基于policy gradient的强化学习算法相比于value function方法的优缺点:
优点:
- 直接策略搜索是对策略进行参数化表示,与值函数相比,策略化参数的方法更简单,更容易收敛。
- 值函数的放法无法解决状态空间过大或者不连续的情形
- 直接策略的方法可以采取随机策略,随机策略可以将探索直接集成到算法当中
缺点:
- 策略搜索的方法更容易收敛局部极值点
- 在评估单个策略时,评估的并不好,方差容易过大
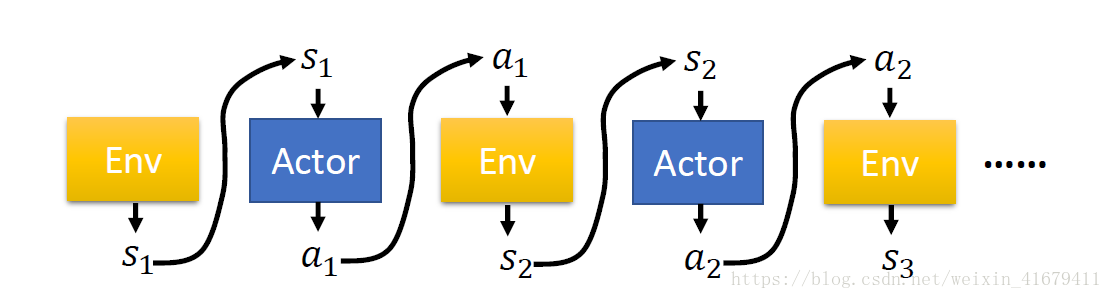
上图是一个完整的MDP过程对于一个完整的采样轨迹
。
于是有
其中
是策略的参数,一个策略完全由其参数决定。在实际应用中,这种关系是由神经网路刻画的。
在定义了一条采样轨迹的概率之后,我们来定义期望回报:
过程如图所示:
得到期望回报关于策略的表达式之后,我们的目标变得非常明确了,我们只需要优化这个函数,使之最大化即可。我们可以使用最常用的梯度下降的方法。
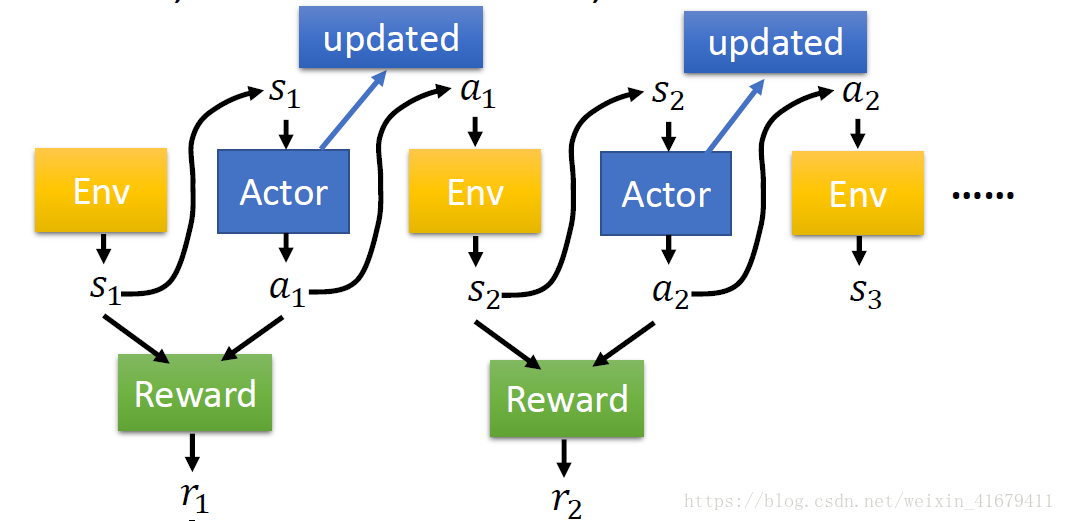
Deterministic Policy Optimization 相比于 Stochastic Policy Optimization 有三个优势:
- value estimate from on-policy samples have lower variance (zero when the system dynamics is deterministic)
- it is possible to write the policy gradient in a simpler form which makes it computationally more attractive.
- in some cases, stochastic policy can lead to poor and unpredictable performance
On the contrary, a deterministic policy gradient method requires a good exploration strategy since, unlike stochastic policy gradient, it has no clear rule for exploring the state space. In addition, stochastic policy gradient methods tend to solve more broad classes of problems from our experience.
We suspect that this is due to the fact that stochastic policy gradient has less local optima that are present in deterministic policy gradient.
Reference:
https://blog.csdn.net/weixin_41679411/article/details/82414400