强化学习有三个组成部分:演员,环境和奖励函数,
演员是我们的智能体,环境就是对手,奖励就是没走出一步环境给我们的reward,环境和奖励是我们无法控制的,但是我们可以调整演员的策略,演员的策略决定了演员的动作,即给定一个输入,它会输出演员现在应该要执行的动作。
策略梯度(Policy gradient,PG)
策略一般记作 π \pi π,我们一般用网络来表示策略,网络中有一些参数,我们用 θ \theta θ 来表示网络 π \pi π 中的参数。
如果我们以游戏为例,游戏初始的画面可以记作是 s 1 s_1 s1 , 第一次执行的动作时 a 1 a_1 a1 ,第一次执行动作后得到的奖励是 r 1 r_1 r1 然后我们就进入到了第二个画面,这个时候我们的画面可以记作 s 2 s_2 s2 ,第二次执行的动作时 a 2 a_2 a2 ,第二次执行动作后得到的奖励是 r 2 r_2 r2…
什么时候结束呢?当游戏结束,也就是你打败了最终boss或者你中途失败了,这就结束了。
下面这张图可以很形象的说明上述的过程
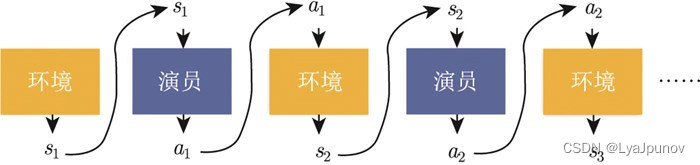
首先环境是一个函数,这个函数可能是基于规则的模型,但是我们可以认为他是一个函数,这个函数一开始产生一个状态 s 1 s_1 s1,然后我们的演员根据这个状态生成相应的动作 a 1 a_1 a1 给环境,环境在生成状态 s 2 s_2 s2 … 这个循环一直到环境认为该结束了,在一场游戏中,我们把环境和状态全部组合起来就形成了一条轨迹 τ \tau τ
τ = { s 1 , a 1 , s 2 , a 2 , . . . , s t , a t } \tau = \{s_1,a_1,s_2,a_2,...,s_t,a_t\} τ={
s1,a1,s2,a2,...,st,at}
给定演员的参数 θ \theta θ ,我们可以计算出某条轨迹发生的概率
p θ ( τ ) = p ( s 1 ) p θ ( a 1 ∣ s 1 ) p ( s 2 ∣ s 1 , a 1 ) p θ ( a 2 ∣ s 2 ) p ( s 3 ∣ s 2 , a 2 ) . . . = p ( s 1 ) ∏ t = 1 T p θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) \begin{align} p_\theta(\tau) &= p(s_1)p_\theta(a_1|s_1)p(s_2|s_1,a_1)p_\theta(a_2|s_2)p(s_3|s_2,a_2)...\notag\\ &=p(s_1) \prod_{t=1}^{T}p_\theta(a_t|s_t)p(s_{t+1}|s_t,a_t)\notag \end{align} pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣s1,a1)pθ(a2∣s2)p(s3∣s2,a2)...=p(s1)t=1∏Tpθ(at∣st)p(st+1∣st,at)
某条轨迹出现的概率取决于环境的动作和智能体的动作。环境的动作是指环境根据其函数内部的参数或内部的规则采取的动作。 p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p(st+1∣st,at) 代表的是环境,因为环境是设定好的,所以通常我们无法控制环境,能控制的是 p θ ( a t ∣ s t ) p_\theta(a_t|s_t) pθ(at∣st) 。给定一个 s t s_t st 演员要采取的 a t a_t at取决于演员的参数 θ \theta θ所以智能体的动作是演员可以控制的。演员的动作不同,每个同样的轨迹就有不同的出现的概率。
一场游戏称为一个回合,这场游戏中所有的奖励都加起来就称为总奖励(total reward),也就是回报,我们用 R R R 来表示它,演员要想办法把所能得到的回报最大化,我们把轨迹的所有奖励都加起来就得到了 R ( τ ) R(\tau) R(τ) 代表某一条轨迹 τ \tau τ 的奖励。
R ( τ ) = ∑ t = 1 T r t R(\tau) = \sum_{t=1}^{T}r_t R(τ)=t=1∑Trt
在某一场游戏中,得到 R ( τ ) R(\tau) R(τ) 后,我们希望调整演员内部的参数 θ \theta θ ,使得 R ( τ ) R(\tau) R(τ) 越大越好,但是 R ( τ ) R(\tau) R(τ) 并不是一个标量,他是一个随机变量,因为演员即使是在相同的状态输入下,他也可能会有不同的输出动作,具有一定的随机性,我们可以计算的是 R ( τ ) R(\tau) R(τ) 的期望值,给定某一组参数 θ \theta θ, R θ R_\theta Rθ的期望值可以是
R ˉ θ = ∑ τ R ( τ ) p θ ( τ ) \bar R_\theta = \sum_{\tau} R(\tau) p_\theta(\tau) Rˉθ=τ∑R(τ)pθ(τ)
我们要穷举所有可能的轨迹 τ \tau τ ,每一条轨迹都有一个概率,比如 θ \theta θ 对应的模型很强,如果有一个回合 θ \theta θ 很快就死掉了,因为这种情况很少发生,所以该回合对应的轨迹 τ \tau τ 的概率就很小,我们可以根据 θ \theta θ 算出某一条轨迹出现的概率,接下来计算 τ \tau τ 的总奖励。总奖励使用 τ \tau τ 出现的概率进行加权,对所有的 τ \tau τ 进行求和,就是期望值,给定一个参数,我们可以计算期望值为
R ˉ θ = ∑ τ R ( τ ) p θ ( τ ) = E τ ∼ p θ ( τ ) [ R ( τ ) ] \bar R_\theta = \sum_{\tau} R(\tau) p_\theta(\tau) = \mathbb E_{\tau \sim p_\theta(\tau)}[R(\tau)] Rˉθ=τ∑R(τ)pθ(τ)=Eτ∼pθ(τ)[R(τ)]
从分布 p θ ( τ ) p_\theta(\tau) pθ(τ) 采样一条轨迹 τ \tau τ ,计算 R ( τ ) R(\tau) R(τ) 的期望值,就是期望奖励(expected reward)。我们要最大化期望奖励,要进行梯度上升,我们先要计算期望奖励 R ˉ θ \bar R_\theta Rˉθ 的梯度
∇ R ˉ θ = ∇ ∑ τ R ( τ ) p θ ( τ ) = ∑ τ R ( τ ) ∇ p θ ( τ ) \begin{align} \nabla \bar R_\theta &= \nabla \sum_{\tau} R(\tau) p_\theta(\tau) \notag\\ &= \sum_{\tau} R(\tau) \nabla p_\theta(\tau) \notag\\ \end{align} ∇Rˉθ=∇τ∑R(τ)pθ(τ)=τ∑R(τ)∇pθ(τ)
只有 p θ ( τ ) p_\theta(\tau) pθ(τ)与 θ \theta θ 有关,奖励函数 R ( τ ) R(\tau) R(τ) 并不需要是可微分的,这不影响我们解决下面的问题,这里我们需要用到一个公式
Remark1
∇ f ( x ) = f ( x ) ∇ l o g f ( x ) \nabla f(x) = f(x) \nabla log \ f(x) ∇f(x)=f(x)∇log f(x)
所以我们接着上面的继续推导
∇ R ˉ θ = ∇ ∑ τ R ( τ ) p θ ( τ ) = ∑ τ R ( τ ) ∇ p θ ( τ ) = ∑ τ R ( τ ) p θ ( τ ) ∇ l o g p θ ( τ ) = E τ ∼ p θ ( τ ) [ R ( τ ) ∇ l o g p θ ( τ ) ] \begin{align} \nabla \bar R_\theta &= \nabla \sum_{\tau} R(\tau) p_\theta(\tau) \notag\\ &= \sum_{\tau} R(\tau) \nabla p_\theta(\tau)\notag \\ &= \sum_{\tau} R(\tau) p_\theta(\tau) \nabla log \ p_\theta(\tau)\notag \\ &= \mathbb E_{\tau \sim p_\theta(\tau)}[R(\tau) \nabla log \ p_\theta(\tau)]\notag \end{align} ∇Rˉθ=∇τ∑R(τ)pθ(τ)=τ∑R(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)∇log pθ(τ)=Eτ∼pθ(τ)[R(τ)∇log pθ(τ)]
实际期望值是无法计算的,所以我们用采样的方式采样N个 τ \tau τ 并计算每一个值,把没一个值都加起来,可以得到梯度。
∇ R ˉ θ ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ l o g p θ ( τ n ) = 1 N ∑ n = 1 N R ( τ n ) ∇ ( l o g p ( s 1 ) + ∑ t = 1 T l o g p θ ( a t ∣ s t ) + ∑ t = 1 T l o g p ( s t + 1 ∣ a t , s t ) ) = 1 N ∑ n = 1 N R ( τ n ) ( ∇ l o g p ( s 1 ) + ∇ ∑ t = 1 T l o g p θ ( a t ∣ s t ) + ∇ ∑ t = 1 T l o g p ( s t + 1 ∣ a t , s t ) ) = 1 N ∑ n = 1 N R ( τ n ) ( ∇ ∑ t = 1 T l o g p θ ( a t ∣ s t ) ) = 1 N ∑ n = 1 N R ( τ n ) ( ∑ t = 1 T ∇ l o g p θ ( a t ∣ s t ) ) = 1 N ∑ t = 1 T ∑ n = 1 N R ( τ n ) ∇ l o g p θ ( a t n ∣ s t n ) \begin{align} \nabla \bar R_\theta &\approx \frac {1} {N} \sum_{n=1}^{N} R(\tau ^ {n}) \nabla log \ p_\theta(\tau^{n}) \notag\\ &= \frac {1} {N} \sum_{n=1}^{N} R(\tau ^ {n}) \nabla \left( log \ p(s_1) + \sum_{t=1}^{T}log \ p_\theta(a_t | s_t) + \sum_{t=1}^{T}log \ p_(s_{t+1}|a_t,s_t) \right)\notag \\ &= \frac {1} {N} \sum_{n=1}^{N} R(\tau ^ {n}) \left( \nabla log \ p(s_1) + \nabla \sum_{t=1}^{T}log \ p_\theta(a_t | s_t) + \nabla \sum_{t=1}^{T}log \ p_(s_{t+1}|a_t,s_t) \right) \notag\\ &= \frac {1} {N} \sum_{n=1}^{N} R(\tau ^ {n}) \left( \nabla \sum_{t=1}^{T}log \ p_\theta(a_t | s_t) \right) \notag\\ &= \frac {1} {N} \sum_{n=1}^{N} R(\tau ^ {n}) \left(\sum_{t=1}^{T} \nabla log \ p_\theta(a_t | s_t) \right)\notag \\ &= \frac {1} {N}\sum_{t=1}^{T} \sum_{n=1}^{N} R(\tau ^ {n}) \nabla log \ p_\theta(a_t^n | s_t^n)\notag \\ \end{align} ∇Rˉθ≈N1n=1∑NR(τn)∇log pθ(τn)=N1n=1∑NR(τn)∇(log p(s1)+t=1∑Tlog pθ(at∣st)+t=1∑Tlog p(st+1∣at,st))=N1n=1∑NR(τn)(∇log p(s1)+∇t=1∑Tlog pθ(at∣st)+∇t=1∑Tlog p(st+1∣at,st))=N1n=1∑NR(τn)(∇t=1∑Tlog pθ(at∣st))=N1n=1∑NR(τn)(t=1∑T∇log pθ(at∣st))=N1t=1∑Tn=1∑NR(τn)∇log pθ(atn∣stn)
上面有两项 ∇ l o g p ( s 1 ) \nabla log \ p(s_1) ∇log p(s1) 和 $\sum_{t=1}^{T}log \ p_(s_{t+1}|a_t,s_t) $ 直接就没了,这里需要解释一下,因为我们这里求梯度是对智能体的参数求梯度,也就是对 θ \theta θ 求梯度,这两个值都来自环境,或者也可以说这两个概率中不含 θ \theta θ ,所以他们的梯度就是0。
我们可以直观的理解我们上面推导出来的等式,也就是在采样的过程中,我们采样到了一对数据 ( s t , a t ) (s_t,a_t) (st,at) ,如果我们整条轨迹 τ \tau τ 最终得到的奖励和是正的,那么我们就要强化在状态 s t s_t st 采取动作 a t a_t at 的概率,反之我们就要减小这种概率。
我们已经计算出了梯度,下面的就是将这个梯度用梯度上升的方法更新我们的网络。
我们讲的再详细一点
我们会采集n条轨迹分别为 τ 1 , τ 2 , . . . , τ n \tau^1,\tau^2,...,\tau^n τ1,τ2,...,τn ,这n条轨迹包含一些状态对,比如第一条轨迹包含状态对 { ( s 1 1 , a 1 1 ) , ( s 2 1 , a 2 1 ) , . . . , ( s m 1 1 , a m 1 1 , } \{(s_1^1,a_1^1),(s_2^1,a_2^1),...,(s_{m_1}^1,a_{m_1}^1,\} {(s11,a11),(s21,a21),...,(sm11,am11,} ,第二条轨迹包含状态对 { ( s 1 2 , a 1 2 ) , ( s 2 2 , a 2 2 ) , . . . , ( s m 2 2 , a m 2 2 , } \{(s_1^2,a_1^2),(s_2^2,a_2^2),...,(s_{m_2}^2,a_{m_2}^2,\} {(s12,a12),(s22,a22),...,(sm22,am22,} ,并且他们奖励为 R ( τ 1 ) , R ( τ 2 ) , . . . , R ( τ n ) R(\tau^1),R(\tau^2),...,R(\tau^n) R(τ1),R(τ2),...,R(τn)这时我们就可以将采样到的数据带入公式计算出梯度,也就是把每一个 s s s 与 a a a 拿出来,计算在某个状态下采取某个动作的对数概率,在概率前乘以一个权重(就是这场游戏的奖励),计算出梯度后就可以更新模型。
更新完模型以后,要重新采样数据再更新模型。注意,一般**策略梯度(policy gradient,PG)**采样的数据只会用一次。我们采样这些数据,然后用这些数据更新参数,再丢掉这些数据。接着重新采样数据,才能去更新参数。
策略梯度优化策略
添加基线(baseline)
给定状态采取动作,如果这个动作得到的奖励是正的,我们就要鼓励这种行为,要增加这种概率,如果这个动作得到的奖励是负的,我们就要减小这种概率,可是有些游戏得到的奖励全是正的,采取某些动作得到的奖励是0,采取某些动作得到的奖励是20。
假设我们有三个动作a,b,c,我们要把这三个动作的概率都提高,但是他们前面的权重 R ( τ ) R(\tau) R(τ) 是不一样的,权重是有大有小的,权重小的,该动作的概率提高的就少,权重大的,该动作的概率提升的就多,因为对数概率也是概率,其最后还是经过了一个softmax层进行输出,所以即使三个动作中之前 a 的概率最高,但是全部加了概率之后, b 加的更多的话,可能b就成为了概率最高的输出。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4JCkKCGA-1680158181247)(C:\Users\LoveSS\Desktop\强化学习.picture\NeatReader-1679022396646.png)]
这是一个理想情况,问题是我们只是做采样,有一些动作可能都没采样到,假设我们采样到了 b,c没有采样到 a ,现在所有的奖励都是正的,所有的动作的概率都会被提升,但是 a 没有被采样到,所以 a 是没有奖励的,那他的概率就只能下降了,这是不合理的,所以我们期望我们的奖励有正有负
我们可以把上面的公式修改一下,添加一条基线
∇ R ˉ θ ≈ 1 N ∑ t = 1 T ∑ n = 1 N ( R ( τ n ) − b ) ∇ l o g p θ ( a t n ∣ s t n ) \nabla \bar R_\theta \approx \frac {1} {N}\sum_{t=1}^{T} \sum_{n=1}^{N} (R(\tau ^ {n})-b ) \nabla log \ p_\theta(a_t^n | s_t^n) \\ ∇Rˉθ≈N1t=1∑Tn=1∑N(R(τn)−b)∇log pθ(atn∣stn)
其中 b b b 称为基线,通过这种方式就可以让 R ( τ n ) − b R(\tau^n) - b R(τn)−b 这一项有正有负。
分配合适分数
给每一个动作分配合适的分数(credit),只要在同一个回合、同一场游戏中,所有的状态-动作对就使用同样的奖励项进行加权。这显然是不公平的,因为在同一场游戏中,也许有些动作是好的,有些动作是不好的。 假设整场游戏的结果是好的, 但并不代表这场游戏中每一个动作都是好的。若是整场游戏结果不好, 但并不代表游戏中的每一个动作都是不好的。所以我们希望可以给每一个不同的动作前面都乘上不同的权重。每一个动作的不同权重反映了每一个动作到底是好的还是不好的。
一个做法是计算某个状态-动作对的奖励的时候,不把整场游戏得到的奖励全部加起来,只计算从这个动作执行以后得到的奖励。因为这场游戏在执行这个动作之前发生的事情是与执行这个动作是没有关系的,所以在执行这个动作之前得到的奖励都不能算是这个动作的贡献。我们把执行这个动作以后发生的所有奖励加起来,才是这个动作真正的贡献。
原来的权重是整场游戏的奖励的总和,现在改成从某个时刻 t t t 开始,假设这个动作是在 t t t 开始执行的,从 t t t 一直到游戏结束所有奖励的总和才能代表这个动作的好坏。
接下来更进一步,我们把未来的奖励做一个折扣,即
∇ R ˉ θ ≈ 1 N ∑ t = 1 T ∑ n = 1 N ( ∑ t ′ = t T n γ t ′ − t r t ′ n − b ) ∇ l o g p θ ( a t n ∣ s t n ) \nabla \bar R_\theta \approx \frac {1} {N}\sum_{t=1}^{T} \sum_{n=1}^{N} (\sum_{t' = t}^{T_n}\gamma^{t'-t}r_{t'}^n-b ) \nabla log \ p_\theta(a_t^n | s_t^n) \\ ∇Rˉθ≈N1t=1∑Tn=1∑N(t′=t∑Tnγt′−trt′n−b)∇log pθ(atn∣stn)
为什么要把未来的奖励做一个折扣呢?因为虽然在某一时刻,执行某一个动作,会影响接下来所有的结果(有可能在某一时刻执行的动作,接下来得到的奖励都是这个动作的功劳),但在一般的情况下,时间拖得越长,该动作的影响力就越小。
b b b 可以使依赖状态的,事实上 b b b 通常是一个网络估计出来的,他是一个网络的输出,我们把 R − b R-b R−b 这一项称为优势函数(advantage function),用 A θ ( s t , a t ) A^\theta (s_t,a_t) Aθ(st,at) ,来代表优势函数,优势函数取决于 s s s 和 a a a ,我们就是要计算在某个状态采取某个动作时优势函数的值,在计算优势函数值时还需要一个模型与环境交互,这样才能知道接下来得到的奖励和,优势函数的意义在于在某一个状态采取某一个动作其相较于其他动作的优势,优势函数不在于绝对的好,而是相对的好,即相对优势(relative advantage),因为在优势函数中我们会减去基线 b b b ,所以这个动作是相对的好不是绝对的好, A θ ( s t , a t ) A^\theta(s_t,a_t) Aθ(st,at) 通常可以由一个网络估计出来,这个网络被称为评论员(Critic)
蒙特卡洛策略梯度(REINFORCE)
我们介绍一下策略梯度中最经典的算法 REINFORCE,REINFORCE 用的是回合更新的方式,它在代码上的处理上是先获取每个步骤的奖励,然后计算每个步骤的未来总奖励 G t G_t Gt,将每个 G t G_t Gt代入
∇ R ˉ θ ≈ 1 N ∑ t = 1 T ∑ n = 1 N G t ∇ l o g π θ ( a t n ∣ s t n ) \nabla \bar R_\theta \approx \frac {1} {N}\sum_{t=1}^{T} \sum_{n=1}^{N} G_t \nabla log \ \pi_\theta(a_t^n | s_t^n) \\ ∇Rˉθ≈N1t=1∑Tn=1∑NGt∇log πθ(atn∣stn)
优化每一个动作的输出。所以我们在编写代码时会设计一个函数,这个函数的输入是每个步骤获取的奖励,输出是每一个步骤的未来总奖励。因为未来总奖励可写为
G t = ∑ k = t + 1 T γ k − t − 1 r k = r t − 1 + γ G t − 1 \begin{align} G_t &= \sum_{k=t+1}^T \gamma^{k-t-1}r_k \\ &= r_{t-1} + \gamma G_{t-1} \end{align} Gt=k=t+1∑Tγk−t−1rk=rt−1+γGt−1
蒙特卡洛策略梯度针对每一个动作计算梯度 ∇ l n π ( a t ∣ s t , θ ) \nabla ln \pi (a_t|s_t,\theta) ∇lnπ(at∣st,θ) ,在代码计算上时,我们需要获取神经网络的输出,神经网络会输出每个动作对应的概率值,然后我们可以获得实际的动作 a t a_t at ,把动作转成one-hot编码,比如([0,1,0]),与输出概率 [0.1,0.2,0.7]的对数值相乘就可以得到 l n π ( a t ∣ s t , θ ) ln \pi (a_t|s_t,\theta) lnπ(at∣st,θ)
算法流程

代码
我们这里给出代码实例
import torch as t
import numpy as np
import gym
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
gamma = 0.95 # 折扣因子
render = False # 是否显示画面
lr = 0.001 # 学习率
env = gym.make("CartPole-v1")
class PGModule(nn.Module):
def __init__(self, n_input, n_output) -> None:
super(PGModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(n_input, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, n_output),
)
self.optimizer = optim.Adam(self.net.parameters(), lr=lr)
self.episode_s = []
self.episode_a = []
self.episode_r = []
def store(self, state, action, reward): # 保留回合中的数据
self.episode_s.append(state)
self.episode_a.append(action)
self.episode_r.append(reward)
def forward(self, input):
return F.softmax(self.net(input), dim=1)
def clear(self):
self.episode_s = []
self.episode_a = []
self.episode_r = []
def learn(self):
G = []
g = 0
for r in self.episode_r[::-1]:
g = gamma * g + r
G.insert(0, g)
for i, s in enumerate(self.episode_s):
state = t.unsqueeze(t.tensor(s, dtype=t.float), dim=0)
a = self.episode_a[i]
a_prob = self.forward(state).flatten() # 展开
g = G[i]
loss = - g * t.log(a_prob[a])
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
class trainModule():
def __init__(self):
self.net = PGModule(4, 2)
def choose_action(self, observation) -> None:
observation_tensor_unsqueeze = t.unsqueeze(t.FloatTensor(observation), 0)
output = self.net.forward(observation_tensor_unsqueeze)
action = np.random.choice(range(output.detach().numpy().shape[1]), p=output.squeeze(dim=0).detach().numpy())
return action
def get_once(self) -> None:
for j in range(400):
observation, info = env.reset(seed=42)
allreward = 0
while True:
action = self.choose_action(observation)
observation_, reward, terminated, truncated, info = env.step(action)
self.net.store(observation, action, reward)
observation = observation_
allreward += reward
if render:
env.render()
if terminated or truncated:
self.net.learn()
self.net.clear()
print(f"j = {
j} reward is {
allreward}")
break
T = trainModule()
T.get_once()
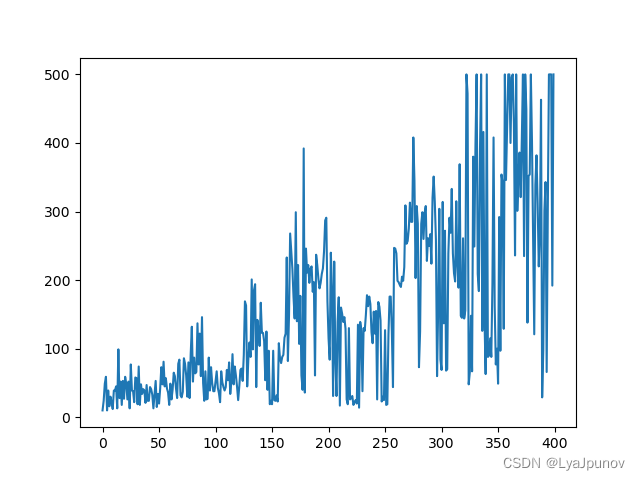
这里需要注意一点,我一开始以为我的代码有问题,后来发现别人也是这么写的,然后改了改参数可以收敛到200多三百,还不稳定,"CartPole-v1"这个游戏最高分是500,这个方法还是有点老了,不是很好用了已经。
然后我稍稍扩大了一下网络规模,采用了"CartPole-v0"这个游戏,看这个曲线反正是有点问题
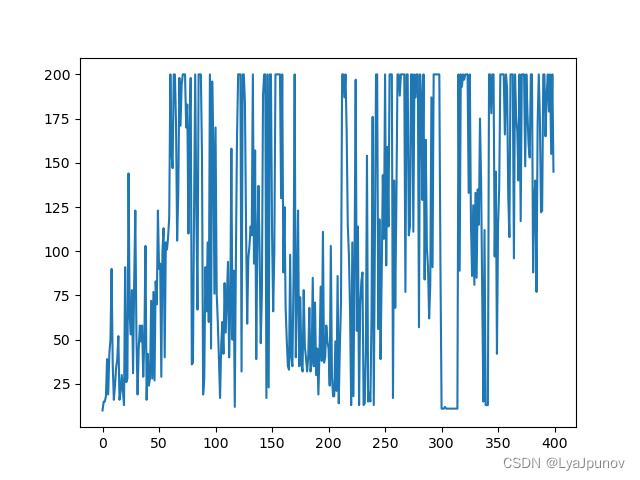
又调整了一下参数
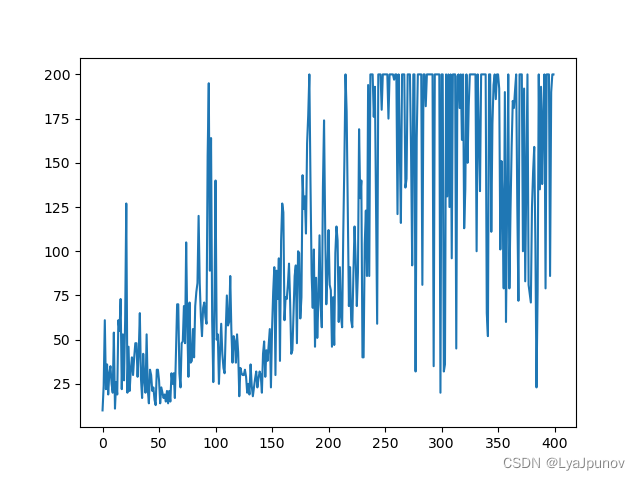
换个游戏"CartPole-v1",结果还行吧只能说,比惨不忍睹强点