1、基本定义
HA:High Available,译为:高可用性。
Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。对于只有一个NameNode的集群,若NameNode机器出现故障,则整个集群将无法使用,直到NameNode重新启动。
NameNode主要在以下两个方面影响HDFS集群:
①NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启.
②NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。
HDFS HA功能是通过配置Acitive/Standby两个NameNode实现在集群中对NameNode的热备份来解决上面的问题。如果出现故障,如机器崩溃或者额机器需要升级维护,这时可通过此种方法将NameNode很快的却换到另外一台机器。
2、服务规划
zhangkai:NameNode,JournalNode,DataNode;
zhangkai2:NameNode,JournalNode,DataNode;
zhangkai3:JournalNode,DataNode;
*3、HA的配置
①备份之前分布式的Hadoop配置文件(各个节点)
cp -r etc/hadoop etc/dist-hadoop②备份之前的Hadoop数据文件目录,删除原来的temp目录,并创建新的temp目录(各个节点)
cp -r data/tmp/ data/dist-tmp/
rm -rf data/tmp
mkdir data/tmp③创建共享edits目录
mkdir -p data/dfs/jn④配置hdfs-site.xml
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--配置联邦(NameService)-->
<property>
<name>dfs.nameservices</name>
<value>skha</value>
</property>
<property>
<name>dfs.ha.namenodes.skha</name>
<value>nn1,nn2</value>
</property>
<!--配置两个NameNode的RPC地址-->
<property>
<name>dfs.namenode.rpc-address.skha.nn1</name>
<value>zhangkai:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.skha.nn2</name>
<value>zhangkai2:9000</value>
</property>
<!--配置两个Web管理地址-->
<property>
<name>dfs.namenode.http-address.skha.nn1</name>
<value>zhangkai:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.skha.nn2</name>
<value>zhangkai2:50070</value>
</property>
<!--配置JournalNode地址-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://zhangkai:8485;zhangkai2:8485;zhangkai3:8485/skha</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.7.4/data/dfs/jn</value>
</property>
<!--配置HA proxy代理-->
<property>
<name>dfs.client.failover.proxy.provider.skha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置ssh隔离-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/zzxb/.ssh/id_rsa</value>
</property>⑤配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://skha</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.7.4/data/temp</value>
</property>⑥分发配置到各个节点
scp core-site.xml hdfs-site.xml zzxb@zhangkai2:/opt/app/hadoop-2.7.4/etc/hadoop
scp core-site.xml hdfs-site.xml zzxb@zhangkai3:/opt/app/hadoop-2.7.4/etc/hadoop*4、HA的启动
①启动journalnode(zhangkai,zhangkai2,zhangkai3都启)
sbin/hadoop-daemon.sh start journalnode②格式化hdfs系统在主节点(zhangkai)
bin/hdfs namenode -format③启动nn1(zhangkai)的NameNode服务
sbin/hadoop-daemon.sh start namenode④同步nn1的NameNode目录到nn2节点(zhangkai2),在nn2(zhangkai2)节点上执行
bin/hdfs namenode -bootstrapStandby⑤启动nn2节点(zhangkai2)上的NameNode服务
sbin/hadoop-daemon.sh start namenode⑥启动各个节点的DataNode服务
sbin/hadoop-daemon.sh start datanode ⑦分别查看不同节点的服务
zhangkai:

zhangkai2:
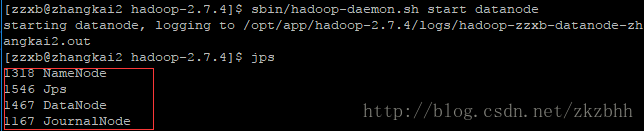
zhangkai3:
