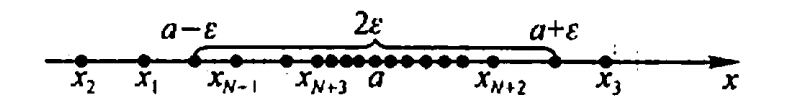参考资料:https://blog.csdn.net/zuoyonggang123/article/details/79110916
KaTex官方使用文档: https://katex.org/docs/supported.html
ε \varepsilon
开头前言说,微积分是概数统计基础,概数统计则是DM&ML之必修课”,是有一定根据的,包括后续数理统计当中,如正态分布的概率密度函数中用到了相关定积分的知识,包括最小二乘法问题的相关探讨求证都用到了求偏导数的等概念,这些都是跟微积分相关的知识。故咱们第一节先复习下微积分的相关基本概念。
事实上,古代数学中,单单无穷小、无穷大的概念就讨论了近200年,而后才由无限发展到极限的概念。
极限又分为两部分:数列的极限和函数的极限。
数列
{
x
n
}
\{x_n\}
{ x n }
n
n
n
x
n
=
f
(
n
)
x_n=f(n)
x n = f ( n )
n
n
n
{
x
n
}
\{x_n\}
{ x n }
数列极限的定义:
设
{
x
n
}
\{x_n\}
{ x n }
a
a
a
N
N
N
n
>
N
n>N
n > N
∣
x
n
−
a
∣
<
ε
|x_n -a | < \varepsilon
∣ x n − a ∣ < ε
a
a
a
{
x
n
}
\{x_n\}
{ x n }
{
x
n
}
\{x_n\}
{ x n }
a
a
a
lim
n
→
∞
=
a
\lim\limits_{n \to \infty}=a
n → ∞ lim = a
x
n
→
a
(
n
→
∞
)
.
x_n\to a\enspace (n\to\infty).
x n → a ( n → ∞ ) .
在数轴上用它们的对应点表示出来,再在数轴上作点
a
a
a
ε
\varepsilon
ε
(
a
−
ε
,
a
+
ε
)
:
(a-\varepsilon, a+\varepsilon):
( a − ε , a + ε ) :
收敛数列的性质
定理1(极限的唯一性):如果数列收敛,那么它的极限唯一;
定理2 (收敛数列的有界性):如果数列收敛,那么数列一定有界;
定理3:收敛数列的保号性
定理4:如果数列收敛,那么它的任一子数列也收敛,其极限也是
a
a
a
设函数
f
(
x
)
f(x)
f ( x )
x
0
x_0
x 0
0
<
∣
x
−
x
0
∣
<
d
0<|x - x_0| < d
0 < ∣ x − x 0 ∣ < d
f
(
x
)
f(x)
f ( x )
∣
f
(
x
)
−
A
∣
<
e
|f(x)-A|<e
∣ f ( x ) − A ∣ < e
f
(
x
)
f(x)
f ( x )
lim
x
→
x
0
f
(
x
)
=
A
\lim\limits_{x \to x_0}f(x)=A
x → x 0 lim f ( x ) = A
lim
x
→
x
0
f
(
x
)
=
A
⇔
∀
ε
>
0
,
∃
δ
>
0
,
当
0
<
∣
x
−
x
0
∣
<
δ
时
,
∣
f
(
x
)
−
A
∣
<
ε
.
\lim\limits_{x \to x_0}f(x)=A \lrArr \forall\varepsilon>0,\exist\delta>0,当 0<|x-x_0|<\delta时,|f(x)-A|<\varepsilon.
x → x 0 lim f ( x ) = A ⇔ ∀ ε > 0 , ∃ δ > 0 , 当 0 < ∣ x − x 0 ∣ < δ 时 , ∣ f ( x ) − A ∣ < ε .
几乎没有一门新的数学分支是某个人单独的成果,如笛卡儿和费马的解析几何不仅仅是他们两人研究的成果,而是若干数学思潮在16世纪和17世纪汇合的产物,是由许许多多的学者共同努力而成。
甚至微积分的发展也不是牛顿与莱布尼茨两人之功。在17世纪下半叶,数学史上出现了无穷小的概念,而后才发展到极限,到后来的微积分的提出。然就算牛顿和莱布尼茨提出了微积分,但微积分的概念尚模糊不清,在牛顿和莱布尼茨之后,后续经过一个多世纪的发展,诸多学者的努力,才真正清晰了微积分的概念。
也就是说,从无穷小到极限,再到微积分定义的真正确立,经历了几代人几个世纪的努力,而课本上所呈现的永远只是冰山一角。
自变量趋于有限值时函数的极限:
lim
x
→
x
0
f
(
x
)
=
A
\lim\limits_{x \to x_0}f(x)=A
x → x 0 lim f ( x ) = A
自变量趋于无穷大时函数的极限:
lim
x
→
∞
f
(
x
)
=
A
\lim\limits_{x \to \infty}f(x)=A
x → ∞ lim f ( x ) = A
定理 1 :在自变量的同一变化过程
x
→
x
0
x \to x_0
x → x 0
x
→
∞
x \to \infty
x → ∞
f
(
x
)
f(x)
f ( x )
A
A
A
f
(
x
)
=
A
+
α
f(x)=A+\alpha
f ( x ) = A + α
α
\alpha
α
定理 2 :在自变量的同一变化过程中,如果
f
(
x
)
f(x)
f ( x )
1
f
(
x
)
\frac{1}{f(x)}
f ( x ) 1
f
(
x
)
f(x)
f ( x )
1
f
(
x
)
\frac{1}{f(x)}
f ( x ) 1
有限个无穷小的和也是无穷小;
有界函数/常数/无穷小与无穷小的乘积是无穷小;
速度问题与切线问题:
动点的距离函数
s
=
f
(
t
)
s=f(t)
s = f ( t )
t
0
t_0
t 0
曲线函数的导数,可以看作曲线在
x
0
x_0
x 0
非匀速直线运动的速度和切线的斜率都归为如下的极限:
lim
Δ
x
→
0
f
(
x
0
+
Δ
x
)
−
f
(
x
0
)
Δ
x
\lim\limits_{\Delta x \to 0}\frac{f(x_0+\Delta x)-f(x_0)}{\Delta x}
Δ x → 0 lim Δ x f ( x 0 + Δ x ) − f ( x 0 )
导数定义: 设有定义域和取值都在实数域中的函数
y
=
f
(
x
)
y=f(x)
y = f ( x )
f
(
x
)
f(x)
f ( x )
x
0
x_0
x 0
x
x
x
x
0
x_0
x 0
Δ
x
\Delta x
Δ x
x
+
x
0
x+x_0
x + x 0
y
y
y
Δ
y
=
f
(
x
0
+
Δ
x
)
\Delta y=f(x_0+\Delta x)
Δ y = f ( x 0 + Δ x )
Δ
y
\Delta y
Δ y
Δ
x
\Delta x
Δ x
Δ
x
→
0
\Delta x \to 0
Δ x → 0
y
=
f
(
x
)
y=f(x)
y = f ( x )
x
0
x_0
x 0
y
=
f
(
x
)
y=f(x)
y = f ( x )
x
0
x_0
x 0
f
′
(
x
0
)
f\rq(x_0)
f ′ ( x 0 )
f
′
(
x
0
)
=
lim
Δ
x
→
0
Δ
y
Δ
x
=
lim
Δ
x
→
0
f
(
x
0
+
Δ
x
)
−
f
(
x
0
)
Δ
x
f\rq(x_0)=\lim\limits_{\Delta x \to 0}\frac{\Delta y}{\Delta x}=\lim\limits_{\Delta x \to 0}\frac{f(x_0+\Delta x)-f(x_0)}{\Delta x}
f ′ ( x 0 ) = Δ x → 0 lim Δ x Δ y = Δ x → 0 lim Δ x f ( x 0 + Δ x ) − f ( x 0 )
导数概念就是函数变化率这一概念的精确描述。
[
u
(
x
)
±
v
(
x
)
]
′
=
u
′
(
x
)
±
v
′
(
x
)
[u(x) \pm v(x)]\rq = u\rq(x) \pm v\rq(x)
[ u ( x ) ± v ( x ) ] ′ = u ′ ( x ) ± v ′ ( x )
[
u
(
x
)
v
(
x
)
]
′
=
u
′
(
x
)
v
(
x
)
+
u
(
x
)
v
′
(
x
)
[u(x) v(x)]\rq = u\rq(x)v(x) + u(x)v\rq(x)
[ u ( x ) v ( x ) ] ′ = u ′ ( x ) v ( x ) + u ( x ) v ′ ( x )
[
u
(
x
)
v
(
x
)
]
′
=
u
′
(
x
)
v
(
x
)
−
u
(
x
)
v
′
(
x
)
v
2
(
x
)
[\frac{u(x)}{v(x)}]\rq = \frac{u\rq(x)v(x) - u(x)v\rq(x)}{v^2(x)}
[ v ( x ) u ( x ) ] ′ = v 2 ( x ) u ′ ( x ) v ( x ) − u ( x ) v ′ ( x )
反函数的求导法则:
[
f
−
1
(
x
)
]
′
=
1
f
′
(
y
)
[f^{-1}(x)]\rq=\frac{1}{f\rq(y)}
[ f − 1 ( x ) ] ′ = f ′ ( y ) 1
复合函数的求导法则:
u
=
g
(
x
)
u=g(x)
u = g ( x )
x
x
x
y
=
f
(
u
)
y=f(u)
y = f ( u )
u
=
g
(
x
)
u=g(x)
u = g ( x )
y
=
f
[
g
(
x
)
]
y=f[g(x)]
y = f [ g ( x ) ]
x
x
x
d
y
d
x
=
f
′
(
u
)
⋅
g
′
(
x
)
或
d
y
d
x
=
d
y
d
u
⋅
d
u
d
x
\frac{dy}{dx}=f\rq(u)\cdot g\rq(x) 或 \frac{dy}{dx}=\frac{dy}{du} \cdot \frac{du}{dx}
d x d y = f ′ ( u ) ⋅ g ′ ( x ) 或 d x d y = d u d y ⋅ d x d u
函数
y
=
f
(
x
)
y=f(x)
y = f ( x )
y
y
y
x
x
x
y
=
l
n
x
+
1
−
x
2
y=lnx+\sqrt{1-x^2}
y = l n x + 1 − x 2
有些函数的表达式并不是这样,例如,方程:
x
+
y
3
−
1
=
0
x+y^3-1=0
x + y 3 − 1 = 0
设函数
y
=
f
(
x
)
y=f(x)
y = f ( x )
Z
Z
Z
Z
Z
Z
x
0
x_0
x 0
x
0
x_0
x 0
x
0
+
Δ
x
x_0+\Delta x
x 0 + Δ x
Δ
y
=
f
(
x
0
+
Δ
x
)
−
f
(
x
0
)
\Delta y = f(x_0+\Delta x) - f(x_0)
Δ y = f ( x 0 + Δ x ) − f ( x 0 )
Δ
y
=
A
Δ
x
+
o
(
Δ
x
)
\Delta y = A\Delta x + o(\Delta x)
Δ y = A Δ x + o ( Δ x )
A
A
A
Δ
x
\Delta x
Δ x
y
=
f
(
x
)
y=f(x)
y = f ( x )
x
0
x_0
x 0
A
Δ
x
A\Delta x
A Δ x
y
=
f
(
x
)
y=f(x)
y = f ( x )
x
0
x_0
x 0
Δ
x
\Delta x
Δ x
d
y
dy
d y
d
y
=
A
Δ
x
dy = A\Delta x
d y = A Δ x
积分是微积分学与数学分析里的一个核心概念,分为定积分和不定积分两种。
原函数的定义 : 如果再区间
I
I
I
F
(
x
)
F(x)
F ( x )
f
(
x
)
f(x)
f ( x )
x
∈
I
x \isin I
x ∈ I
F
′
(
x
)
=
f
(
x
)
或
d
F
(
x
)
=
f
(
x
)
d
(
x
)
F\rq(x)=f(x) 或 dF(x)=f(x)d(x)
F ′ ( x ) = f ( x ) 或 d F ( x ) = f ( x ) d ( x )
F
(
x
)
F(x)
F ( x )
f
(
x
)
f(x)
f ( x )
I
I
I
不定积分: 在区间
I
I
I
f
(
x
)
f(x)
f ( x )
f
(
x
)
f(x)
f ( x )
I
I
I
∫
f
(
x
)
d
x
\int f(x)dx
∫ f ( x ) d x
基本积分公式:
函数
f
(
x
)
f(x)
f ( x )
[
a
,
b
]
[a, b]
[ a , b ]
∫
a
b
f
(
x
)
d
x
\int _a^bf(x)dx
∫ a b f ( x ) d x
积分中值公式:
∫
a
b
f
(
x
)
d
x
=
f
(
ξ
)
(
b
−
a
)
\int _a^bf(x)dx=f(\xi)(b-a)
∫ a b f ( x ) d x = f ( ξ ) ( b − a )
牛顿-莱布尼兹公式:如果函数
F
(
x
)
F(x)
F ( x )
f
(
x
)
f(x)
f ( x )
[
a
,
b
]
[a, b]
[ a , b ]
∫
a
b
f
(
x
)
d
x
=
F
(
b
)
−
F
(
a
)
\int _a^bf(x)dx=F(b)-F(a)
∫ a b f ( x ) d x = F ( b ) − F ( a )
这个公式打通了原函数与定积分之间的联系,它表明:一个连续函数在区间
[
a
,
b
]
[a, b]
[ a , b ]
[
a
,
b
]
[a, b]
[ a , b ]
例如:
∫
0
1
x
2
d
x
=
[
1
3
x
3
]
0
1
=
1
3
\int_0^1x^2dx=[\frac{1}{3}x^3]_0^1=\frac{1}{3}
∫ 0 1 x 2 d x = [ 3 1 x 3 ] 0 1 = 3 1
定积分的换元法和部分换元法
反常积分
反常积分的审敛法
Γ
\varGamma
Γ
对于二元函数
z
=
f
(
x
,
y
)
z = f(x,y)
z = f ( x , y )
x
x
x
y
y
y
x
x
x
x
x
x
z
=
f
(
x
,
y
)
z = f(x,y)
z = f ( x , y )
x
x
x
定义:设函数
z
=
f
(
x
,
y
)
z = f(x,y)
z = f ( x , y )
(
x
0
,
y
0
)
(x_0,y_0)
( x 0 , y 0 )
y
y
y
y
0
y_0
y 0
x
x
x
x
0
x_0
x 0
lim
Δ
x
→
0
f
(
x
0
+
Δ
x
,
y
0
)
−
f
(
x
0
,
y
0
)
Δ
x
\lim\limits_{\Delta x \to 0}\frac{f(x_0+\Delta x,y_0)-f(x_0,y_0)}{\Delta x}
Δ x → 0 lim Δ x f ( x 0 + Δ x , y 0 ) − f ( x 0 , y 0 )
z
=
f
(
x
,
y
)
z=f(x,y)
z = f ( x , y )
(
x
0
,
y
0
)
(x_0,y_0)
( x 0 , y 0 )
x
x
x
∂
z
∂
x
∣
x
=
x
0
y
=
y
0
或
f
x
(
x
0
,
y
0
)
=
lim
Δ
x
→
0
f
(
x
0
+
Δ
x
,
y
0
)
−
f
(
x
0
,
y
0
)
Δ
x
\frac{\partial z}{\partial x}|_{x=x_0 \atop y=y_0} 或 f_x(x_0,y_0) = \lim\limits_{\Delta x \to 0}\frac{f(x_0+\Delta x,y_0)-f(x_0,y_0)}{\Delta x}
∂ x ∂ z ∣ y = y 0 x = x 0 或 f x ( x 0 , y 0 ) = Δ x → 0 lim Δ x f ( x 0 + Δ x , y 0 ) − f ( x 0 , y 0 )
类似的,二元函数对
y
y
y
x
x
x
在个别试验中其结果呈现不确定性,在大量重复试验中其结果又具有统计规律性的现象,称之为随机现象 。概率论和数理统计是研究和揭示随机现象统计规律性的一门数学学科。
随机试验
E
E
E 样本空间
S
S
S
E
E
E 随机事件 : 随机试验
E
E
E
S
S
S 事件 ;分为基本事件、不可能事件
ϕ
\phi
ϕ
概率 :
P
(
A
)
P(A)
P ( A )
A
A
A
P
(
A
)
⩾
0
,
P
(
S
)
=
1
P(A) \geqslant 0, P(S) = 1
P ( A ) ⩾ 0 , P ( S ) = 1
条件概率
P
(
A
∣
B
)
P(A|B)
P ( A ∣ B )
A
A
A
B
B
B
P
(
A
∣
B
)
P(A|B)
P ( A ∣ B )
B
B
B
A
A
A
P
(
A
∣
B
)
=
P
(
A
B
)
P
(
B
)
P(A|B)=\frac {P(AB)}{P(B)}
P ( A ∣ B ) = P ( B ) P ( A B )
划分:
S
S
S
E
E
E
B
1
,
B
2
,
.
.
.
.
,
B
n
B_1, B_2, ...., B_n
B 1 , B 2 , . . . . , B n
E
E
E
B
i
B
j
=
ϕ
B_iB_j = \phi
B i B j = ϕ
B
1
∪
B
2
∪
.
.
.
.
∪
B
n
=
S
B_1\cup B_2\cup ....\cup B_n=S
B 1 ∪ B 2 ∪ . . . . ∪ B n = S
B
1
,
B
2
,
.
.
.
.
,
B
n
B_1, B_2, ...., B_n
B 1 , B 2 , . . . . , B n
S
S
S
全概率公式:
B
1
,
B
2
,
.
.
.
.
,
B
n
B_1, B_2, ...., B_n
B 1 , B 2 , . . . . , B n
S
S
S
P
(
A
)
=
P
(
A
∣
B
1
)
P
(
B
1
)
+
P
(
A
∣
B
2
)
P
(
B
2
)
+
.
.
.
+
P
(
A
∣
B
n
)
P
(
B
n
)
P(A)=P(A|B_1)P(B_1)+P(A|B_2)P(B_2)+...+P(A|B_n)P(B_n)
P ( A ) = P ( A ∣ B 1 ) P ( B 1 ) + P ( A ∣ B 2 ) P ( B 2 ) + . . . + P ( A ∣ B n ) P ( B n )
贝叶斯(Bayes)公式:
P
(
B
i
∣
A
)
=
P
(
B
i
A
)
P
(
A
)
=
P
(
A
∣
B
i
)
P
(
B
i
)
∑
j
=
1
n
P
(
A
∣
B
j
)
P
(
B
j
)
P(B_i|A)=\frac{P(B_iA)}{P(A)}=\frac{P(A|B_i)P(B_i)}{\displaystyle\sum_{j=1}^nP(A|B_j)P(B_j)}
P ( B i ∣ A ) = P ( A ) P ( B i A ) = j = 1 ∑ n P ( A ∣ B j ) P ( B j ) P ( A ∣ B i ) P ( B i )
可以通过条件概率的定义和全概率公式求得。
**应用案例:**某电子设备制造厂所用的元件是由三家元件制造厂提供的,根据以往的记录有以下的数据:
元件制造厂
次品率
提供元件的份额
1
0.02
0.15
2
0.01
0.80
3
0.03
0.05
设这三家工厂的产品在仓库中是均匀混合的,且无区别的标志,(1)在仓库中随机地取一只元件,求它是次品的概率;(2)在仓库中随机地取一只元件,若已知取到的是次品,为分析此次品出自何厂,需求出此次品由三家工厂生产的概率分别是多少?解 随机试验
E
E
E
A
A
A
B
i
(
i
=
1
,
2
,
3
)
B_i(i=1,2,3)
B i ( i = 1 , 2 , 3 )
S
S
S
P
(
B
1
)
=
0.15
,
P
(
B
2
)
=
0.80
,
P
(
B
3
)
=
0.05
P(B_1)=0.15, P(B_2)=0.80, P(B_3)=0.05
P ( B 1 ) = 0 . 1 5 , P ( B 2 ) = 0 . 8 0 , P ( B 3 ) = 0 . 0 5
P
(
A
)
=
P
(
A
∣
B
1
)
P
(
B
1
)
+
P
(
A
∣
B
2
)
P
(
B
2
)
+
P
(
A
∣
B
3
)
P
(
B
3
)
=
0.0125
P(A)=P(A|B_1)P(B_1)+P(A|B_2)P(B_2)+P(A|B_3)P(B_3)=0.0125
P ( A ) = P ( A ∣ B 1 ) P ( B 1 ) + P ( A ∣ B 2 ) P ( B 2 ) + P ( A ∣ B 3 ) P ( B 3 ) = 0 . 0 1 2 5
P
(
B
i
∣
A
)
=
P
(
A
∣
B
i
)
P
(
B
i
)
P
(
A
)
P(B_i|A)=\frac{P(A|B_i)P(B_i)}{P(A)}
P ( B i ∣ A ) = P ( A ) P ( A ∣ B i ) P ( B i )
P
(
B
1
∣
A
)
=
0.24
,
P
(
B
2
∣
A
)
=
0.64
,
P
(
B
1
∣
A
)
=
0.12
,
P(B_1|A)=0.24, P(B_2|A)=0.64, P(B_1|A)=0.12,
P ( B 1 ∣ A ) = 0 . 2 4 , P ( B 2 ∣ A ) = 0 . 6 4 , P ( B 1 ∣ A ) = 0 . 1 2 ,
如果事件
A
,
B
A,B
A , B
P
(
A
B
)
=
P
(
A
)
P
(
B
)
,
P
(
B
∣
A
)
=
P
(
B
)
P(AB)=P(A)P(B), P(B|A)=P(B)
P ( A B ) = P ( A ) P ( B ) , P ( B ∣ A ) = P ( B )
A
A
A
B
B
B
A
,
B
A,B
A , B
事件的独立性是概率论中一个非常重要的概念,概率论与数理统计中的很多很多内容都是在独立的前提下讨论的。
概念总结:
随机变量: 设随机试验的样本空间为
S
=
{
e
}
.
X
=
X
(
e
)
S=\{e\}. X=X(e)
S = { e } . X = X ( e )
S
S
S
X
=
X
(
e
)
X=X(e)
X = X ( e )
比如,用 Y 记欧车间一天的缺勤人数,W 记某地区第一季度的降雨量。那么 Y,W 就是随机变量。
随机变量的引入,使我们能用随机变量来描述各种随机现象,并能利用数学分析的方法对随机试验的结果进行深入广泛的研究和讨论。
离散随机变量是指全部可能取到的值时有限个或可列无限多个的随机变量。
设离散随机变量 X 所有可能取的值为
x
k
(
k
=
1
,
2
,
3....
)
x_k(k=1,2,3....)
x k ( k = 1 , 2 , 3 . . . . )
{
X
=
x
k
}
\{X=x_k\}
{ X = x k }
P
{
X
=
x
k
}
=
p
k
,
k
=
1
,
2
,
.
.
.
P\{X=x_k\}=p_k, k=1,2, ...
P { X = x k } = p k , k = 1 , 2 , . . .
天气的阴晴,硬币的正反,点灯的开关,
一、(0-1)分布的分布律:
P
{
X
=
k
}
=
p
k
(
1
−
p
)
1
−
k
,
k
=
0
,
1
P\{X=k\}=p^k(1-p)^{1-k}, k=0,1
P { X = k } = p k ( 1 − p ) 1 − k , k = 0 , 1
试验 E 只有两个可能结果:
A
,
A
‾
A, \overline{A}
A , A
n
n
n
n
n
n
P
{
X
=
k
}
=
(
n
k
)
p
k
(
1
−
p
)
n
−
k
,
k
=
10
,
1
,
2
,
.
.
.
.
,
n
P\{X=k\}= {n \choose k}p^k(1-p)^{n-k}, k=10,1,2,....,n
P { X = k } = ( k n ) p k ( 1 − p ) n − k , k = 1 0 , 1 , 2 , . . . . , n
组合数: 从
n
n
n
m
(
m
≤
n
)
m(m≤n)
m ( m ≤ n )
n
n
n
m
m
m
n
n
n
m
(
m
≤
n
)
m(m≤n)
m ( m ≤ n )
n
n
n
m
m
m
C
n
m
=
(
n
m
)
=
C
(
n
,
m
)
=
n
!
m
!
(
n
−
m
)
!
C_n^m= {n \choose m}=C(n,m)=\frac{n!}{m!(n-m)!}
C n m = ( m n ) = C ( n , m ) = m ! ( n − m ) ! n !
二、泊松分布
X
X
X
P
{
X
=
k
}
=
λ
k
e
−
λ
k
!
,
k
=
0
,
1
,
2
,
.
.
.
P\{X=k\}=\frac{\lambda^ke^{-\lambda}}{k!}, k=0,1,2,...
P { X = k } = k ! λ k e − λ , k = 0 , 1 , 2 , . . .
λ
>
0
\lambda>0
λ > 0
X
X
X
λ
\lambda
λ
X
∼
π
(
λ
)
X\sim \pi(\lambda)
X ∼ π ( λ )
∑
k
=
0
∞
P
{
X
=
k
}
=
∑
k
=
0
∞
λ
k
e
−
λ
k
!
=
e
−
λ
∑
k
=
0
∞
λ
k
k
!
=
e
−
λ
⋅
e
λ
=
1
\displaystyle\sum_{k=0}^ \infty P\{X=k\} =\displaystyle\sum_{k=0}^ \infty \frac{\lambda^ke^{-\lambda}}{k!} =e^{-\lambda} \displaystyle\sum_{k=0}^ \infty \frac{\lambda^k}{k!}=e^{-\lambda}\cdot e^{\lambda}=1
k = 0 ∑ ∞ P { X = k } = k = 0 ∑ ∞ k ! λ k e − λ = e − λ k = 0 ∑ ∞ k ! λ k = e − λ ⋅ e λ = 1
备注:泊松公式的求证过程用到了泰勒级数
以下是常见函数在x=0处的泰勒级数,即麦克劳林级数:
具有泊松分布的随机变量,如一本书一页中的印刷错误数,某一医院在一天内的急诊病人数,某一地区一个时间间隔内发送交通事故的次数…
当 n 很大时,以 n,p 为参数的二项分布的概率值可以由参数为
λ
=
n
p
\lambda=np
λ = n p
定义:设
X
X
X
F
(
x
)
=
P
{
X
⩽
x
}
,
−
∞
<
x
<
∞
F(x)=P\{X\leqslant x\}, -\infty<x<\infty
F ( x ) = P { X ⩽ x } , − ∞ < x < ∞
X
X
X
连续型随机变量
X
X
X
F
(
x
)
F(x)
F ( x )
F
(
x
)
=
∫
−
∞
x
f
(
t
)
d
t
F(x)=\int _{-\infty}^xf(t)dt
F ( x ) = ∫ − ∞ x f ( t ) d t
f
(
x
)
f(x)
f ( x )
X
X
X
一、均匀分布
X
X
X
f
(
x
)
=
{
1
b
−
a
,
a<x<b
,
0
,
其他
,
f(x)=\begin{cases} \frac{1}{b-a}, &\text{ a<x<b }, \\ 0, &\text{其他}, \end{cases}
f ( x ) = { b − a 1 , 0 , a<x<b , 其他 ,
X
X
X
(
a
,
b
)
(a,b)
( a , b )
X
∼
U
(
a
,
b
)
.
X\sim U(a,b).
X ∼ U ( a , b ) .
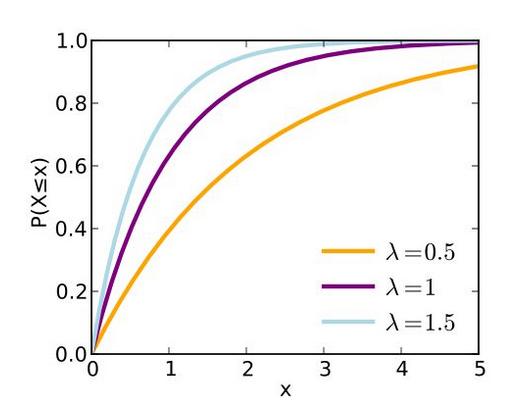
二、指数分布
f
(
x
)
=
{
1
θ
e
−
x
/
θ
,
x>0
,
0
,
其他
,
f(x)=\begin{cases} \frac{1}{\theta}e^{-x/\theta}, &\text{ x>0 }, \\ 0, &\text{其他}, \end{cases}
f ( x ) = { θ 1 e − x / θ , 0 , x>0 , 其他 ,
λ
=
1
/
θ
\lambda=1/\theta
λ = 1 / θ
分布函数:
P
{
X
⩽
x
}
=
F
(
x
)
=
1
−
e
−
x
/
θ
,
x
>
0
P\{X \leqslant x\}=F(x)=1-e^{-x/\theta}, x>0
P { X ⩽ x } = F ( x ) = 1 − e − x / θ , x > 0
数学期望:
E
(
X
)
=
θ
E(X)=\theta
E ( X ) = θ
D
(
X
)
=
θ
2
D(X)=\theta ^2
D ( X ) = θ 2
指数函数的一个重要特征是无记忆性。
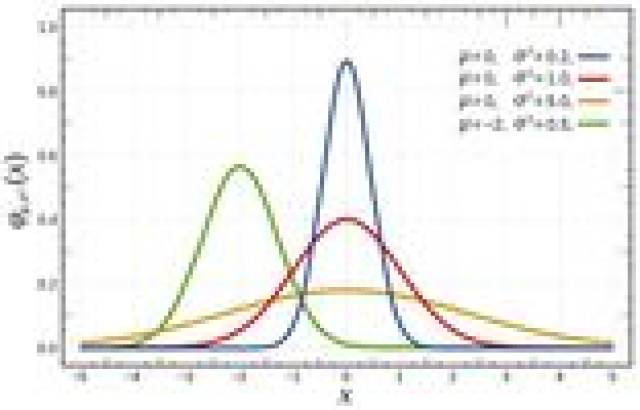
三、正态分布
X
X
X
f
(
x
)
=
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
,
−
∞
<
x
<
∞
f(x)=\frac{1}{\sqrt{2\pi} \sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}, -\infty < x< \infty
f ( x ) = 2 π
σ 1 e − 2 σ 2 ( x − μ ) 2 , − ∞ < x < ∞
μ
,
σ
\mu,\sigma
μ , σ
X
X
X
μ
,
σ
\mu, \sigma
μ , σ
X
∼
N
(
μ
,
σ
2
)
.
X\sim N(\mu, \sigma^2).
X ∼ N ( μ , σ 2 ) .
正态分布的分布函数为:
F
(
x
)
=
1
2
π
σ
∫
−
∞
x
e
−
(
t
−
μ
)
2
2
σ
2
d
t
F(x)=\frac{1}{\sqrt{2\pi} \sigma}\int _{-\infty}^xe^{-\frac{(t-\mu)^2}{2\sigma^2}}dt
F ( x ) = 2 π
σ 1 ∫ − ∞ x e − 2 σ 2 ( t − μ ) 2 d t
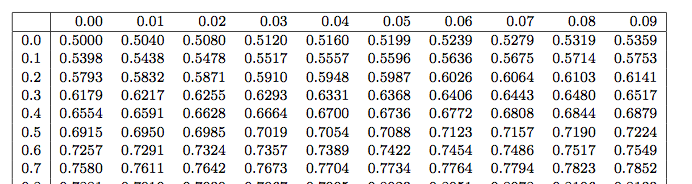
标准正态分布
Φ
(
x
)
\varPhi(x)
Φ ( x )
备注:表头的横向表示小数点后第二位,纵向表示整数部分及小数点后第一位,x 的值为两者之和。
from scipy. stats import norm
norm. cdf( 0.11 )
norm. ppf( 0.5438 )
pdf: 概率密度函数
cdf:概率分布
ppf:cdf 的逆过程,通过百分比求 x
任何的正态分布都可以通过以下线性变换转化成标准正态分布:
Z
=
X
−
μ
σ
Z=\frac{X-\mu}{\sigma}
Z = σ X − μ
在自然现象和社会现象中,大量随机变量都服从或近似服从正态分布。
概念总结:
定义: 设
(
X
,
Y
)
(X,Y)
( X , Y )
x
,
y
x,y
x , y
F
(
x
,
y
)
=
P
{
X
⩽
x
,
Y
⩽
y
}
F(x,y)=P\{X \leqslant x, Y\leqslant y\}
F ( x , y ) = P { X ⩽ x , Y ⩽ y }
(
X
,
Y
)
(X,Y)
( X , Y )
X
,
Y
X,Y
X , Y
F
(
x
,
y
)
=
∫
−
∞
y
∫
−
∞
x
f
(
u
,
v
)
d
u
d
v
F(x,y)=\int _{-\infty}^y\int _{-\infty}^xf(u,v)dudv
F ( x , y ) = ∫ − ∞ y ∫ − ∞ x f ( u , v ) d u d v
f
(
x
,
y
)
f(x,y)
f ( x , y )
(
X
,
Y
)
(X,Y)
( X , Y )
X
,
Y
X,Y
X , Y
∂
2
F
(
x
,
y
)
∂
x
∂
y
=
f
(
x
,
y
)
\frac{\partial^2F(x,y)}{\partial x\partial y}=f(x,y)
∂ x ∂ y ∂ 2 F ( x , y ) = f ( x , y )
边缘分布函数:
F
X
(
x
)
=
F
(
x
,
∞
)
,
f
X
(
x
)
=
∫
−
∞
∞
f
(
x
,
y
)
d
y
F_X(x)=F(x, \infty), f_X(x)=\int _{-\infty}^\infty f(x,y)dy
F X ( x ) = F ( x , ∞ ) , f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y
条件分布:
Z
=
X
+
Y
,
Z
=
Y
/
X
,
Z
=
X
Y
Z=X+Y,Z=Y/X,Z=XY
Z = X + Y , Z = Y / X , Z = X Y
随机变量的分布函数、概率密度和分布律,它们都能完整地描述随机变量,但在某些实际或理论问题中,人们感兴趣于某些能描述随机变量的某种特征。
离散型随机变量 X 的期望:
E
(
X
)
=
∑
k
=
1
∞
x
k
P
k
E(X)=\displaystyle\sum_{k=1}^\infty x_kP_k
E ( X ) = k = 1 ∑ ∞ x k P k
连续型随机变量 X 的期望:
E
(
X
)
=
∫
−
∞
∞
x
f
(
x
)
d
x
E(X)=\int_{-\infty}^\infty xf(x)dx
E ( X ) = ∫ − ∞ ∞ x f ( x ) d x
切比雪夫不等式:设随机变量
X
X
X
E
(
X
)
=
μ
E(X)=\mu
E ( X ) = μ
D
(
X
)
=
σ
2
D(X)=\sigma^2
D ( X ) = σ 2
ε
\varepsilon
ε
P
{
∣
X
−
μ
∣
⩾
ε
}
⩽
σ
2
ε
2
P\{|X-\mu| \geqslant \varepsilon\} \leqslant \frac{\sigma^2}{\varepsilon^2}
P { ∣ X − μ ∣ ⩾ ε } ⩽ ε 2 σ 2
协方差:对于二维随机变量
(
X
,
Y
)
(X,Y)
( X , Y )
E
{
[
X
−
E
(
X
)
]
[
Y
−
E
(
Y
)
]
}
E\{[X-E(X)][Y-E(Y)]\}
E { [ X − E ( X ) ] [ Y − E ( Y ) ] }
X
,
Y
X,Y
X , Y
C
o
v
(
X
,
Y
)
Cov(X,Y)
C o v ( X , Y )
C
o
v
(
X
,
Y
)
=
E
{
[
X
−
E
(
X
)
]
[
Y
−
E
(
Y
)
]
}
Cov(X,Y)=E\{[X-E(X)][Y-E(Y)]\}
C o v ( X , Y ) = E { [ X − E ( X ) ] [ Y − E ( Y ) ] }
ρ
X
Y
=
C
o
v
(
X
,
Y
)
D
(
X
)
D
(
Y
)
\rho_{XY}=\frac{Cov(X,Y)}{\sqrt {D(X)} \sqrt {D(Y)}}
ρ X Y = D ( X )
D ( Y )
C o v ( X , Y )
X
,
Y
X,Y
X , Y
设
X
,
Y
X, Y
X , Y
E
(
X
k
)
,
k
=
1
,
2
,
.
.
.
E(X^k), k=1,2,...
E ( X k ) , k = 1 , 2 , . . .
X
X
X
k
k
k
k
k
k
E
{
[
X
−
E
(
X
)
]
k
}
,
k
=
2
,
3
,
.
.
.
.
E\{[X-E(X)]^k\}, k=2,3,....
E { [ X − E ( X ) ] k } , k = 2 , 3 , . . . .
X
X
X
k
k
k
E
(
X
k
Y
l
)
,
k
,
l
=
1
,
2
,
.
.
.
.
E(X^kY^l), k,l=1,2,....
E ( X k Y l ) , k , l = 1 , 2 , . . . .
X
,
Y
X,Y
X , Y
k
+
l
k+l
k + l
E
{
[
X
−
E
(
X
)
]
k
[
Y
−
E
(
Y
)
]
l
}
,
k
,
l
=
2
,
3
,
.
.
.
.
E\{[X-E(X)]^k[Y-E(Y)]^l\}, k,l=2,3,....
E { [ X − E ( X ) ] k [ Y − E ( Y ) ] l } , k , l = 2 , 3 , . . . .
X
,
Y
X,Y
X , Y
k
+
l
k+l
k + l
显然,
X
X
X
E
(
X
)
E(X)
E ( X )
X
X
X
D
(
X
)
D(X)
D ( X )
X
X
X
C
o
v
(
X
,
Y
)
Cov(X,Y)
C o v ( X , Y )
X
X
X
Y
Y
Y
n维随机变量的协方差矩阵。
极限定理是概率论的基本理论,其中最重要的是“大数定律”和“中心极限定理”。大数定律是描述随机变量序列的前一些项的算术平均值在某种条件下收敛到这些项的均值的算术平均值;中心极限定理则是确定在什么条件下,大量随机变量之和的分布逼近于正态分布。
弱大数定理(辛钦大数定律): 设
X
1
,
X
2
,
.
.
.
X_1,X_2,...
X 1 , X 2 , . . .
E
(
X
k
)
=
μ
E(X_k)=\mu
E ( X k ) = μ
ε
>
0
\varepsilon >0
ε > 0
lim
n
→
∞
P
{
∣
1
n
∑
k
=
1
n
X
k
−
μ
∣
<
ε
}
=
1
\lim _{n \to \infty}P\{|\frac{1}{n} \sum_{k=1}^nX_k-\mu|< \varepsilon\} = 1
n → ∞ lim P { ∣ n 1 k = 1 ∑ n X k − μ ∣ < ε } = 1
伯努利大数定理:
中心极限定理:
独立同分布的中心极限定理
李雅普诺夫定理
棣莫弗-拉普拉斯定理
数理统计是以概率论为理论基础,根据试验或观察得到的数据,来研究随机现象,对研究对象的客观规律性作出种种合理的估计和判断。
在概率论中,所研究的随机变量,它的分布都是假设已知的,在这一前提下去研究它的性质、特点和规律性。
在数理统计中,随机变量的分布是未知的,人们是通过对所研究的随机变量进行重复独立的观察,得到许多观察值,对这些数据进行分析,从而对所研究的随机变阿玲的分布做出各种腿短的。
定义:设
X
X
X
F
F
F
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X 1 , X 2 , . . . , X n
F
F
F
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X 1 , X 2 , . . . , X n
F
F
F
n
n
n 样本 ,它们的观察值
x
1
,
x
2
,
.
.
.
,
x
n
x_1,x_2,...,x_n
x 1 , x 2 , . . . , x n
X
X
X
n
n
n
F
∗
(
x
1
,
X
−
2
,
.
.
.
.
,
x
n
)
=
∏
i
=
1
n
F
(
x
i
)
F^*(x_1,X-2,....,x_n)=\prod _{i=1}^n F(x_i)
F ∗ ( x 1 , X − 2 , . . . . , x n ) = i = 1 ∏ n F ( x i )
f
∗
(
x
1
,
X
−
2
,
.
.
.
.
,
x
n
)
=
∏
i
=
1
n
f
(
x
i
)
f^*(x_1,X-2,....,x_n)=\prod _{i=1}^n f(x_i)
f ∗ ( x 1 , X − 2 , . . . . , x n ) = i = 1 ∏ n f ( x i )
备注:样本和样本值是完全不同的概念,比如一个班里面有50个人,每个人都是一个样本,样本是进行统计推断的依据。
直方图,频率直方图
分位数: 设有容量为
n
n
n
x
1
,
x
2
,
.
.
.
x
n
x_1,x_2,...x_n
x 1 , x 2 , . . . x n
p
p
p
(
0
<
p
<
1
)
(0<p<1)
( 0 < p < 1 )
x
p
x_p
x p
至少有
n
p
np
n p
x
p
x_p
x p
至少有
n
(
1
−
p
)
n(1-p)
n ( 1 − p )
x
p
x_p
x p
0.25 分位数
x
0
.
25
x_0.25
x 0 . 2 5
Q
1
Q_1
Q 1
x
0
.
5
x_0.5
x 0 . 5
Q
2
Q_2
Q 2
x
0
.
75
x_0.75
x 0 . 7 5
Q
3
Q_3
Q 3
中位数 M 所在的位置就是数据集的中心;
[
M
i
n
,
Q
1
]
,
[
Q
2
,
M
]
,
[
M
,
Q
3
]
,
[
Q
3
,
M
a
x
]
[Min, Q_1], [Q_2, M], [M, Q_3], [Q_3, Max]
[ M i n , Q 1 ] , [ Q 2 , M ] , [ M , Q 3 ] , [ Q 3 , M a x ] M -Min > Max -M : 左倾斜,反之右倾斜;
均值和标准差的耐抗性极小,异常值本身会对它们产生较大影响,四分位数具有一定的耐抗性,箱形图在识别异常值方面有一定的优越性。
箱形图更多用于多组数据的比较,相对直方图不仅节省了空间,还可以展示出许多直方图不能展示的信息。单组数据则更适合采用直方图,使可视化效果更加直观。
偏态(skewness)和峰度(Kurtosis):
偏度(Skewness):描述数据分布不对称的方向及其程度
在spss的Descriptives描述中有峰度系数和偏度系数, Sk=0,Ku=3时,分布呈正态,Sk>0时,分布呈正偏态,Sk<0时,分布呈负偏态,Ku>3时曲线比较陡峭,Ku<3时曲线比较平坦。由此可判断本数据分布是否为正态分布。
利用偏度和峰度进行正态性检验时,可以同时计算其相应的Z评分(Z-score),即:偏度Z-score=偏度值/标准误,峰度Z-score=峰度值/标准误。在α=0.05的检验水平下,若Z-score在±1.96之间,则可认为资料服从正态分布。
了解偏度和峰度这两个统计量的含义很重要,在对数据进行正态转换时,需要将其作为参考,选择合适的转换方法。
定义: 设
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X 1 , X 2 , . . . , X n
X
X
X
g
(
X
1
,
X
2
,
.
.
.
,
X
n
)
g(X_1,X_2,...,X_n)
g ( X 1 , X 2 , . . . , X n )
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X 1 , X 2 , . . . , X n
g
g
g
g
(
X
1
,
X
2
,
.
.
.
,
X
n
)
g(X_1,X_2,...,X_n)
g ( X 1 , X 2 , . . . , X n ) 统计量。
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X 1 , X 2 , . . . , X n
以下是常用的统计量:
1、样本平均值:
X
‾
=
1
n
∑
i
=
1
n
X
i
\overline{X}=\frac{1}{n}\sum_{i=1}^nX_i
X = n 1 i = 1 ∑ n X i
S
2
=
1
n
−
1
∑
i
=
1
n
(
X
i
−
X
‾
)
2
=
1
n
−
1
(
∑
i
=
1
n
X
i
2
−
n
X
‾
2
)
S^2=\frac{1}{n-1}\displaystyle\sum_{i=1}^n{(X_i-\overline X)^2}=\frac{1}{n-1}(\sum_{i=1}^nX_i^2-n\overline X^2)
S 2 = n − 1 1 i = 1 ∑ n ( X i − X ) 2 = n − 1 1 ( i = 1 ∑ n X i 2 − n X 2 )
S
=
S
2
S=\sqrt {S^2}
S = S 2
k
k
k
A
k
=
1
n
∑
i
=
1
n
X
i
k
,
k
=
1
,
2
,
.
.
.
A_k=\frac{1}{n}\sum_{i=1}^nX_i^k, k=1,2,...
A k = n 1 i = 1 ∑ n X i k , k = 1 , 2 , . . .
k
k
k
B
k
=
1
n
∑
i
=
1
n
(
X
i
−
X
‾
)
k
,
k
=
2
,
3
,
.
.
.
B_k=\frac{1}{n}\displaystyle\sum_{i=1}^n{(X_i-\overline X)^k}, k=2,3,...
B k = n 1 i = 1 ∑ n ( X i − X ) k , k = 2 , 3 , . . .
统计量的分布称为抽样分布。
χ
2
\chi^2
χ 2 χ \chi
设
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X 1 , X 2 , . . . , X n
N
(
0
,
1
)
N(0,1)
N ( 0 , 1 )
χ
2
=
X
1
2
+
X
2
2
+
.
.
.
+
X
n
2
\chi^2=X_1^2+X_2^2+...+X_n^2
χ 2 = X 1 2 + X 2 2 + . . . + X n 2
n
n
n
χ
2
\chi^2
χ 2
χ
2
∼
χ
2
(
n
)
\chi^2\sim\chi^2(n)
χ 2 ∼ χ 2 ( n )
χ
2
(
n
)
\chi^2(n)
χ 2 ( n )
f
(
y
)
=
{
1
2
n
/
2
Γ
(
n
/
2
)
y
n
/
2
−
1
e
−
y
/
2
 
y
>
0
c
 
其
他
f(y)=\begin{cases} \frac{1}{2^{n/2}\varGamma(n/2)}y^{n/2-1}e^{-y/2} &\, y>0\\ c &\, 其他 \end{cases}
f ( y ) = { 2 n / 2 Γ ( n / 2 ) 1 y n / 2 − 1 e − y / 2 c y > 0 其 他
χ
2
\chi^2
χ 2
E
(
χ
2
)
=
n
,
D
(
χ
2
)
=
2
n
E(\chi^2)=n, D(\chi^2)=2n
E ( χ 2 ) = n , D ( χ 2 ) = 2 n
χ
2
\chi^2
χ 2
χ
α
2
(
n
)
≈
1
2
(
z
α
+
2
n
−
1
)
2
\chi_\alpha^2(n) \approx \frac{1}{2}(z_\alpha+\sqrt{2n-1})^2
χ α 2 ( n ) ≈ 2 1 ( z α + 2 n − 1
) 2
z
α
z_\alpha
z α
α
\alpha
α
t
t
t 设
X
∼
N
(
0
,
1
)
,
Y
∼
χ
2
(
n
)
X\sim N(0,1), Y\sim \chi^2(n)
X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n )
X
,
Y
X,Y
X , Y
t
=
X
Y
/
n
t=\frac{X}{\sqrt{Y/n}}
t = Y / n
X
t
t
t
t
∼
t
(
n
)
t\sim t(n)
t ∼ t ( n )
t
t
t
t
(
n
)
t(n)
t ( n )
h
(
t
)
=
Γ
[
(
n
+
1
)
/
2
]
π
n
Γ
(
n
/
2
)
(
1
+
t
2
n
)
−
(
n
+
1
)
/
2
,
−
∞
<
t
<
∞
h(t)=\frac{\varGamma[(n+1)/2]}{\sqrt{\pi n}\varGamma(n/2)}(1+\frac{t^2}{n})^{-(n+1)/2}, -\infty<t<\infty
h ( t ) = π n
Γ ( n / 2 ) Γ [ ( n + 1 ) / 2 ] ( 1 + n t 2 ) − ( n + 1 ) / 2 , − ∞ < t < ∞
根据
Γ
\varGamma
Γ
lim
n
→
∞
h
(
t
)
=
1
2
π
e
−
t
2
/
2
\lim_{n \to \infty}h(t)=\frac{1}{\sqrt{2\pi}}e^{-t^2/2}
n → ∞ lim h ( t ) = 2 π
1 e − t 2 / 2
N
(
0
,
1
)
N(0,1)
N ( 0 , 1 )
F
F
F 设
U
∼
χ
2
(
n
1
)
,
V
∼
χ
2
(
n
2
)
,
U\sim \chi^2(n_1), V\sim \chi^2(n_2),
U ∼ χ 2 ( n 1 ) , V ∼ χ 2 ( n 2 ) ,
U
,
V
U,V
U , V
F
=
U
/
n
1
V
/
n
2
F=\frac{U/n1}{V/n2}
F = V / n 2 U / n 1
(
n
1
,
n
2
)
(n_1,n_2)
( n 1 , n 2 )
F
∼
F
(
n
1
,
n
2
)
F\sim F(n_1,n_2)
F ∼ F ( n 1 , n 2 )
若总体 X 有
E
(
X
)
=
μ
,
D
(
X
)
=
σ
2
E(X)=\mu, D(X)=\sigma^2
E ( X ) = μ , D ( X ) = σ 2
E
(
X
)
=
μ
,
D
(
X
)
=
σ
2
/
n
E(X)=\mu, D(X)=\sigma^2/n
E ( X ) = μ , D ( X ) = σ 2 / n
设
X
∼
N
(
μ
,
σ
2
)
X\sim N(\mu, \sigma^2)
X ∼ N ( μ , σ 2 )
X
‾
∼
N
(
μ
,
σ
2
/
n
)
\overline X\sim N(\mu, \sigma^2/n)
X ∼ N ( μ , σ 2 / n )
(
n
−
1
)
S
2
σ
2
∼
χ
2
(
n
−
1
)
\frac{(n-1)S^2}{\sigma^2}\sim \chi^2(n-1)
σ 2 ( n − 1 ) S 2 ∼ χ 2 ( n − 1 )
X
‾
,
S
2
\overline X, S^2
X , S 2
X
‾
−
μ
S
/
n
∼
t
(
n
−
1
)
\frac{\overline X-\mu}{S/{\sqrt n}} \sim t(n-1)
S / n
X − μ ∼ t ( n − 1 )
正态总体
X
∼
N
(
μ
1
,
σ
1
2
)
,
Y
∼
N
(
μ
2
,
σ
2
2
)
X\sim N(\mu_1, \sigma_1^2), Y\sim N(\mu_2, \sigma_2^2)
X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 )
数理统计研究有关对象的某一项数量指标,对该指标进行试验或观察,试验的全部可能的观察值称为总体,每个观察值称为个体。总体对应一个随机变量 X,个体是 X 的取值。
比如某灯泡寿命总体,某一年龄段的男性儿童身高总体。
对总体 X 进行 n 次重复、独立的观察,得到 n 个结果
X
1
,
X
2
,
.
.
.
,
X
n
X_1, X_2,...,X_n
X 1 , X 2 , . . . , X n
样本的函数称为统计量,比如样本均值,样本方差是两个最重要的统计量,统计量的分布称为抽样分布,
χ
2
,
t
,
F
\chi^2, t, F
χ 2 , t , F
要熟悉三大分布的定义,密度函数,和分为点。
统计推断的基本问题可以分为:估计问题,假设检验问题。
设总体 X 的分布函数
F
(
x
;
θ
)
F(x;\theta)
F ( x ; θ )
θ
\theta
θ
θ
^
(
X
1
,
X
2
,
.
.
.
,
X
n
)
\hat\theta(X_1, X_2, ..., X_n)
θ ^ ( X 1 , X 2 , . . . , X n )
θ
^
(
x
1
,
x
2
,
.
.
.
,
x
n
)
\hat\theta(x_1, x_2, ..., x_n)
θ ^ ( x 1 , x 2 , . . . , x n )
θ
\theta
θ
θ
^
(
X
1
,
X
2
,
.
.
.
,
X
n
)
\hat\theta(X_1, X_2, ..., X_n)
θ ^ ( X 1 , X 2 , . . . , X n )
θ
^
(
x
1
,
x
2
,
.
.
.
,
x
n
)
\hat\theta(x_1, x_2, ..., x_n)
θ ^ ( x 1 , x 2 , . . . , x n )
1、 矩估计法
以样本矩的连续函数作为相应的总体矩的连续函数的估计量。
2、 最大似然估计法
最大似然就是使取得当前的观察值的概率最大,确定最大似然估计量的问题可归结为微分学中的求最大值问题。
3、基于截尾样本的最大似然估计
所谓的截尾,在试验时,不可能得到完全样本,需要通过截尾试验来获取样本,比如定时截尾样本,定数截尾样本。
对于同一参数,不同的估计方法求出的估计量可能是不同的,原则上任何统计量都可以作为未知参数的估计量,那么采用哪一个估计量为好呢?这就涉及用什么样的标准来评估估计量的问题。
1、无偏性
对于未知参数
θ
\theta
θ
θ
\theta
θ
置信区间
正态总体均值与方差的区间估计:
。。。