版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/duan20140614/article/details/88751165
上篇文章中我们提到了代价函数
,并期望使它最小化,那代价函数长什么样子呢?
接下来,我们将给大家一个直观的感受,看看参数
取不同值时,
的几何呈现
我们可以把训练集中的样本 想象成分散在xy平面上的点,然后通过一条直线来拟合这些点,这条直线就是我们的假设函数 ,这里我们令 ,看 随 的变化情况
(1). 当
,
和
的几何意义分别如下:
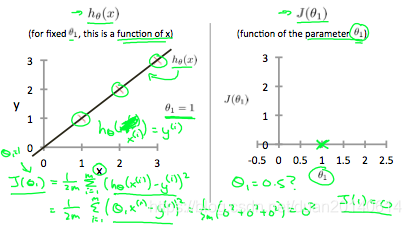
从上图右可以看出,当
,代价函数的值(绿叉表示的点)
(2). 当
,
和
的几何意义分别如下:
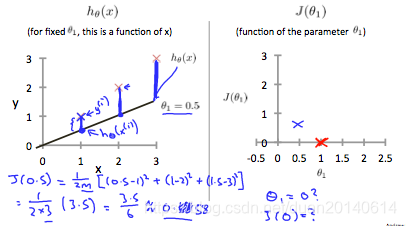
从上图右可以看出,当
时,代价函数的值(蓝叉表示的点)
,增加了0.58。
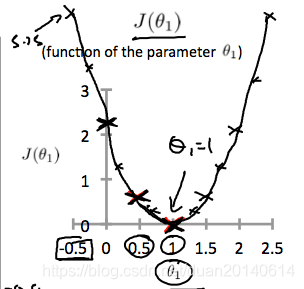
(3). 我们把
一些可能的取值画出来,就形成了以下曲线: