obs_dim=obs_dim, act_dim=act_dim) # agent 实例化,传入了 实例化的 alg 作为参数
# 加载模型
# if os.path.exists('./model.ckpt'):
# agent.restore('./model.ckpt')
# run_episode(env, agent, train_or_test='test', render=True)
# exit()
for i in range(1000):
obs_list, action_list, reward_list = run_episode(env, agent) # 每个 episode 记录下 3 个列表
if i % 10 == 0: # 每 10 局打印一下 log
logger.info("Episode {}, Reward Sum {}.".format(
i, sum(reward_list)))
batch_obs = np.array(obs_list) # 转化为 numpy 数组
batch_action = np.array(action_list)
batch_reward = calc_reward_to_go(reward_list) # 调用函数,把单步的收益转化为该步的未来总收益
agent.learn(batch_obs, batch_action, batch_reward) # 获得一整个 episode 的数据后,学习一次
if (i + 1) % 100 == 0: # 每 100 局测试一下
total_reward = evaluate(env, agent, render=False) # render=True 查看渲染效果
# 这里设定评估 5 个 episode 取平均结果
logger.info('Test reward: {}'.format(total_reward))
# 保存模型到文件 ./model.ckpt
agent.save('./model.ckpt')