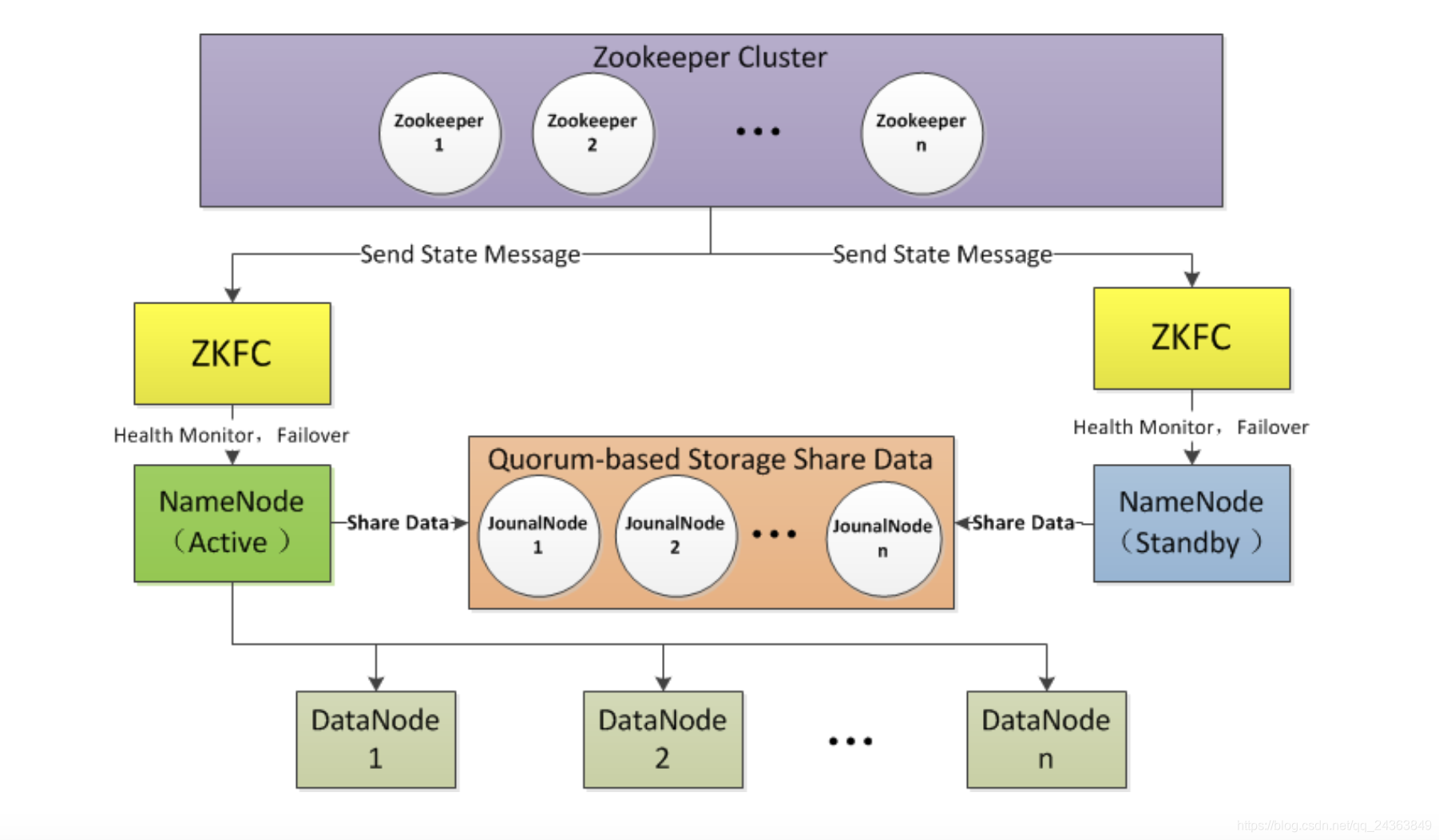
Hadoop HA(3台)
HDFS HA
NameNode
NameNode(standby)替换了单节点伪分布式的SNN
HA中不再有SNN,而是多了一个NN节点(standby),弥补了SNNcheckpoint的不足
NN节点挂了,就不能提供对外服务
两个NN节点(实时的,任何时刻只有1台active对外,
另外一台是standby 实时备份
进行ls cat等操作时,NameNode(active)会自己写一份editlog,同时jounalNode也会保存一份
同时接收JN集群的日志,显示读取执行log操作(***重演***),使得自己的元数据和NameNode(active)节点保持一致。
DataNode
DataNode需要向NameNode(active)和NameNode(standby)同时发送心跳信息以及blockreport
jounalNode
主要用于NameNode(active)和NameNode(standby)同步数据
负责接受NameNode(active)的editlogs
(数目一般也是取2n+1,具体数目因HDFS请求量以及数据量而定)
ZKFC(in HDFS HA)(zookeeper failover control)
***单独的进程***
监控NameNode的健康状况
向ZK集群报告心跳信息,以便被选举
当自己被选举为active时,zkfc进程通过RPC协议调用使NN节点的状态变为active
和NameNode同节点
当有多台节点时
hadoop fs -ls hdfs://ip1:9000/
hadoop fs -ls hdfs://ip2:9000/
hadoop001: ZK NN ZKFC JN DN
hadoop002: ZK NN ZKFC JN DN
hadoop003: ZK JN DN
ZK节点并非越多越好,太多的话, 投票选举消耗时间太多。并且ZK的数量一般为2n+1(奇数)个,避免投票出现平票情况
如果节点数量足够大,几百台这种规模,直接搞一台机器部署ZOOKEEPER
架构图如下所示:
YARN HA
ResourceManager(ZKFC(in YARN 线程))
1.启动的时候会向ZK的/rmstore目录写lock文件,如果写成功即为active,否则为standby。RM节点的ZKFC进程会一直监控lock文件是否存在,假如不存在,就为active,如果存在,就为standby。
2.接受Client端的请求,接受和监控NM的资源状况的汇报,负载资源和分配调度。
3.启动和监控ApplicationMaster on NameNode的container
NodeManager
节点资源的管理
启动容器运行task就算
上报资源
ZKFC(in YARN 线程)
hadoop001:ZK RM(ZKFC) NM
hadoop002:ZK RM(ZKFC) NM
hadoop003:ZK NM
RMStateStore
存储在ZK的/rmstore目录
1.RM(active)会向这个目录写APP信息
2.当RM(active)故障,另一个RM(standby)通过ZKFC选举成功为active,会从/rmstore读取相应的作业信息
重新构造作业的内存信息,启动内部的服务,开始接受NM的心跳。构建集群资源信息,并且接受客户端作业提交请求。
