本篇文章主旨不在从头讲述PG,而是通过综合别人的总结,写出自己的理解。按照指出的这些引用,消除那些疑惑的地方。
首先放一张图,先明确强化学习中有哪些方法,策略梯度又处在怎样的位置。
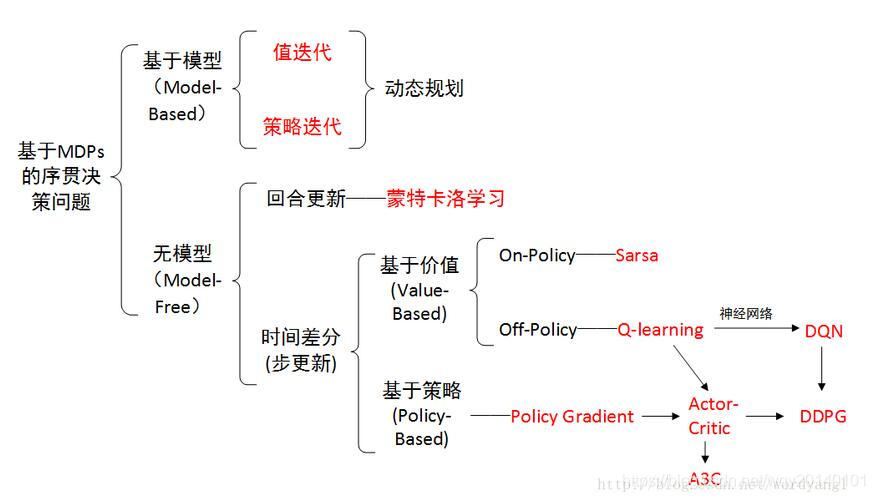 On-line代表,agent必须和环境交互,一边选取动作一遍学习;Off-line代表,agent既可以直接与环境交互进行学习,也可以从别人的经验里学习。
On-line代表,agent必须和环境交互,一边选取动作一遍学习;Off-line代表,agent既可以直接与环境交互进行学习,也可以从别人的经验里学习。
基础&入门了解PG:https://www.cnblogs.com/pinard/p/10137696.html
刘老师的博客我经常看,我认为是很好的教程,无论是从入门角度还是从解开一些疑惑。下面, 针对博客内容我总结一些自己的理解。
梯度策略的优化目标推导(随后有时间证明)
蒙特卡罗策略梯度reinforce算法.
- 作者github代码:PG实现,发现作者的实现思路基本是,先根据网络结果选动作,进行蒙特卡洛采样以获得一个完整的episode,即具有序列时间步的(s,a,r);利用(s,a)作为训练数据,训练三层的神经网络,神经网络的最后一层是softmax函数。损失函数设置为交叉熵损失(s状态下真实动作a和网络预测动作a的差距)和价值函数(在一个episode中,每个时间步状态的值函数)的乘积。由于tensorflow内部自行实现了梯度下降,故我们不再考虑。强调一下,作者用状态值函数近似地代替了动作值函数。
- 理解tf.nn.sparse_softmax_cross_entropy_with_logits函数的计算过程。简单说,就是先对网络输出通过softmax即类别的概率分布,接着根据分类维度将正确标签转换为one-hot向量,最后计算交叉熵。
- 理解tf.reduce_mean(self.neg_log_prob * self.tf_vt) : 比如一个episode有100个state-action对(100个样本),action有两种,那么网络输出就是[100,2]的张量,对应[batch_size, num_class],通过交叉熵,得到正确标签的损失[100,1],将提前算好的价值函数v(一个状态对应一个价值函数),价值函数也是[100,1]的,对应位置相乘,再求各个样本的loss总和,之后求平均(也就是将100个样本看作是一个batch,一次性送入网络求其平均loss,不再关注当前样本是位于该batch的第几个),结果看作该episode最终的loss值。
- 第三部分:策略梯度目标函数的设计,明明提到了优化目标是求期望,为什么在描述算法的时候,没有任何体现期望的地方?这是因为,代码中,每个episode生成后,都要根据产生的state-action对更新网络。之前的期望是对于所有采样的episode而言的,现在是一个episode,也就可以把期望符号给去掉了。这个地方同时可以参看PG,AC,A3C原理介绍。 该博文是介绍的将期望转换为求平均,由于我们一次一更新,因此也就把取平均这一步给去掉了。
- 第三部分:策略梯度目标函数的设计,分析得出需要最大化获得的奖励,包括第五部分算法实现伪代码也是梯度上升算法,为何到了github中,变成了最小化损失函数?这里的策略π,用的是最后一层为softmax的三层神经网络。代码中用到tf.nn.sparse_softmax_cross_entropy_with_logits函数。该函数先计算当前state下的action的概率分布,随后使用交叉熵计算loss损失。从交叉熵的定义来看,恰好包含了log函数的计算,也就是说,该函数完成了计算logπ的功能。并且,交叉熵损失本身带负号,因此现在的问题变成了求最小,即梯度下降问题。
- 第四部分列举了对策略π求导后的形式,而且都是先计算logπ的梯度,再与价值函数v相乘。代码中变成了,先与v相乘,再求梯度。这样是一致的吗?可以看出,v我们是单独计算的,与网络参数无关,因此是先乘v再对网络参数求梯度,还是说先求梯度再乘以v,都是等价的。
