0. 基本概念
实验(experiment)包括了步骤(procedures)、概率模型(model)、观察(observation)。
结果是实验中可能出现的结果(outcome)。
样本空间是实验所有可能结果的集合。(Sample Space)简称S。
事件代表的是对实验结果的某种描述,也可以看成是结果的集合,是样本空间的子集。
概率就是实验结果符合某事件描述的机会有多大。
事件空间的本质是set of set,样本空间属于事件空间。概率是个函数,是从事件空间到[0,1]的映射。
1. 概率计算
1.1 图解复杂概率问题
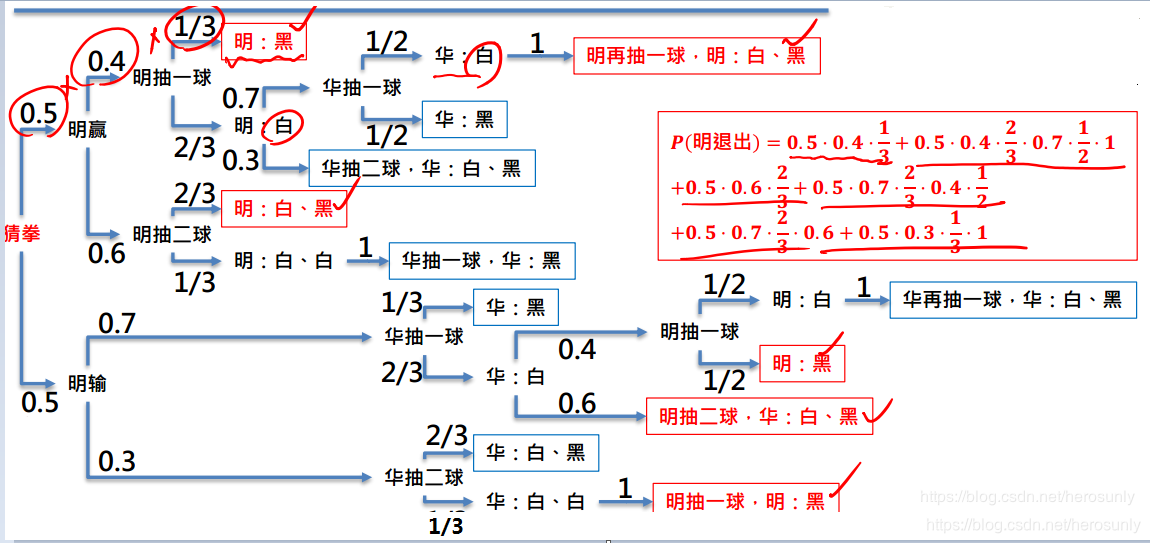
范例:兄弟情。明、华兄弟情笃。故决定一人放弃追求小美以免伤情谊。于罐中放入两白球、一黑球。游戏规则如下:猜拳决定谁先,之后轮流罐中取球;每次可取一至二球,直至有人抽中黑球为止(不放回取球)。抽中黑者退出追求。
已知猜拳输赢机率为0.5,每次明取球取一颗之机率为0.4,取两颗机率为0.6 。每次华取球取一颗之机率为0.7,取两颗机率为0.3。问最后小明退出追求之机率为?
2. 随机变量
随机变量不是变量,而是实验结果的函数。它是把实验结果进行数字化的函数。
2.1 随机变量的种类
随机变量分为离散型随机变量和连续性随机变量。离散型随机变量指的是随机变量的值是有限个或者可数的无穷多个。
2.1.1 可数和不可数
一个集合若是不可数的,这代表它包含的东西是无法可以一个个被数的。不管用什么方法数它里面的东西,它里面一定有一样东西是你没数到的!
第 N位数字定为“9 −第 N 个被数数字的第 N位数字
3. 概率论和数理统计的关系是什么?
概率论是数理统计的基础,而数理统计是概率论的应用。数理统计是通过采集数据、数据分析、得出尽可能正确的结论。其中数据分析指的是选择模型和参数估计。而选择模型和参数估计就会用到概率论。
3.1 为什么得到的是尽可能正确的结论
采集数据本质上是对总体进行采样,只有数据量解决无穷大才能得到正确的结论。而样本数量有限,就会使得结论有误差,但我们要得到尽可能正确的结论(前提是每个样本被采样的概率相等)。
得到结论后,我们需要对结论进行进一步判断,接受或者拒绝该结论。但可能会出现两个问题,以灯泡寿命问题为例,得到了样本平均值 ,将 和指定数 进行比较,从而接收或者拒绝这批灯泡。
但可能会出现两个问题,在进行假设检验时提出原假设和备择假设,原假设实际上是正确的,但我们做出的决定是拒绝原假设,此类错误称为第一类错误。原假设实际上是不正确的,但是我们却做出了接受原假设的决定,此类错误称为第二类错误。
4. 一维随机变量
4.1 离散型随机变量
设某事件A在一次试验中发生的概率为
,现把这个试验独立地重复
次,
为
次试验中
发生的次数,则
可取
等值。为确定其概率分布,考虑事件
。要这个事件发生,必须在这
次试验的原始记录
中,有 个 , 个 ,每个 有概率 ,而每个 有概率 。
5. 数学期望
设Z是随机变量X、Y的函数(g是连续函数)
,Z是一个一维随机变量,二维随机变量(X,Y)的概率密度为
,则有:
https://www.cc.gatech.edu/~hic/8803-Fall-09/Schedule.html
