版权声明:如需转载,请注明出处http://blog.csdn.net/a819825294 https://blog.csdn.net/a819825294/article/details/54376781
关键词:python、Keras、LSTM、Time-Series-Prediction
关于技术理论部分,可以参考这两篇文章(RNN、LSTM),本文主要从数据、代码角度,利用LSTM进行时间序列预测。
时间序列(或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。时间序列分析的主要目的是根据已有的历史数据对未来进行预测。
时间序列构成要素:长期趋势,季节变动,循环变动,不规则变动
- 长期趋势( T )现象在较长时期内受某种根本性因素作用而形成的总的变动趋势
- 季节变动( S )现象在一年内随着季节的变化而发生的有规律的周期性变动
- 循环变动( C )现象以若干年为周期所呈现出的波浪起伏形态的有规律的变动
- 不规则变动(I )是一种无规律可循的变动,包括严格的随机变动和不规则的突发性影响很大的变动两种类型
(1)原始时间序列数据(只列出了18行)
1455.219971
1399.420044
1402.109985
1403.449951
1441.469971
1457.599976
1438.560059
1432.25
1449.680054
1465.150024
1455.140015
1455.900024
1445.569946
1441.359985
1401.530029
1410.030029
1404.089966
1398.560059(2)处理数据使之符合LSTM的要求
为了更加直观的了解数据格式,代码中加入了一些打印(print),并且后面加了注释,就是输出值
def load_data(filename, seq_len):
f = open(filename, 'rb').read()
data = f.split('\n')
print('data len:',len(data)) #4172
print('sequence len:',seq_len) #50
sequence_length = seq_len + 1
result = []
for index in range(len(data) - sequence_length):
result.append(data[index: index + sequence_length]) #得到长度为seq_len+1的向量,最后一个作为label
print('result len:',len(result)) #4121
print('result shape:',np.array(result).shape) #(4121,51)
result = np.array(result)
#划分train、test
row = round(0.9 * result.shape[0])
train = result[:row, :]
np.random.shuffle(train)
x_train = train[:, :-1]
y_train = train[:, -1]
x_test = result[row:, :-1]
y_test = result[row:, -1]
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
print('X_train shape:',X_train.shape) #(3709L, 50L, 1L)
print('y_train shape:',y_train.shape) #(3709L,)
print('X_test shape:',X_test.shape) #(412L, 50L, 1L)
print('y_test shape:',y_test.shape) #(412L,)
return [x_train, y_train, x_test, y_test](3)LSTM模型
本文使用的是keras深度学习框架,读者可能用的是其他的,诸如theano、tensorflow等,大同小异。
LSTM的结构可以自己定制,Stack LSTM or Bidirectional LSTM
def build_model(layers): #layers [1,50,100,1]
model = Sequential()
#Stack LSTM
model.add(LSTM(input_dim=layers[0],output_dim=layers[1],return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(layers[2],return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(output_dim=layers[3]))
model.add(Activation("linear"))
start = time.time()
model.compile(loss="mse", optimizer="rmsprop")
print("Compilation Time : ", time.time() - start)
return model(4)LSTM训练预测
1.直接预测
def predict_point_by_point(model, data):
predicted = model.predict(data)
print('predicted shape:',np.array(predicted).shape) #(412L,1L)
predicted = np.reshape(predicted, (predicted.size,))
return predicted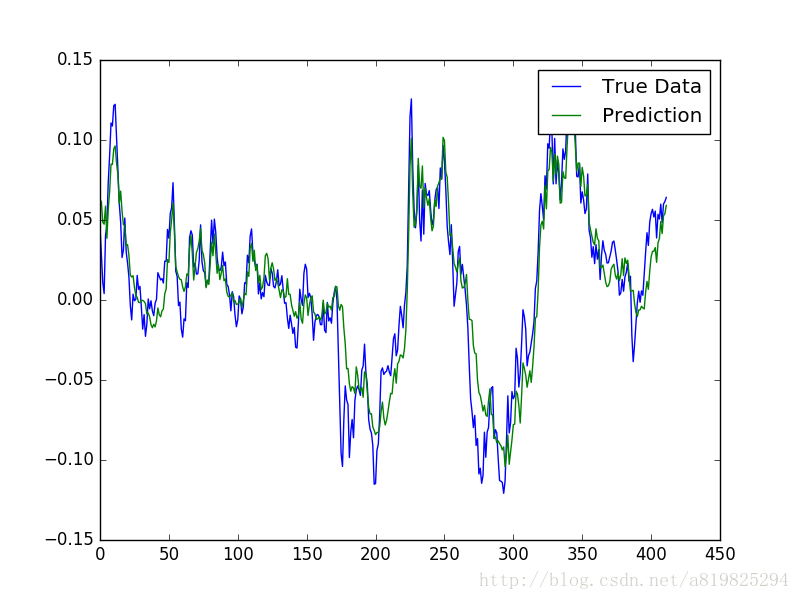
2.滚动预测
def predict_sequence_full(model, data, window_size): #data X_test
curr_frame = data[0] #(50L,1L)
predicted = []
for i in xrange(len(data)):
#x = np.array([[[1],[2],[3]], [[4],[5],[6]]]) x.shape (2, 3, 1) x[0,0] = array([1]) x[:,np.newaxis,:,:].shape (2, 1, 3, 1)
predicted.append(model.predict(curr_frame[newaxis,:,:])[0,0]) #np.array(curr_frame[newaxis,:,:]).shape (1L,50L,1L)
curr_frame = curr_frame[1:]
curr_frame = np.insert(curr_frame, [window_size-1], predicted[-1], axis=0) #numpy.insert(arr, obj, values, axis=None)
return predicted
2.滑动窗口+滚动预测
def predict_sequences_multiple(model, data, window_size, prediction_len): #window_size = seq_len
prediction_seqs = []
for i in xrange(len(data)/prediction_len):
curr_frame = data[i*prediction_len]
predicted = []
for j in xrange(prediction_len):
predicted.append(model.predict(curr_frame[newaxis,:,:])[0,0])
curr_frame = curr_frame[1:]
curr_frame = np.insert(curr_frame, [window_size-1], predicted[-1], axis=0)
prediction_seqs.append(predicted)
return prediction_seqs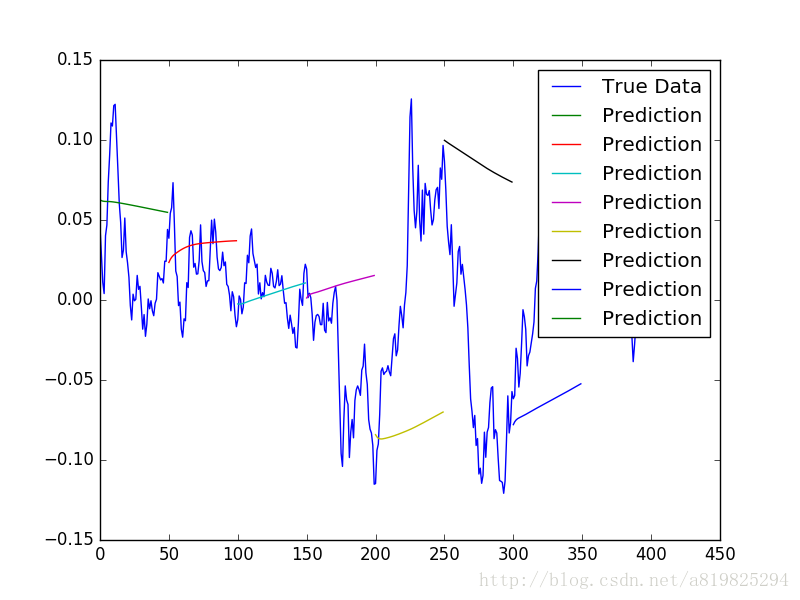
(5)完整代码
# -*- coding: utf-8 -*-
from __future__ import print_function
import time
import warnings
import numpy as np
import time
import matplotlib.pyplot as plt
from numpy import newaxis
from keras.layers.core import Dense, Activation, Dropout
from keras.layers.recurrent import LSTM
from keras.models import Sequential
warnings.filterwarnings("ignore")
def load_data(filename, seq_len, normalise_window):
f = open(filename, 'rb').read()
data = f.split('\n')
print('data len:',len(data))
print('sequence len:',seq_len)
sequence_length = seq_len + 1
result = []
for index in range(len(data) - sequence_length):
result.append(data[index: index + sequence_length]) #得到长度为seq_len+1的向量,最后一个作为label
print('result len:',len(result))
print('result shape:',np.array(result).shape)
print(result[:1])
if normalise_window:
result = normalise_windows(result)
print(result[:1])
print('normalise_windows result shape:',np.array(result).shape)
result = np.array(result)
#划分train、test
row = round(0.9 * result.shape[0])
train = result[:row, :]
np.random.shuffle(train)
x_train = train[:, :-1]
y_train = train[:, -1]
x_test = result[row:, :-1]
y_test = result[row:, -1]
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
return [x_train, y_train, x_test, y_test]
def normalise_windows(window_data):
normalised_data = []
for window in window_data: #window shape (sequence_length L ,) 即(51L,)
normalised_window = [((float(p) / float(window[0])) - 1) for p in window]
normalised_data.append(normalised_window)
return normalised_data
def build_model(layers): #layers [1,50,100,1]
model = Sequential()
model.add(LSTM(input_dim=layers[0],output_dim=layers[1],return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(layers[2],return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(output_dim=layers[3]))
model.add(Activation("linear"))
start = time.time()
model.compile(loss="mse", optimizer="rmsprop")
print("Compilation Time : ", time.time() - start)
return model
#直接全部预测
def predict_point_by_point(model, data):
predicted = model.predict(data)
print('predicted shape:',np.array(predicted).shape) #(412L,1L)
predicted = np.reshape(predicted, (predicted.size,))
return predicted
#滚动预测
def predict_sequence_full(model, data, window_size): #data X_test
curr_frame = data[0] #(50L,1L)
predicted = []
for i in xrange(len(data)):
#x = np.array([[[1],[2],[3]], [[4],[5],[6]]]) x.shape (2, 3, 1) x[0,0] = array([1]) x[:,np.newaxis,:,:].shape (2, 1, 3, 1)
predicted.append(model.predict(curr_frame[newaxis,:,:])[0,0]) #np.array(curr_frame[newaxis,:,:]).shape (1L,50L,1L)
curr_frame = curr_frame[1:]
curr_frame = np.insert(curr_frame, [window_size-1], predicted[-1], axis=0) #numpy.insert(arr, obj, values, axis=None)
return predicted
def predict_sequences_multiple(model, data, window_size, prediction_len): #window_size = seq_len
prediction_seqs = []
for i in xrange(len(data)/prediction_len):
curr_frame = data[i*prediction_len]
predicted = []
for j in xrange(prediction_len):
predicted.append(model.predict(curr_frame[newaxis,:,:])[0,0])
curr_frame = curr_frame[1:]
curr_frame = np.insert(curr_frame, [window_size-1], predicted[-1], axis=0)
prediction_seqs.append(predicted)
return prediction_seqs
def plot_results(predicted_data, true_data, filename):
fig = plt.figure(facecolor='white')
ax = fig.add_subplot(111)
ax.plot(true_data, label='True Data')
plt.plot(predicted_data, label='Prediction')
plt.legend()
plt.show()
plt.savefig(filename+'.png')
def plot_results_multiple(predicted_data, true_data, prediction_len):
fig = plt.figure(facecolor='white')
ax = fig.add_subplot(111)
ax.plot(true_data, label='True Data')
#Pad the list of predictions to shift it in the graph to it's correct start
for i, data in enumerate(predicted_data):
padding = [None for p in xrange(i * prediction_len)]
plt.plot(padding + data, label='Prediction')
plt.legend()
plt.show()
plt.savefig('plot_results_multiple.png')
if __name__=='__main__':
global_start_time = time.time()
epochs = 1
seq_len = 50
print('> Loading data... ')
X_train, y_train, X_test, y_test = load_data('sp500.csv', seq_len, True)
print('X_train shape:',X_train.shape) #(3709L, 50L, 1L)
print('y_train shape:',y_train.shape) #(3709L,)
print('X_test shape:',X_test.shape) #(412L, 50L, 1L)
print('y_test shape:',y_test.shape) #(412L,)
print('> Data Loaded. Compiling...')
model = build_model([1, 50, 100, 1])
model.fit(X_train,y_train,batch_size=512,nb_epoch=epochs,validation_split=0.05)
multiple_predictions = predict_sequences_multiple(model, X_test, seq_len, prediction_len=50)
print('multiple_predictions shape:',np.array(multiple_predictions).shape) #(8L,50L)
full_predictions = predict_sequence_full(model, X_test, seq_len)
print('full_predictions shape:',np.array(full_predictions).shape) #(412L,)
point_by_point_predictions = predict_point_by_point(model, X_test)
print('point_by_point_predictions shape:',np.array(point_by_point_predictions).shape) #(412L)
print('Training duration (s) : ', time.time() - global_start_time)
plot_results_multiple(multiple_predictions, y_test, 50)
plot_results(full_predictions,y_test,'full_predictions')
plot_results(point_by_point_predictions,y_test,'point_by_point_predictions')参考文献
(1)https://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction